Diffusion
可以先了解一下Diffusion模型的历史 Diffusion model|扩散模型的历史 总的来说,第一个流行可用的Diffusion模型是在2020年提出的,所以现在学也不算太晚。
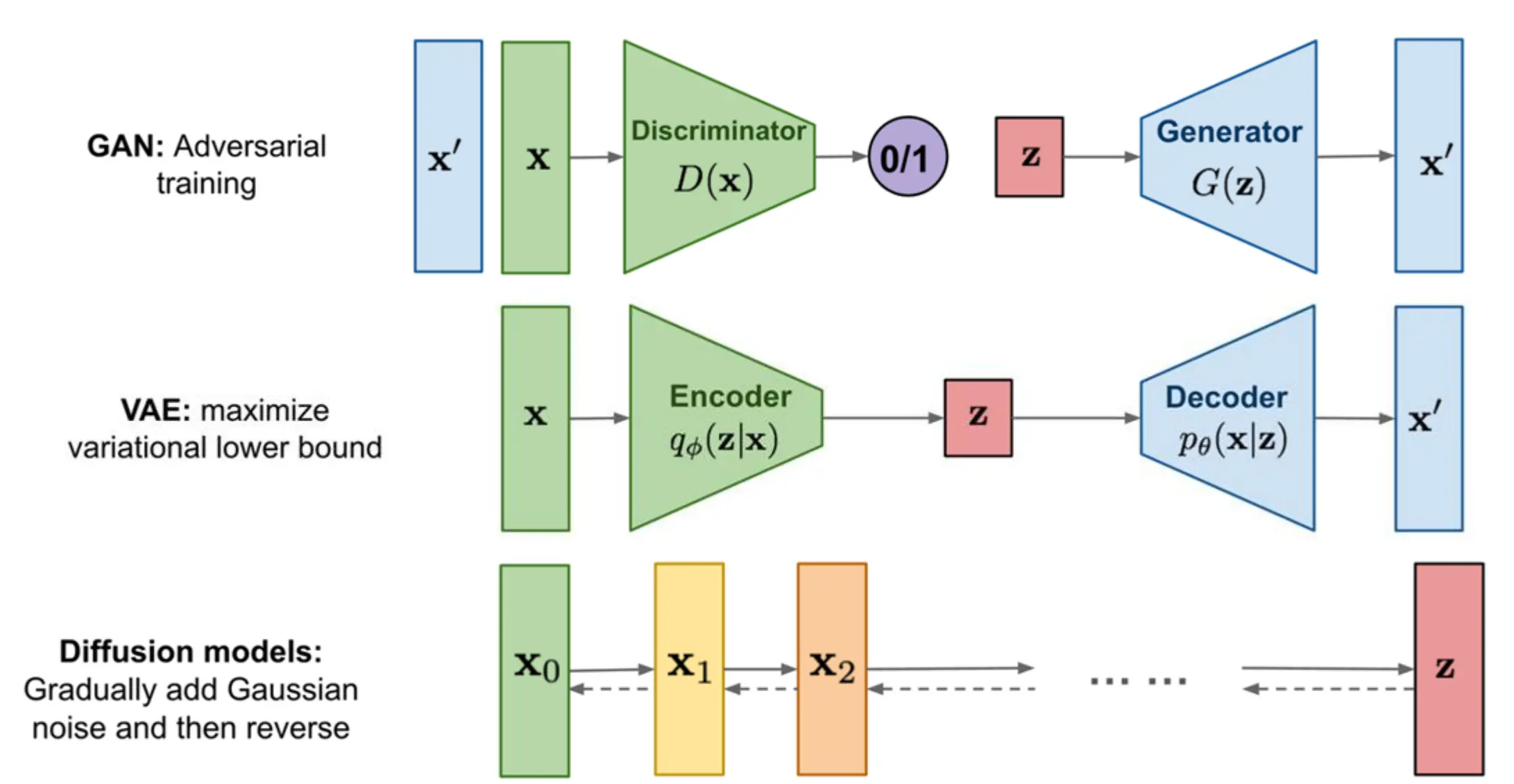
生成模型的种类
- Latent Variable Models
- VAE,GAN
- 学习一个“潜在空间”,再通过解码器从潜在空间生成样本。
- Diffusion Models
- 定义一个带噪声的马尔可夫链,将数据逐步“噪声化”至纯高斯噪声,再学习反向去噪过程一步步恢复数据。
- Autoregressive Models
- 把联合分布 p(x₁, x₂, …, xₙ) 分解为 p(x₁)·p(x₂|x₁)·…·p(xₙ|x₁:ₙ₋₁),逐维/逐步生成。
DDPM(Denoising diffusion probabilistic model)
什么叫Diffusion?  DDPM一般包含两个过程:
DDPM一般包含两个过程:
- 前向传播,给原本的东西加噪音,从真实样本中采样一个图片,通过diffusion
来添加噪音 - 反向去噪,学习denoising过程从而减少噪音。从
中采样噪音,学习去噪的过程。 - 通过CNN来产生一个more denoised 图片根据一个noised图片

- 通过CNN来产生一个more denoised 图片根据一个noised图片
符号规定:
- p(x)表示真实数据的未知分布
- q(xt | xt-1)表示加噪音过程条件分布
- q(x|y)表示在已知y时x的条件概率分布
- N(0,I)标准多元正态分布
- N(x;μ,σI) 等价于 𝑥∼𝑁(𝜇,𝜎𝐼),正态分布中生成一个样本 x
前向过程
 我们需要scaling,因为我们想让原图和噪音的方差平衡。
我们需要scaling,因为我们想让原图和噪音的方差平衡。
beta远小于1意味着“每步只加一点点噪声”,确保了正向扩散的平滑性和数值稳定性。
如果我们想要一次性得到x0到xt,有这样的公式:
其中
如果这玩意趋近于0,那么当t=T时,得到的基本上就是纯白噪音。 根据重参数化采样,我们有:
也就是说,我们如果想要得到xt ~ q(xt),我们只能通过x0 ~ q(x0)然后通过xt ~ q(xt|x0)来得到。
反向去噪过程
理想状态下,我们的去噪音过程应该是: 首先从纯白噪音中采样xT
然后逐渐使用q(xt-1|xt)来算出x0
然而,我们知道,这个q(xt-1 | xt)是很棘手的,很难精确得到。但是,我们可以用一个高斯分布来近似它,并把均值和方差交给神经网络去学习。
这种方法的合理性来源于,当正向噪声步长beta很小时,真实后验也近似高斯,因而这种拟合非常有效。。
怎么训练呢?随机采一对(x0, xt),(用前向闭式公式一步到位加噪),然后让网络去预测“噪声残差”或直接预测mu。 这个用来学习的网络是Unet,它不会显式地预测mu sigma,而是输入一个带噪音的xt以及t,输出噪声残差预测或者对干净图x0的直接预测。 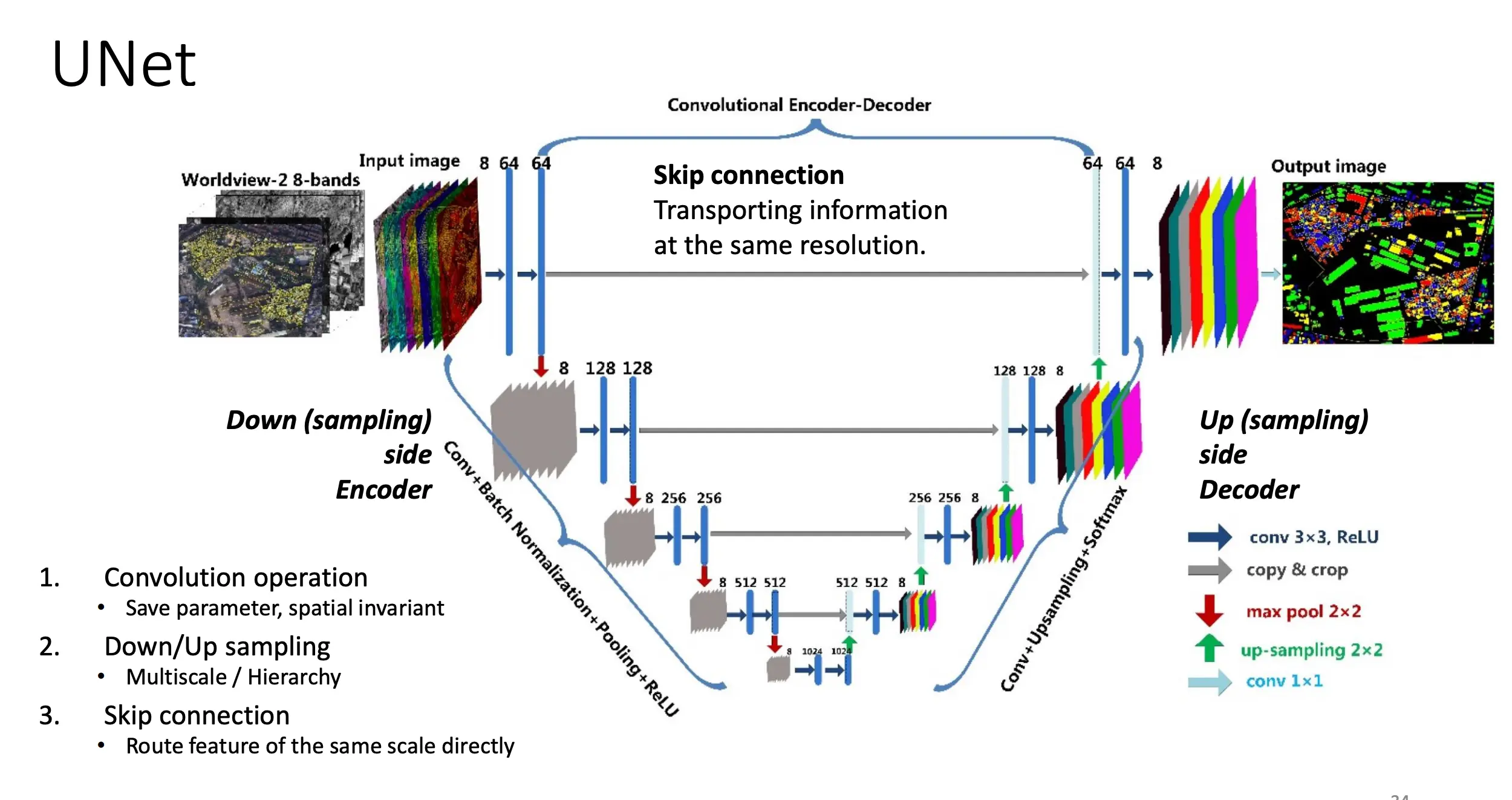
网络过程

如何采样(生成新图)呢? 
生成模型的不可能三角
 GAN高质量,快速(一步生成),容易模式崩溃,欠缺多样性 VAE多样性,快速,样本质量一般,往往有模糊或失真 扩散模型高质量,多样性但采样慢。
GAN高质量,快速(一步生成),容易模式崩溃,欠缺多样性 VAE多样性,快速,样本质量一般,往往有模糊或失真 扩散模型高质量,多样性但采样慢。
Conditional Diffusion
原本无条件的逆向去噪音是:
加上条件之后,就变成了:
均值和方差都由模型学出来的。这样采样时,每一步都会“参考”ccc 来决定去噪的方向和强度。 条件可以有这么几类:
- 标量条件(Scalar conditioning):类别 ID、数值属性,一般映射成一个向量,再在网络的不同层与时间步嵌入相加,- - 或者通过 FiLM(Feature-wise Linear Modulation) 做通道层的缩放与偏置。
- 图像条件(Image conditioning):低分辨率图等,把条件图作为额外的通道,与xt在最开始拼通道(concatenate channel-wise),让 UNet 的第一层同时“看到”噪声图和条件图。
- 文本条件(Text conditioning),prompt,先用 CLIP、Transformer 等模型把文本编码成一组向量(text embedding),然后在 UNet 的中间层通过Cross-Attention(跨注意力)机制,让图像特征去“查询”文本 embedding,从而在去噪过程中关注到文本提示的语义。
应用
超分辨率
y是低分辨率,x是高分辨率。 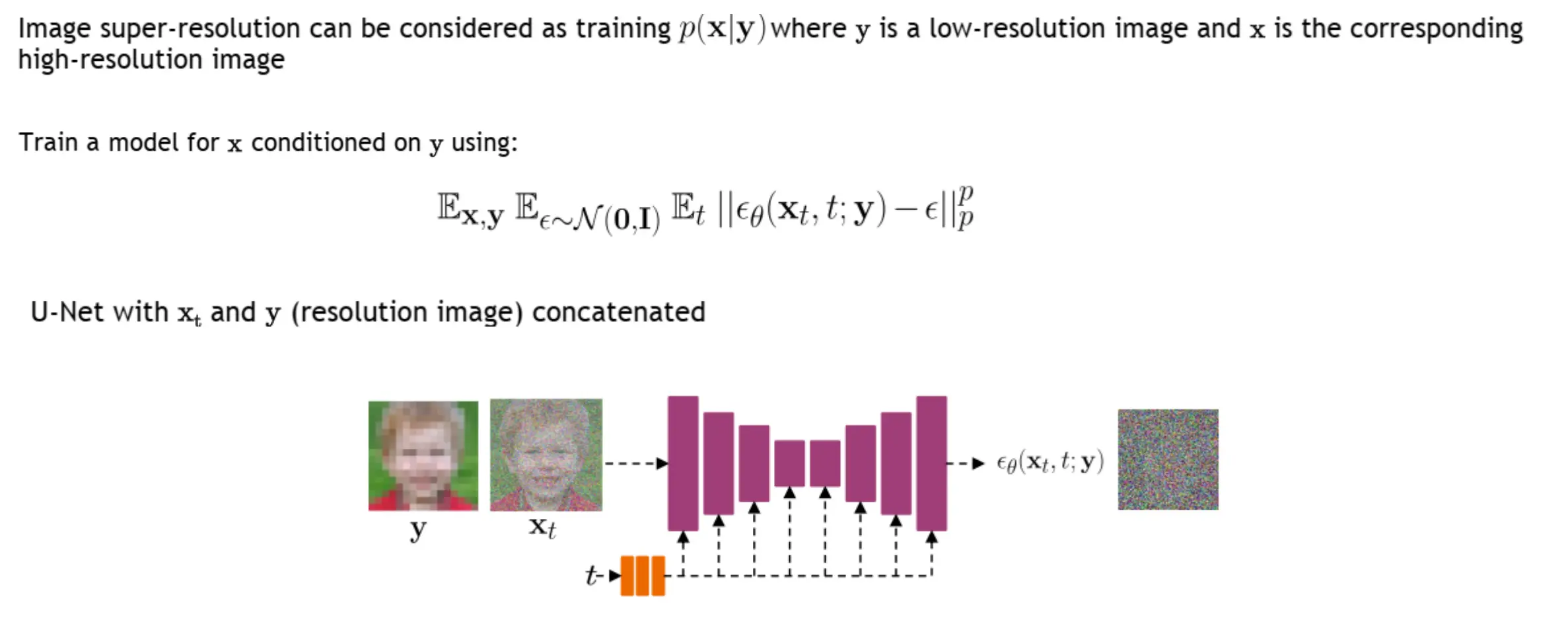
级联diffusion
 第一个扩散模型只负责“画个大概轮廓”,第二个模型接手,把这张小图 放大到 64×64,同时补足更多细节和纹理,最后一个模型再把 64×64 放大到 256×256,进行最后的细节修饰:毛发丝理、背景虚化、光影效果……
第一个扩散模型只负责“画个大概轮廓”,第二个模型接手,把这张小图 放大到 64×64,同时补足更多细节和纹理,最后一个模型再把 64×64 放大到 256×256,进行最后的细节修饰:毛发丝理、背景虚化、光影效果……
低分辨率阶段专注学“哪儿有头哪儿有尾”,分辨率阶段专注学“如何写好每根毛发”。如果直接训练一个 256×256 的扩散模型,训练和采样代价都非常高;
图到图

Stable Diffusion
 在低维的隐空间做diffusion
在低维的隐空间做diffusion
这是带条件的Stable Diffusion 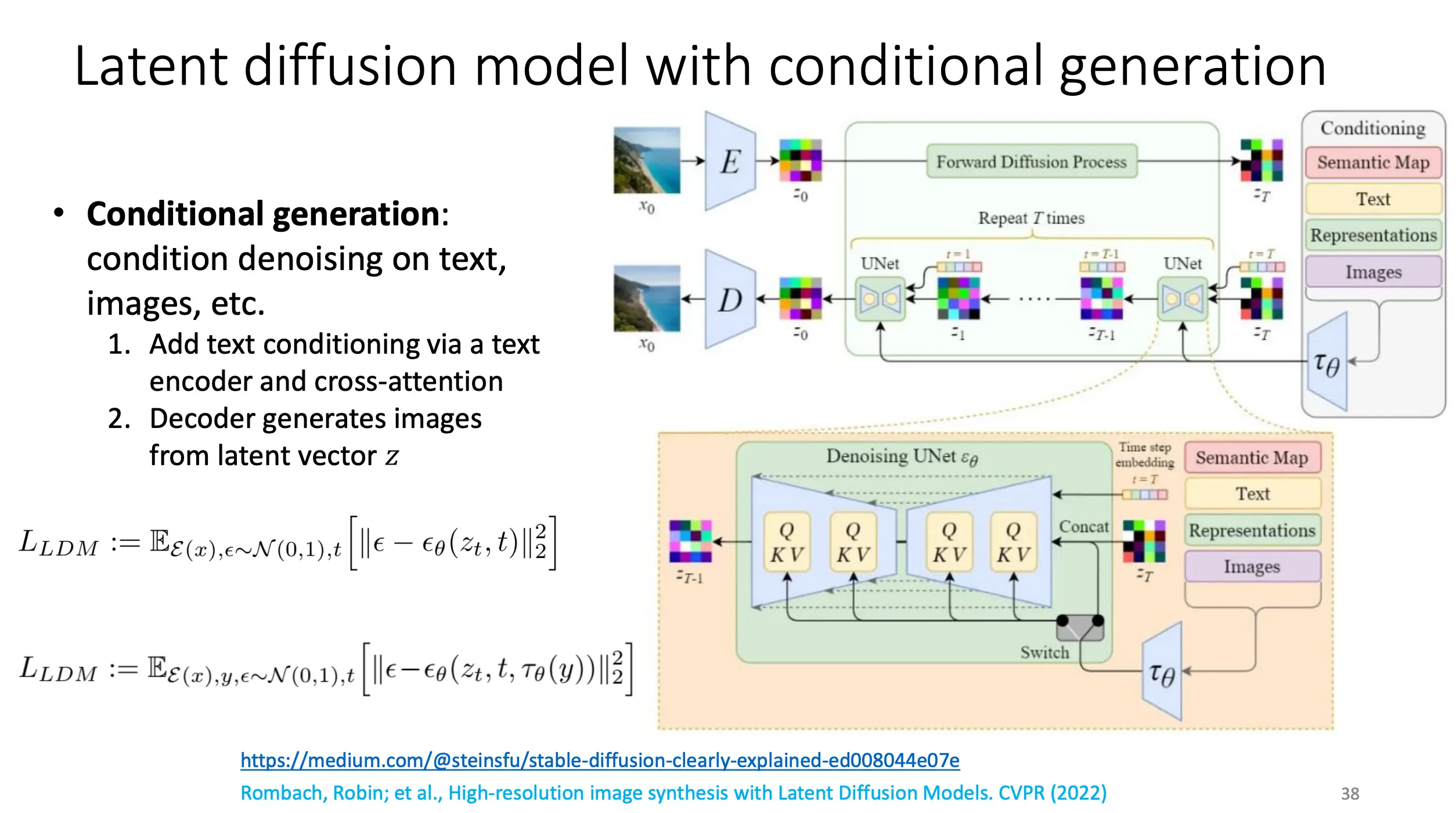
 Larry Shi
Larry Shi