Bayesian Regression
频率派 vs 贝叶斯派
拿线形回归举例。频率派认为,参数w都是定的,而误差来自于不可学习的噪声epsilon 贝叶斯派认为,参数w都是一个条件概率分布,而误差来自于w分布你选择不同的w。数据量越大,这个分布就越集中。 贝叶斯派:
概率视角下的线性回归
我们认为,w是确定的,不确定性来自于噪声epsilon:
而我们认为噪声epsilon为高斯分布,且记
对于多元正态分布,方差会被换成协方差矩阵
对数似然:
而由于前两项都是定值,所以我们最大化L就相当于要最小化:
这就可以看出,在点估计,频率派的视角下来看,OLS和MLE是一样的。
贝叶斯视角下的线性回归
当数据和模型处于一个过定状态的时候,你最后学出的内容可以是一条线,并认为误差是噪声带来的: 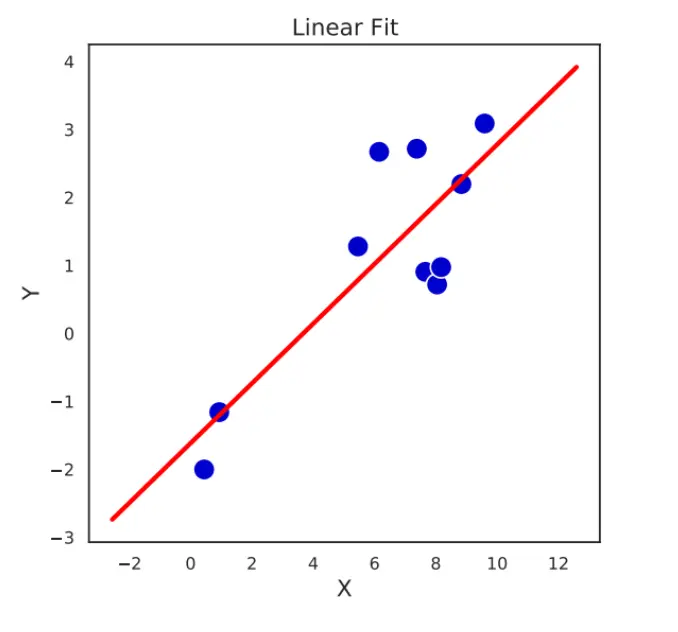 但当系统欠定的时候,实际上可以有多个线,且每个线的可能性不太一样,这里就需要贝叶斯派,用概率来确定参数的family。
但当系统欠定的时候,实际上可以有多个线,且每个线的可能性不太一样,这里就需要贝叶斯派,用概率来确定参数的family。 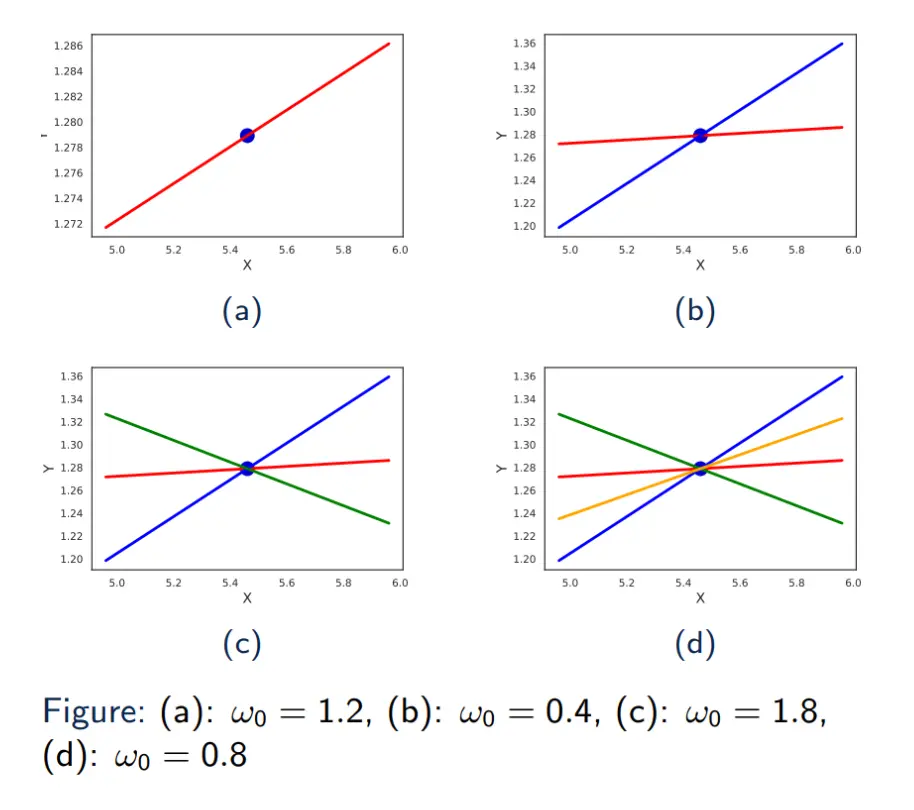 在频率视角中,当我们得到似然函数之后,我们做的是最大似然函数。但是在贝叶斯视角中,我们先停在似然函数:
在频率视角中,当我们得到似然函数之后,我们做的是最大似然函数。但是在贝叶斯视角中,我们先停在似然函数:
由于多变量的不确定性太难推导,所以我们这里就只考虑,w0,即截距不确定的情况下的贝叶斯视角。 首先,我们有先验知识,认为w0是服从高斯分布的:
那么似然函数为:
根据贝叶斯定理,我们有:
两边取对数,贝叶斯的分母化为const:
通过一个复杂的配方过程,我们可以把上面这个结果凑成下面的形式:
其中
利用先验和似然,得出w的后验分布:
配方之后,得到后验依旧是高斯分布:
其中,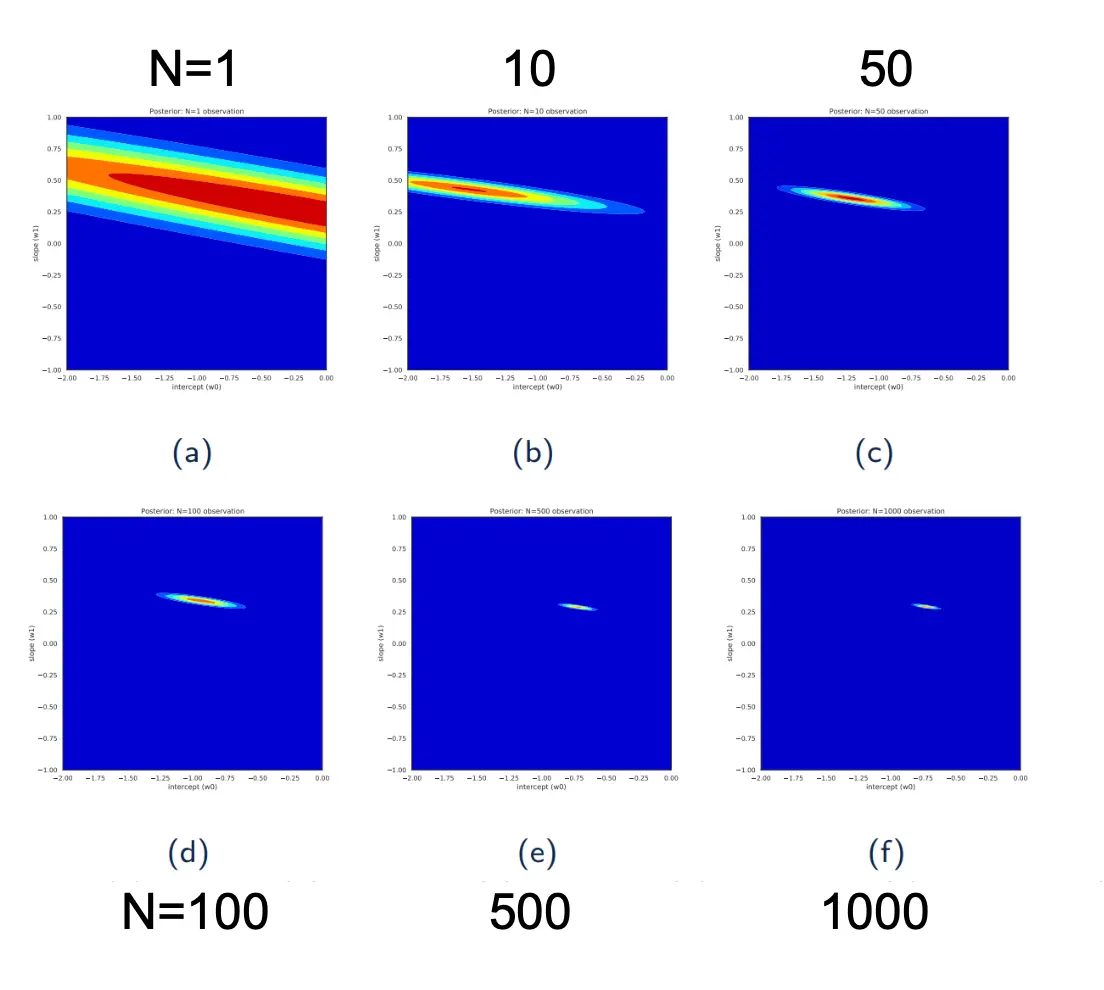
贝叶斯流派估计新数据
预测分布由此公式算出:
其中,右侧的后半部分已经有了,前半部分呢?对于训练集我们有:
而由于我们认为,测试集和训练集的采集方法是一样的,即分布是一样的,所以y* 同样满足:
贝叶斯例子
模型假设
我们假设观测满足 y=w x+ϵ,ϵ∼N(0,1)先验
在看数据前,认为参数 w 服从平均值 0、方差 1 的正态分布:
w∼N(0,1)观测数据
只有两对点:(x,y)=(0,0),(1,1)。更新后验
- 后验的均值就是把数据“加权平均”后得到的最佳估计:
- 后验的方差表示我们对 ww 的不确定性:
所以更新后 w 约等于 0.5±\sqrt{0.5}。
- 后验的均值就是把数据“加权平均”后得到的最佳估计:
做新点预测
想知道在 x∗=2时,y∗会怎样。贝叶斯预测给我们:- 预测均值: $$E[y^]=x^\mu_N=2\times0.5=1。$$
- 预测方差:模型噪声 1 加上参数不确定带来的额外方差:
因此 y∗ 的分布是 N(1, 3)
 Larry Shi
Larry Shi