Deep Double Descent: Where Bigger Models and More Data Hurt
https://arxiv.org/abs/1912.02292dual_1912.02292v1OpenAI Blog - Deep double descent
OpenAI讨论了双重下降的现象。
NOTE
这篇文章我解释的十分主观,有些内容paper并没有提到,就比如说训练数据与EMC的关系。这只是我的思考罢了,不要过分依赖。
这篇文章中,作者认为传统的使用参数进行衡量的模型复杂度不能很好的衡量真实的模型复杂度。模型的状态其实与分布,训练时间,参数量都有关,于是作者定义了一个Effective Model Complexity有效模型复杂度EMC。
epsilon为一个很小的值,这样定义通俗来讲,EMC就是指在一个训练过程T中,在样本S上的训练误差的期望十分接近0时,样本的最大数量n。其中样本S是独立同分布地从分布D中抽取的大小为n的样本集。 而双重下降这个现象就是随着EMC的变化产生的,比较明显影响EMC的变量是 样本训练epoch数,以及模型参数量。这都是通过影响训练过程T所影响EMC的。 其次,作者还定义了几个概念: 欠参数状态:如果EMC远小于目前的样本数量n(这个n和EMC定义里的n没关系),那么增加EMC会使test error下降 过参数状态:如果EMC远大于n,增大EMC会使test error下降。 临界参数状态:如果EMC约等于n,那么增大EMC,test error可能下降也可能上升。
那么就有下面的结果:
- 模型参数量层面有双重下降: 参数量增加,会出现双重下降。
- Epoch层面有双重下降: 训练epoch增加,会出现双重下降。
- 样本数量层面很混乱: 这个后面详谈。
- 噪声越大双重下降越明显: 如题。
接下来介绍每一种。
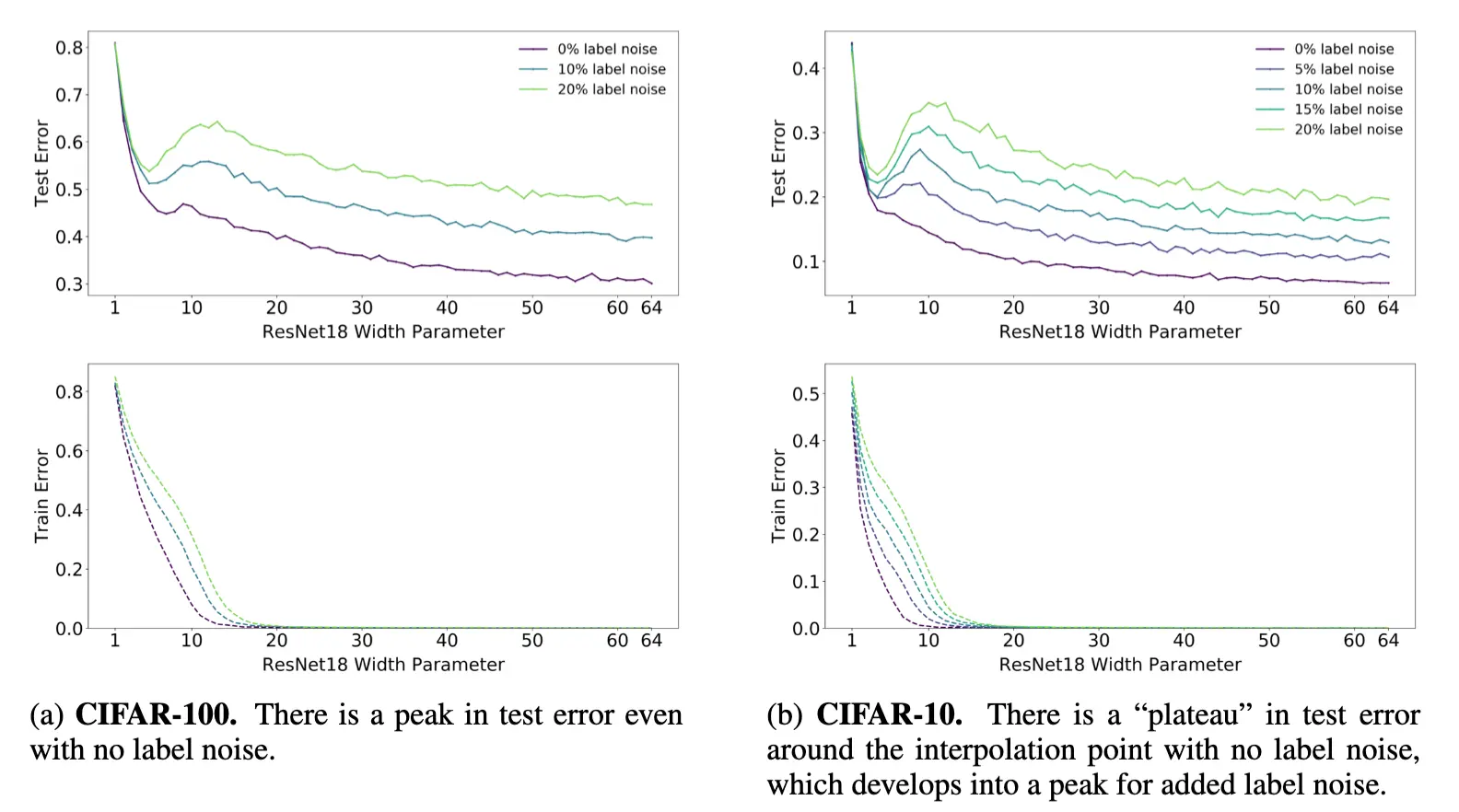
模型参数量层面有双重下降
不怎么需要解释,注意到噪声越大双重下降越明显,但test error会变小。
训练启示:
- 尽量尝试控制训练噪声
- 尝试增加数据增强
- 先尝试3种尺寸悬殊的模型,并选择效果最好的作为基础模型,并观察双下降的程度
- 优化后面两点的时候还需要回来修改参数量的,所以现在可以暂时确定下来
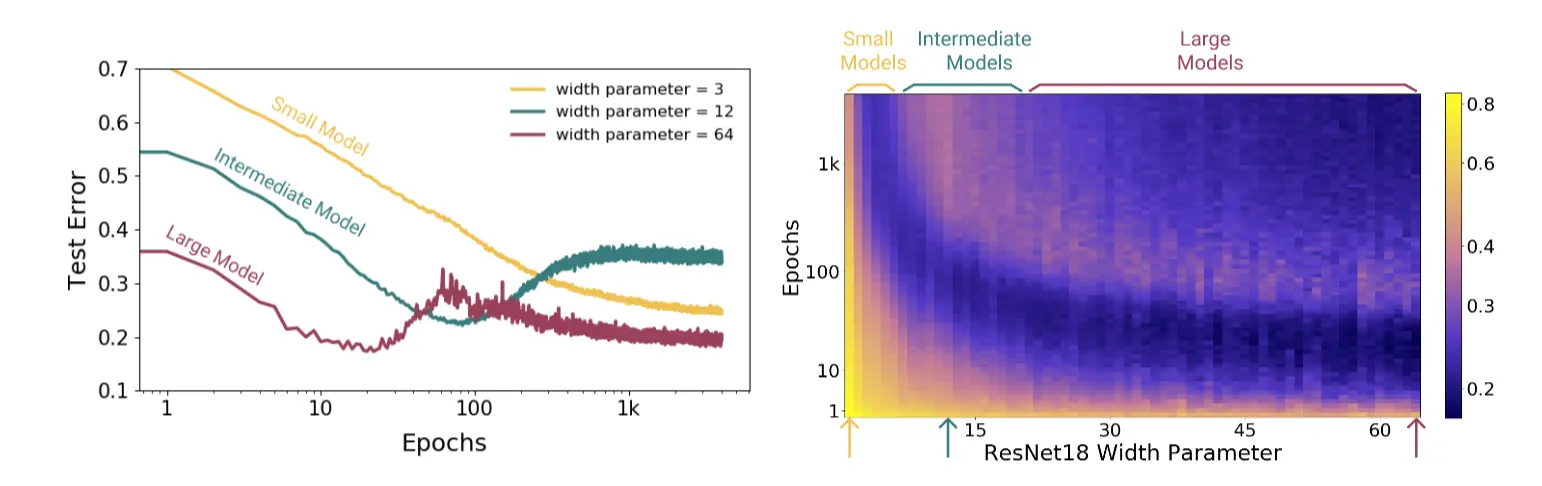
Epoch层面有双重下降
对于小模型,由于欠参数,所以增加epoch,test error下降。 对于中等模型,会出现U型曲线,过拟合。 对于大模型,就会出现双重下降。 对于大模型而言,随着训练轮数的增大,出现了double descent的现象;对中等大小的模型而言,出现了经典的bias-variance decompose的现象;对小模型而言,泛化误差逐步收敛(偏差高)
- 从由训练轮数引发的double descent看到,early stopping的解可能是次优的
一般来说,当模型刚好能够拟合训练集时,测试误差的峰值会系统性地出现。
训练启示:
- 尝试减小模型,效果可能会变好,但不一定达到期望(黄色线)
- 尝试增大模型,如果模型尺寸已经不能再增加,那就请尝试增加epoch(红色线)
样本数量层面很混乱
由于double descent现象的存在,一个有趣的现象在模型复杂度和数据集大小差不多的情况下(critical region),数据集变大会让泛化性能变差。
增加样本数量会使曲线向下移动,趋向于较低的测试误差。然而,由于更多的样本需要更大的模型来拟合,增加样本数量也会将插值阈值(以及测试误差的峰值)向右移动。对于中等模型规模(红色箭头),这两种效应结合在一起,我们发现训练样本增加 4.5 倍实际上会损害测试性能。 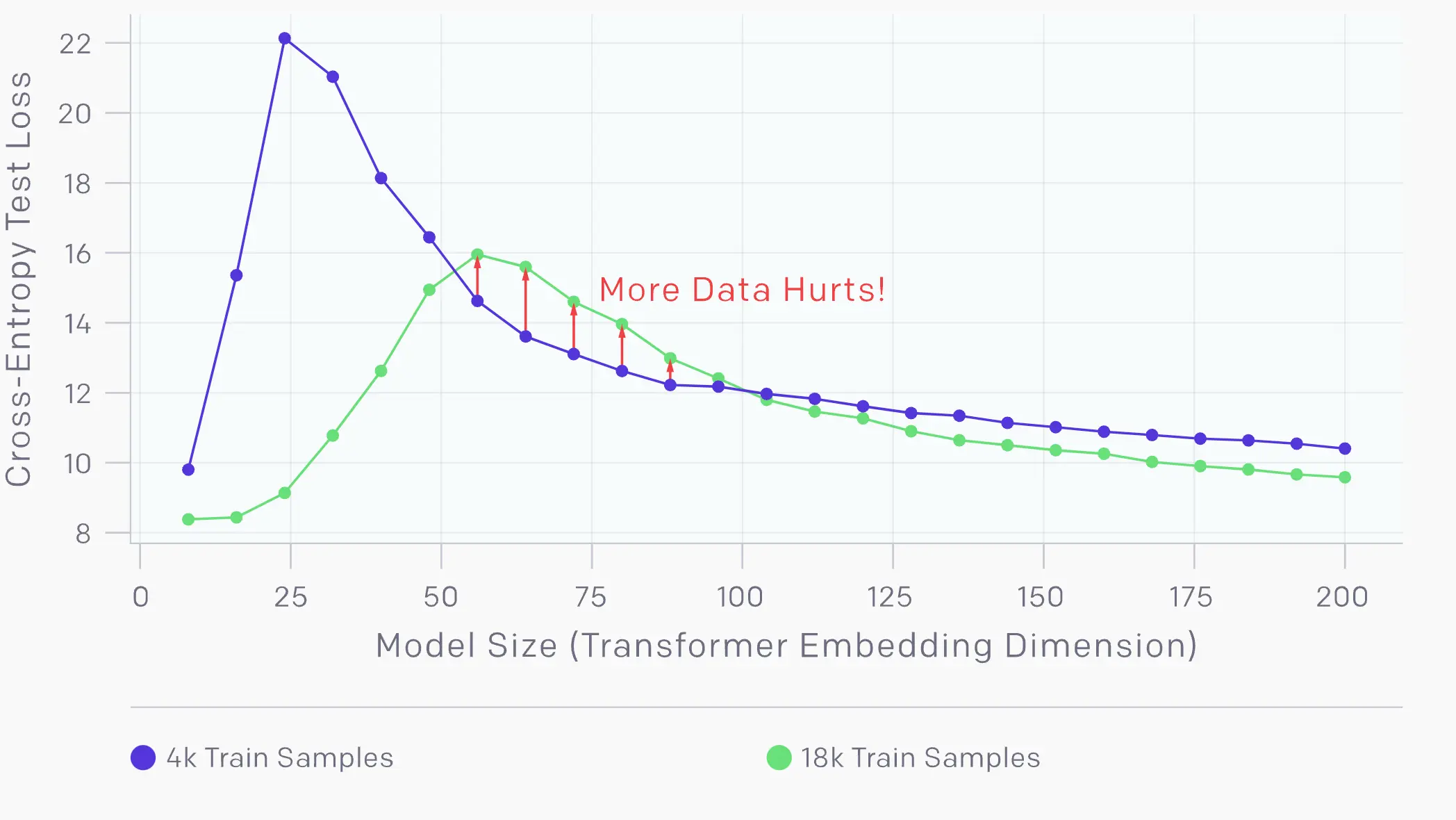
这个最复杂。首先这个图说明了两点:
- 增加samples,峰值右移动。
- 在红色,绿色的范围内,增加样本数可能并不会使得test error变化。
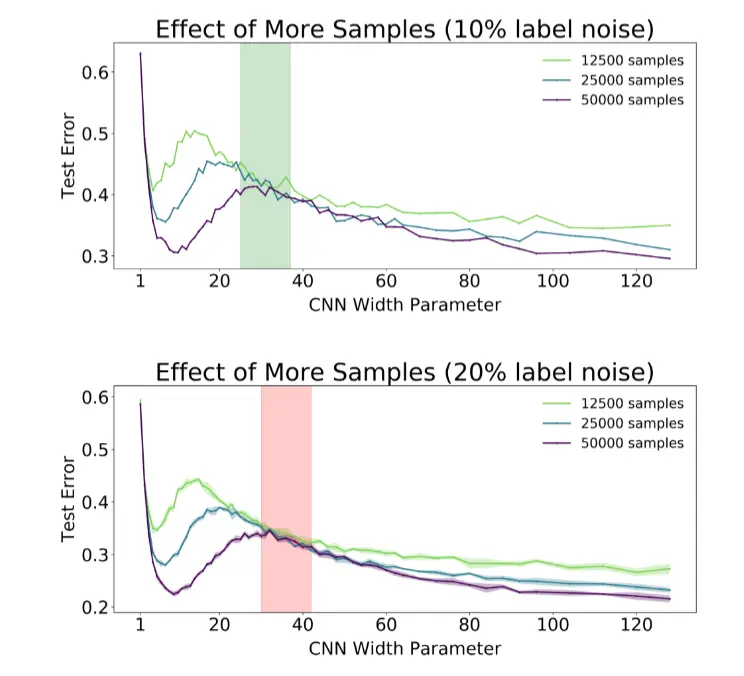
这张图Thansformer又说明了,对于小模型,增加样本会让test error减小。而对于大模型,会先增大,后减小。 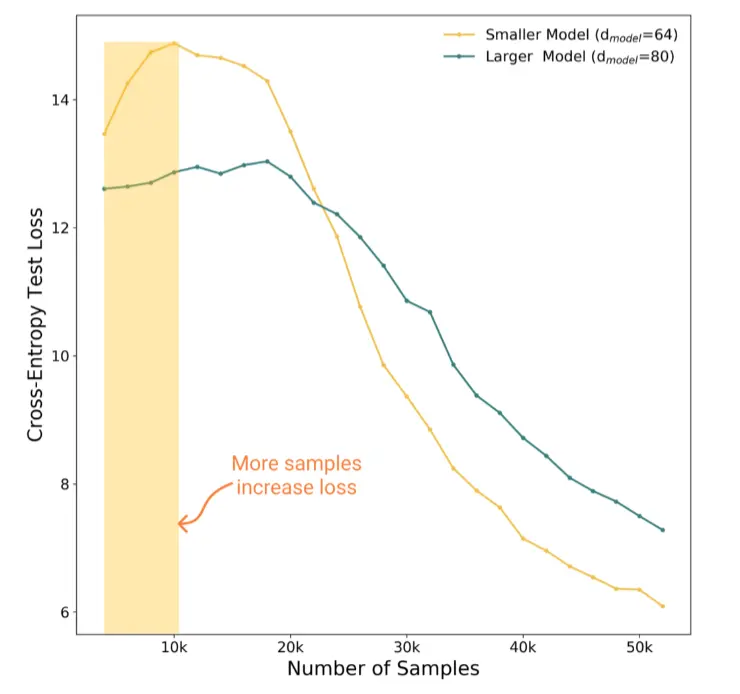
这张图又说明了,在过参数和欠参数的情况下,增加样本数量,test error都会减小;但如果在临界点,那么就会有平台期。 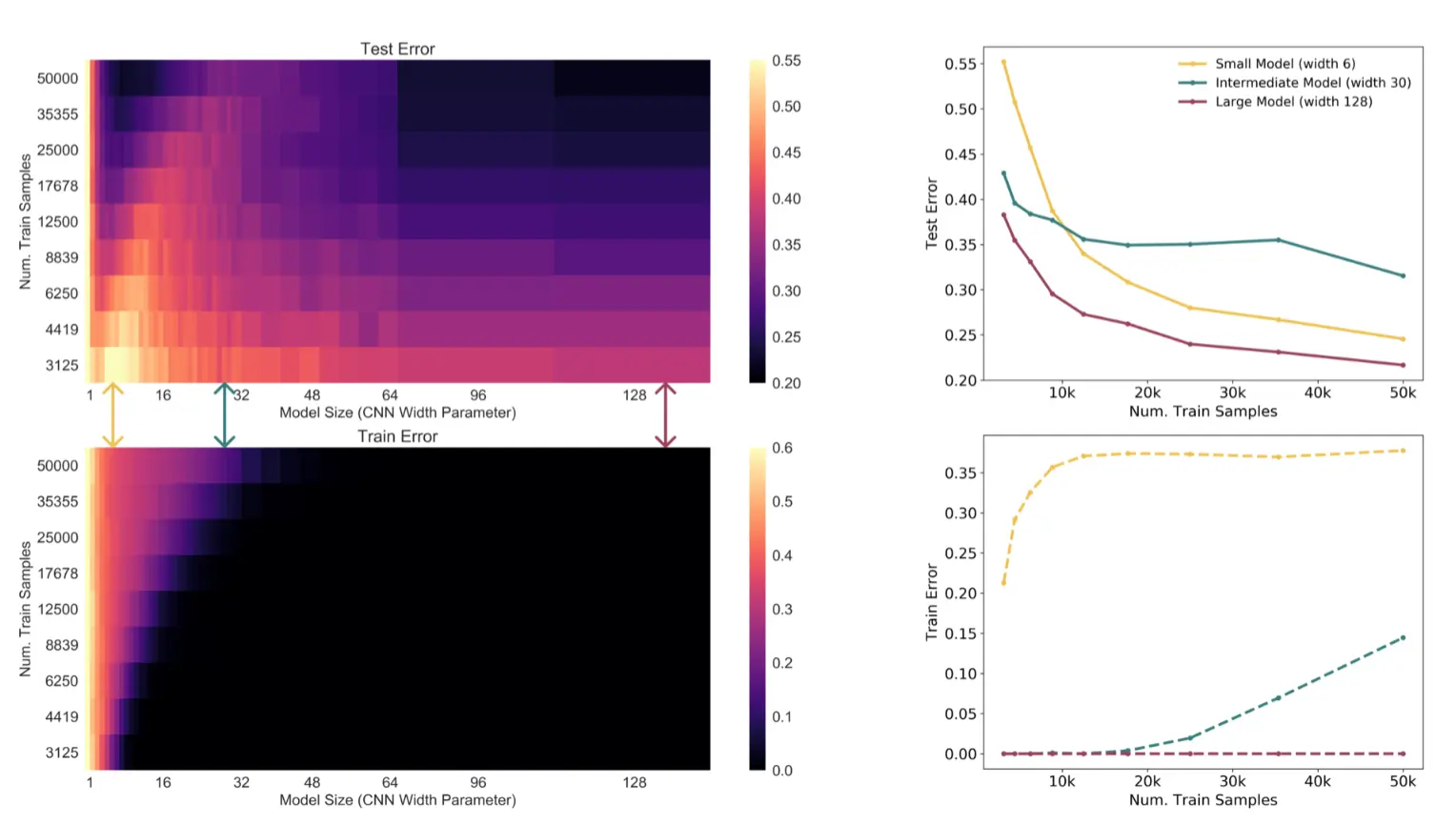
训练启示:
- 首先,应该用已有的模型对训练集数据进行清洗,并用数据指导微调数据增强
- 样本量增加如果效果不好,请增大或者减少模型
- 尝试训练数据量减半
- 如果效果仍然不好,只能考虑再大量地增加样本量(无奈之举,性价比太低不建议用)
- 信念:没有过拟合,只是没有妥当地训练好而已。在对抗过拟合之前应该先控制样本噪声和数据增强。随后慎重地行事。
噪声越大双重下降越明显
作者认为:
- 标签噪声不是双重下降的根本原因,而只是增加了模型学习的难度,如果训练数据的标签有错误,模型会更难找到规律,这让双重下降现象更容易被看到。但作者认为,噪声只是让问题“更难”,真正的原因是模型和数据不匹配
- 测试里面的噪声是伪随机产生的,也遵循某个分布。如果我们有一个足够强大的模型,它可以反转这种规则,噪声就不再是问题。即便如此,双重下降现象还是会发生。这说明,噪声只是增加了问题的难度,并不直接导致双重下降。 所以作者认为噪声不是双重下降产生的主要原因,但会让其显现。
 Larry Shi
Larry Shi