Neural Network and Backpropagation
标签
NLP
AI
DL
ML
字数
333 字
阅读时间
2 分钟
比较基础,只是挑一些比较有意思的拿出来看看。
Activation Function
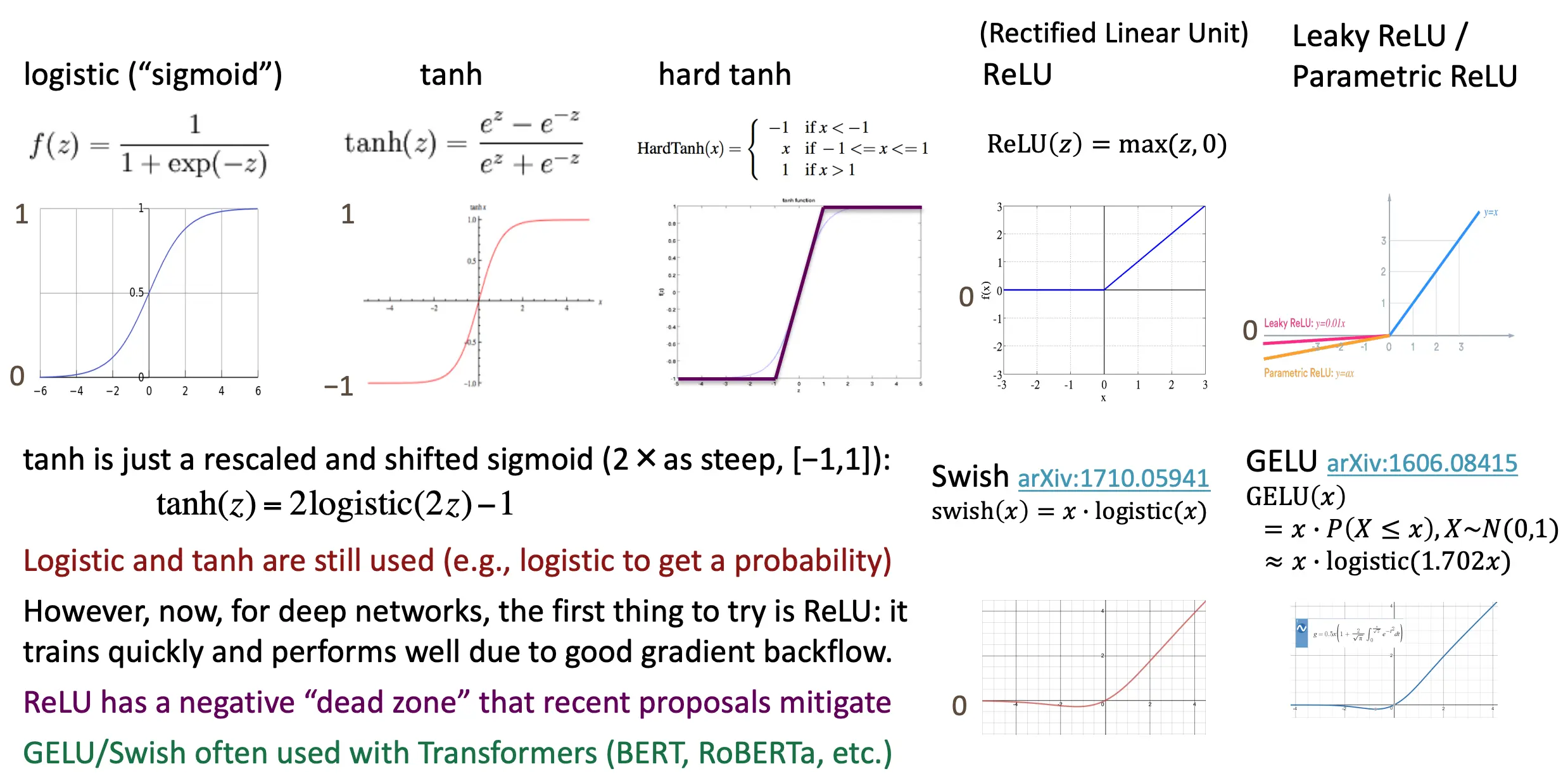
仍然使用logistic和tanh 然而最先使用的肯定是ReLU,然而,由于ReLU有个负dead zone,所以有Swish和GELU可以用 GELU/Swish经常在BERT,RoBERTa中用
手算梯度中的矩阵形状问题
首先我们定义一下Jacobian矩阵。其实就是偏导大矩阵。矩阵形状是 m * n, 函数数 by 变量数
我们来一个简单的例子来说明为什么有形状问题。
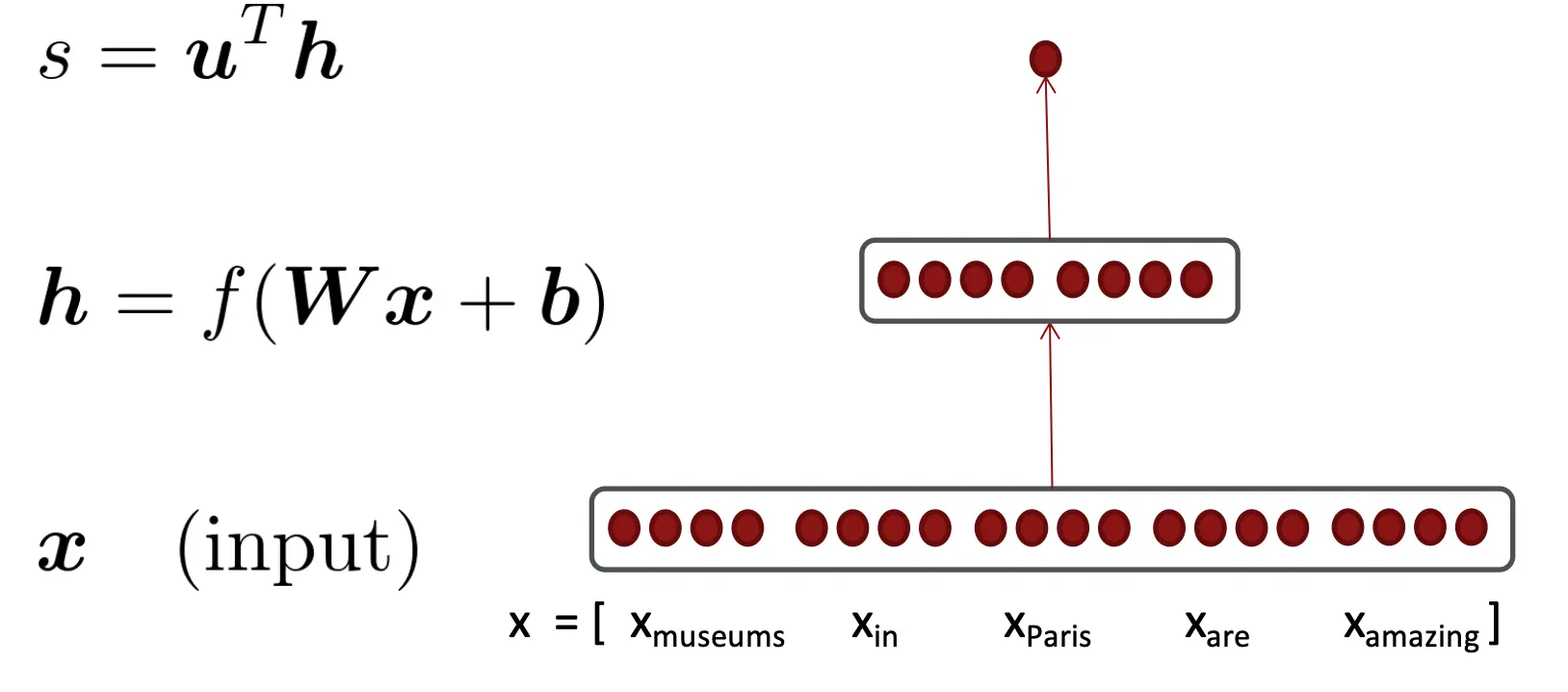
这个例子中,w的梯度这么算:
这么算出来,s/w梯度是 1 by nm,而W是n by m,所以我们还得reshape 所以计算的时候,你可以一直用jacobian算,算到最后reshape,也可以边算变整形。
- 第一种方法(雅可比形式):更灵活,适合理论推导或中间层的计算,但需要最后调整形状。
- 第二种方法(遵循形状约定):更直接,适合实现和实践中的反向传播,确保所有参数形状一致。
 Larry Shi
Larry Shi