Dependency Parsing
语义学基础
当我们谈论一个句子的时候,有两种分析方式,
- 一种叫Constituency成分结构,也叫phrase structure grammar短语结构语法,也叫context-free grammars (CFGs) 上下文无关文法
- 另一种叫Dependency structure依赖关系结构 接下来就来介绍这两种分析方式
CFGs
CFG的视角认为,句子是由一个一个phrase短语组成的,而短语是由单词words组成的,所以一个句子可以被分为一个一个短语之后,再把短语分为单词,这是一种nested结构。 基本单词:the、cat、a、dog、large、barking 多个单词嵌套在一起组合成短语,例如:the cat、a large dog 短语可以嵌套在更大的短语中。 the large barking dog,这个短语是由多个部分组成的,里面包含冠词 the,形容词 large,动词形容词 barking,以及名词 dog。你可以看到这种结构包含了修饰关系,是层次化的,其中 large barking 修饰 dog,而整个短语再与冠词 the 组合。
Dependency structure
举个例子  如果我们不确定
如果我们不确定from space 这个短语是依赖于whales 还是 scientists 的,我们就没法得到正确的语义,依赖结构就表明了这种关系。 依赖结构的观点认为,语言的结构是一个这样的树结构,箭头通常用于表示语法关系(主语、介词宾语、同位语等):
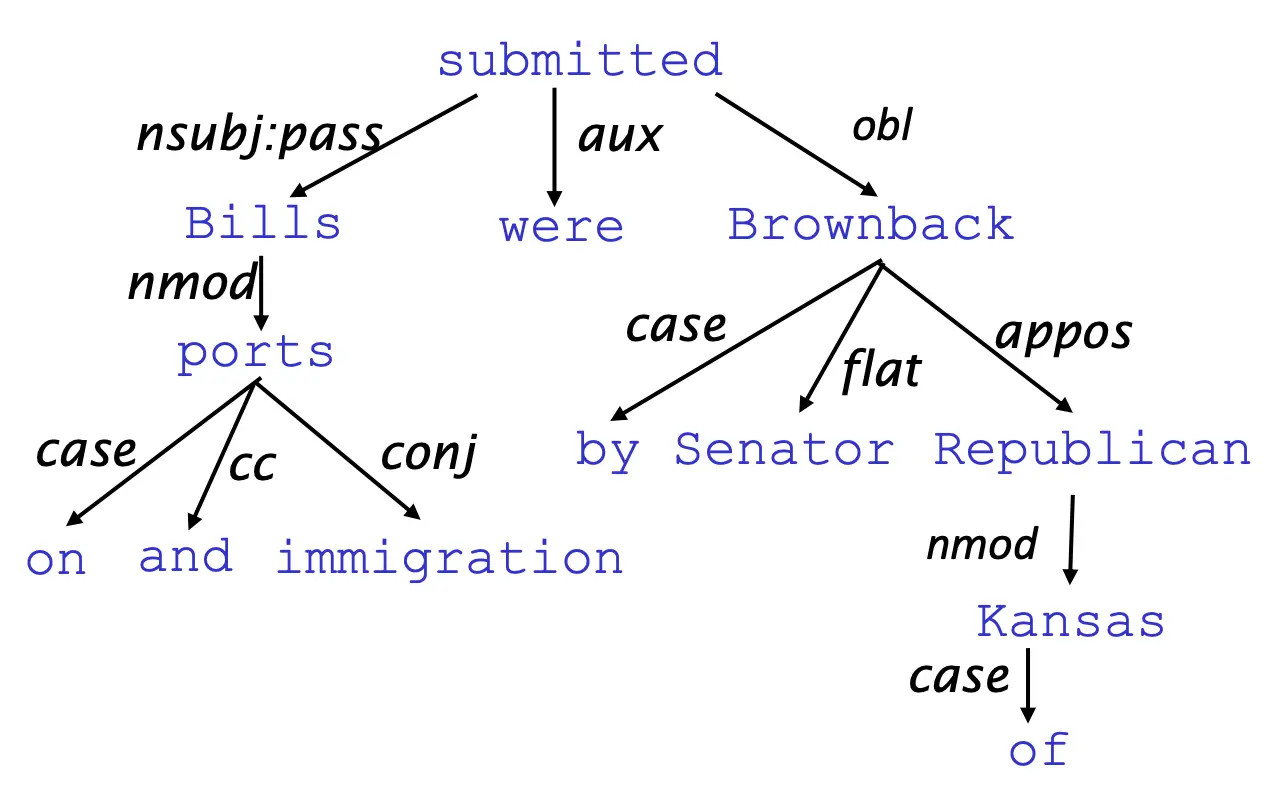 依存语法大概用这种方法分析一个句子
依存语法大概用这种方法分析一个句子
 逐渐也诞生了一些依存树数据库,比如Brown corpus (1967; PoS tagged 1979); Lancaster-IBM Treebank (starting late 1980s); Marcus et al. 1993, The Penn Treebank, Computational Linguistics; Universal Dependencies: http://universaldependencies.org/
逐渐也诞生了一些依存树数据库,比如Brown corpus (1967; PoS tagged 1979); Lancaster-IBM Treebank (starting late 1980s); Marcus et al. 1993, The Penn Treebank, Computational Linguistics; Universal Dependencies: http://universaldependencies.org/
帮助确定是否存在依存关系一般有四条经验
- 双词关系(Bilexical affinities)
discussion(讨论)与issues(问题)之间的依存关系是合理的,这意味着这两个词常常一起出现,且有明确的语义关系。在语法解析中,这种双词之间的相互联系可以用来判断是否有依存关系。 - 依存距离(Dependency distance)依存距离是指依存关系中的两个单词之间的距离。通常,依存关系更可能发生在相邻或距离较近的单词之间。
- 中间的干扰项(Intervening material)依存关系很少会跨越干扰动词或标点符号。也就是说,如果两个词之间有很多动词或标点符号,它们之间可能不太会存在直接的依存关系。
- 依存中心词的容量(Valency of heads)中心词的容量,或称为“配价”,是指一个中心词(通常是动词或名词)能够接受多少个依存项(比如宾语、状语等)。配价描述了一个中心词通常会有多少依存从属词,以及这些从属词通常处于哪个方向(左边还是右边)。
Dependency Parsing
有了上面的依存结构的基础,我们就想要给一个句子做dependency parsing. 在parse的时候,要有一些constrain
- 只能有一个root
- 不要出现环
- 是否能出现箭头交叉(能交叉就是non-projective) 常用的parser分类有以下几种:
- 动态规划:通过动态编程来提高依存解析的效率,经典算法如 Eisner 算法。O(n³)
- Graph-based图算法:将解析视为图中的最小生成树问题,使用机器学习方法对依存关系进行评分。
- 约束满足:应用严格的语法约束来消除不可能的依存边。
- Transition-based Parser基于转换的解析:通过机器学习分类器和贪婪策略快速、有效地建立依存结构。
接下来我们主要聊一下第四种,通过机器学习和贪婪策略建立依存结构。
Transition-based Parser
Nivre 2003 这个方法中,一个parser对象包含了什么呢?
- 一个stack σ,top在右侧,starts with the ROOT symbol
- 一个buffer β,top在左边,starts with the input sentence
- 一个用于记录边关系的A,一开始是空的
- 一系列actions
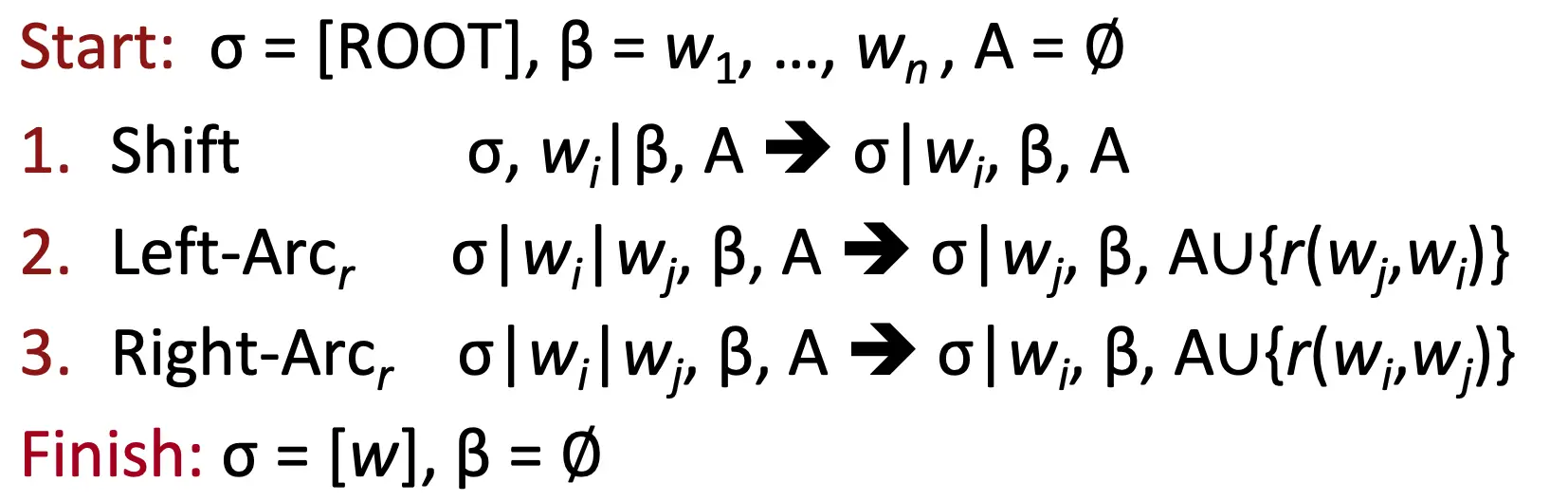
那么怎么用呢?就像下面这样parse。
一个细节需要注意
注意,这这里面,parser自动选择了正确的做法,也就是说,每当要选择shift,左弧还是右弧的时候,parser自己就选对了,但是怎么选对的呢?应当由parser自己来决定。这个过程在后面会用机器学习的方法解决(MaltParser)。
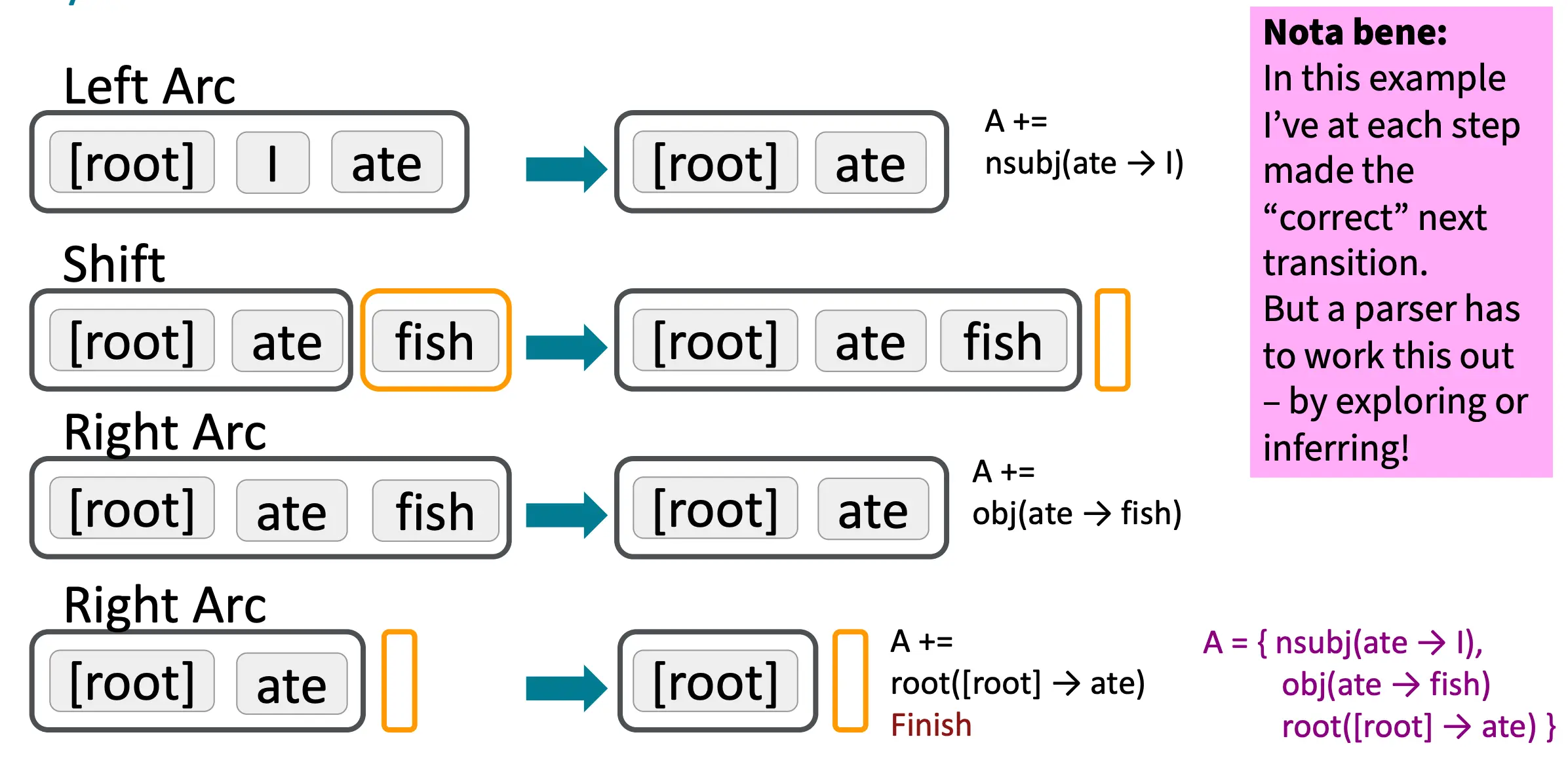
MaltParser: 使用机器学习做出正确action决定
其实当要做出决策的时候,就是做一个分类,看分为shift, left arc还是right arc,所以我们只要训练一个分类器就可以了。
那么当你面对一个词还有缓冲区的词都时候,你可以给出多少种关系呢?2*|R| + 1。 |R|是你关系的总数。比如,主-谓,动-宾,修-名,那么由于关系是有向的,所以可以安2 * |R|。剩下的1就是不形成任何关系,就是移一下。 换一个视角,就是,你是否要对两个词形成一条边。如果不形成,就是1,如果形成,由于是有向边你就可以有2R种。
而这个分类器的输入是什么呢? 很玄学,是一些专家规定的特征。这些特征用于帮助分类器判断应该如何建立依存关系。
- 栈顶单词和它的词性(POS)。
- 缓冲区中第一个单词及其词性(POS)。
- 前一对的解析结果。
- etc
在vanilla maltparser中,我们贪婪的选择最好的,不进行搜索。 但如果想要得到更好的解析,可以用beam search。也就是说,每次保留前k个最好的解析,这样可以提高准确性
优点:非常快速的线性时间解析(Linear Time Parsing),并且具有较高的准确性。例如网页解析。
做好解析后,评估一般有两个指标,UAS也就是只看剪头指向不看具体词性是什么。LAS就是要带上词性的。 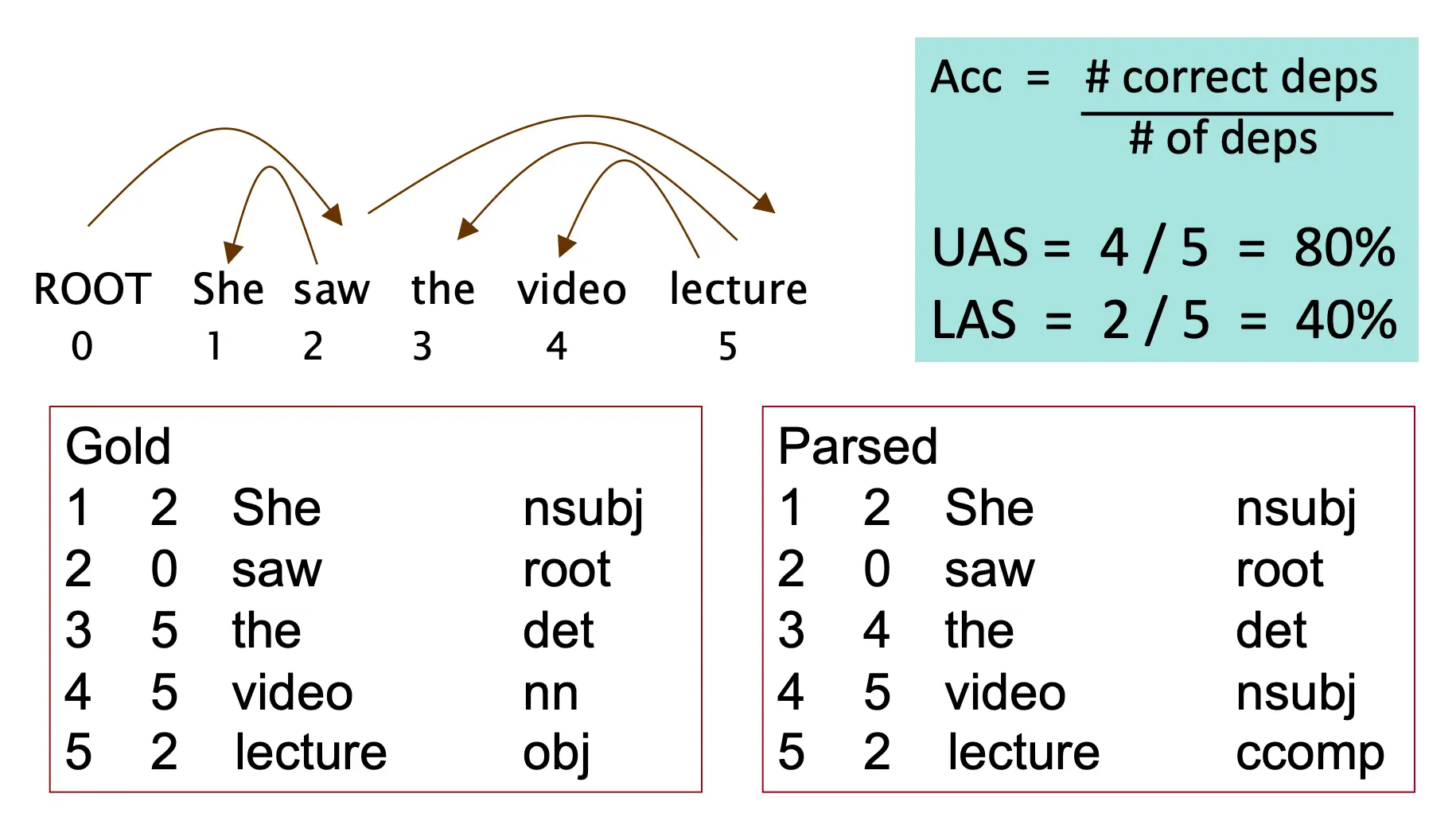
和LLM做费曼学习法时的记录
MaltParser其实还是一种transition-based dependency parser的辅助方法,其中用到了机器学习。具体来说,堆栈,缓冲区,以及left arc, right arc等操作都是在transition parser里面定义的。MaltParser的精髓在于,根据专家经验设计一套indicator features, 比如说 规则1: 这个词是名词 规则2: 这个词左边的词是助动词 ..... 这样,会产生比如说100个规则,如果栈上的词满足这个规则,feature的这一位就是1,否则就是0. 我们要根据这个indicator features, 训练一个分类器,分类器输入indicator feature, 给出要做的操作,比如shift reduce, left arc, right arc。这样,不断把栈里面所有的单词都遍历完,这样就得到了一个句子的依赖关系。 实际上,indicator features规则的设计高度依赖专家对于该语言的语法以及背景的了解程度。indicator features很重要。
你的理解非常准确!总结得很好!下面是对你总结的一些补充和细化,帮助你确认理解的细节: 1.Transition-Based Dependency Parser 确实是 MaltParser 的核心框架。你提到的堆栈、缓冲区、以及 Left-Arc、Right-Arc 等操作,都是 Transition-Based Parser 定义的解析动作,这部分和 MaltParser 的解析流程密切相关。2. Indicator Features:你解释得很清楚!MaltParser 的精髓之一在于利用指示特征(Indicator Features)来描述当前解析状态。这些特征由专家设计,并包含丰富的语言结构信息,帮助解析器捕捉语法上的关键关系,比如名词、助动词等。3. 特征编码:你正确地指出,这些规则构成了高维的二进制特征向量,通常维度较高(可能有成百上千个特征)。如果某条特征(规则)被当前解析状态满足,则该特征对应的位被置为 1,否则为 0。这一步使得 MaltParser 能够在机器学习模型中有效地利用解析状态。4. 分类器的训练:你正确地说明了 MaltParser 训练一个分类器来预测动作。分类器使用训练数据生成的指示特征来学习特征与解析动作之间的关系,经过训练后,分类器可以在解析过程中为每个解析状态预测最可能的动作(Shift、Reduce、Left-Arc、Right-Arc等)。5. 依赖关系的构建:解析过程中,MaltParser 通过分类器不断预测下一个动作,逐步将堆栈中的所有单词遍历并连接起来,最终生成完整的句子依赖关系树。整个过程是自动的,但依赖于训练好的分类器模型和设计良好的指示特征。6. 特征设计的重要性:你指出了指示特征设计的重要性,这一点非常关键!特征的设计直接影响到分类器的表现,因为它决定了分类器能否获得充分的语言结构信息来做出正确的决策。因此,设计特征时需要专家对语言语法的深入理解。
如何处理non-projective的情况? 可能的方向有以下:
- 投降
- 用CFG而不是依存结构。
- 使用一个后处理器来解决非投射性的问题。
- 添加额外的action,比如swap,来解决交叉依存。
- 使用不受投射性约束的解析机制 e.g., the graph-based MSTParser or Dozat and Manning (2017)
Neural Dependency Parser
但是,到了这一步,这种transition-based parsing还有问题。我们前面说了,我们需要专家设计特征并计算特征。 这个过程一眼坏,又依赖专家,又稀疏,不太好。那么怎么做呢?显然就是要用机器学习
我们希望让parser自己学习什么特征应该学。神经网络将这些信息(如栈顶单词、缓冲区第一个单词、词性等)编码成一个稠密的向量,例如 [0.1, 0.9, -0.2, 0.3, ..., -0.5],其维度大约为 1000。这种稠密表示包含了有关句子结构的复杂信息,是由神经网络模型通过训练自动学习得到的。
这个稠密的向量可以不是词向量,词向量是单词的第一层嵌入,还可以用神经网络在词向量的基础上生成一个稠密的,更适宜于这个任务的表示。
费曼总结
我大概懂你意思了,你看我这么说对不对。就是说,虽然word vector也是稠密的向量,但它其实是一种类似于预处理的东西,一种低级别的嵌入。而我们要做的,就是要训练一个神经网络,以词向量为输入,输出一个稠密的特征矩阵。word vector其实是一个更前置,更basic的东西,这么说对吗?
A neural dependency parser (Chen and Manning 2014) 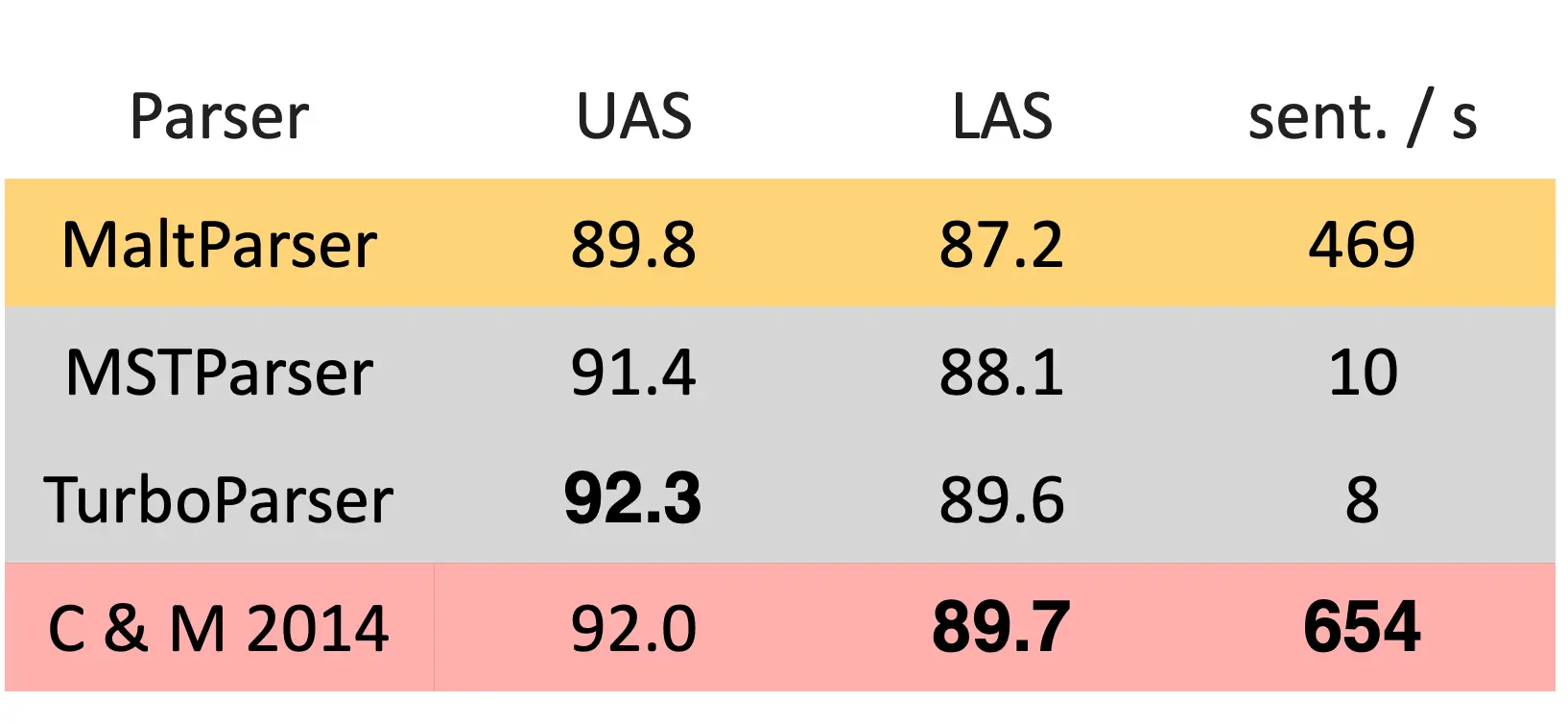
这个方法里面,还没有做到完全的让神经网络学习如何得到特征向量,而是制定了一种特征向量生成规则,对这个特征向量进行分类。
规则就是一种基于先前关系以及词性加和的设计: 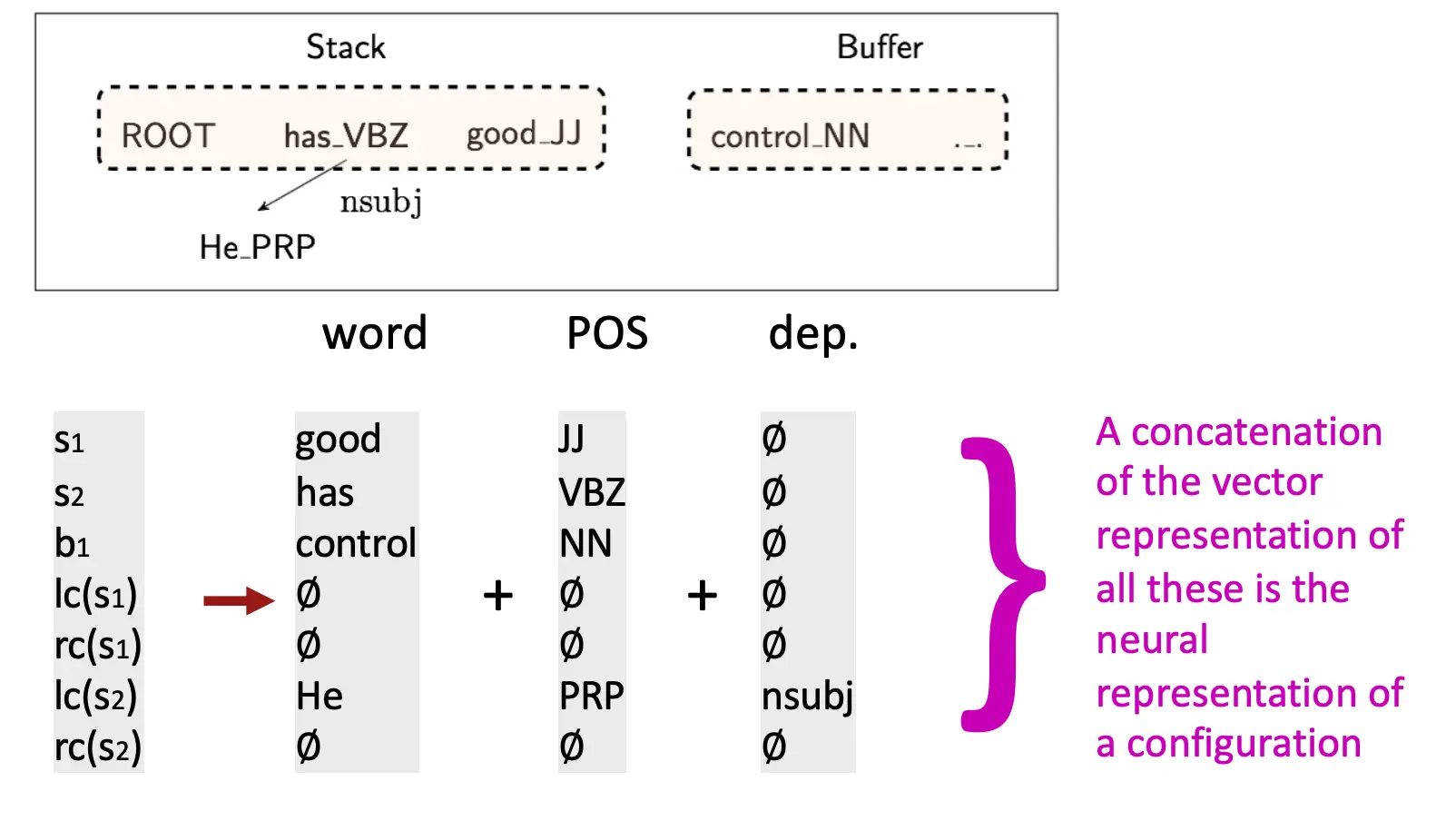
他们之后还证明了,神经网络可以准确地确定句子的结构,支持意义解释。由于特征够dense,所以够快。
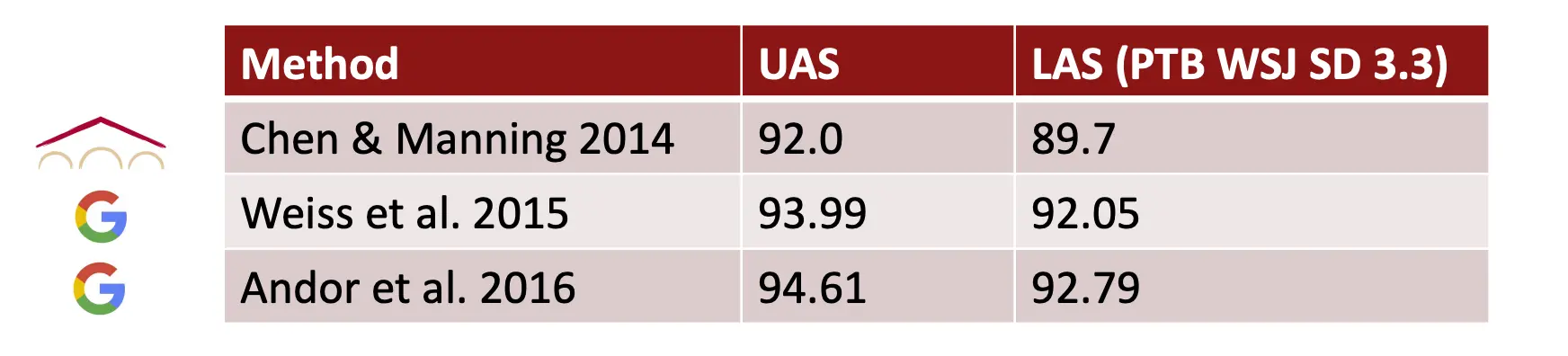
后续还有一些工作,贴在这里以供参考: “The World’s Most Accurate Parser” https://research.googleblog.com/2016/05/announcing-syntaxnet-worlds-most.html
Graph Based Parser
将问题转化为最大生成树问题,边的权重是由机器学习评估的。 其实就是把每个词作为依存词(中心词)的权重算一遍,搞出一个完全图之后,最后做一个最大生成树。
 这种效果很好,但很慢。因为这从理论上来说是全局最优解,也利用到了上下文。
这种效果很好,但很慢。因为这从理论上来说是全局最优解,也利用到了上下文。
 Larry Shi
Larry Shi