Pretraining
分词
传统 NLP 方法假设一个固定的词汇表(vocabulary),通常由训练数据中的常见词汇组成,大小为数万个词。 测试时,所有未在词汇表中的新词(novel words)都会被映射为一个特殊的 "UNK"(unknown) 标记。
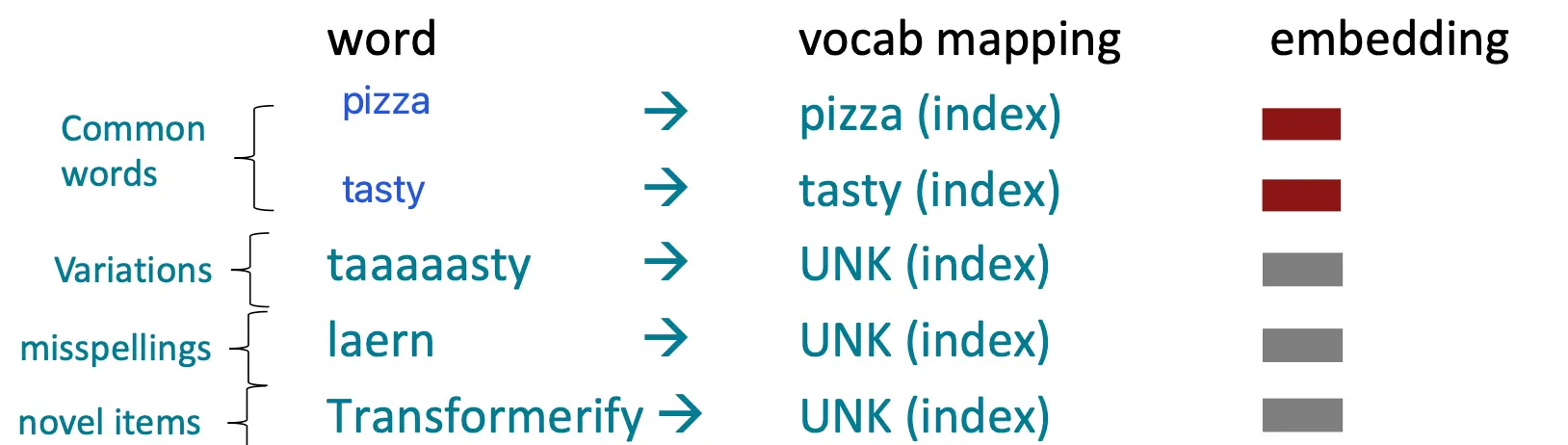
英语中,这种假设已经有局限性。 其他语言(如斯瓦希里语等),这种假设更不适用,因为许多语言有复杂的词形变化(morphology),造成大量的词汇变体。例如:
- 一个动词可能有数百种变体,每种形式都编码了时态、语气、否定等信息。
- 这些变体可能在训练数据中出现次数很少或仅出现一次。 你不应该把每一个变体都单独嵌入一遍。
如今我们采用 子词建模(Subword Modeling)
- 词汇的固定假设不适用于许多语言,因此需要一种方法来处理词以下级别的结构,如子词、字符或字节。
- 子词建模通过将单词分解为更小的单元(如子词)来解决这些问题。
- 现代 NLP 模型(如 BERT 和 GPT)使用子词建模来构建词汇表,而不是单词级别的词汇表。
而常用的子词建模是Byte Pair Encoding (BPE)
- 初始词汇表只包含单个字符和一个“单词结束”符号。
- 找到语料中最常见的相邻字符对(如 "a" 和 "b"),将它们合并为一个新的子词(如 "ab")。
- 新子词替换语料中的字符对,重复这一过程,直到达到所需的词汇表大小。
例如,我们要求的词汇表大小是13,那么组合到13就停,打断 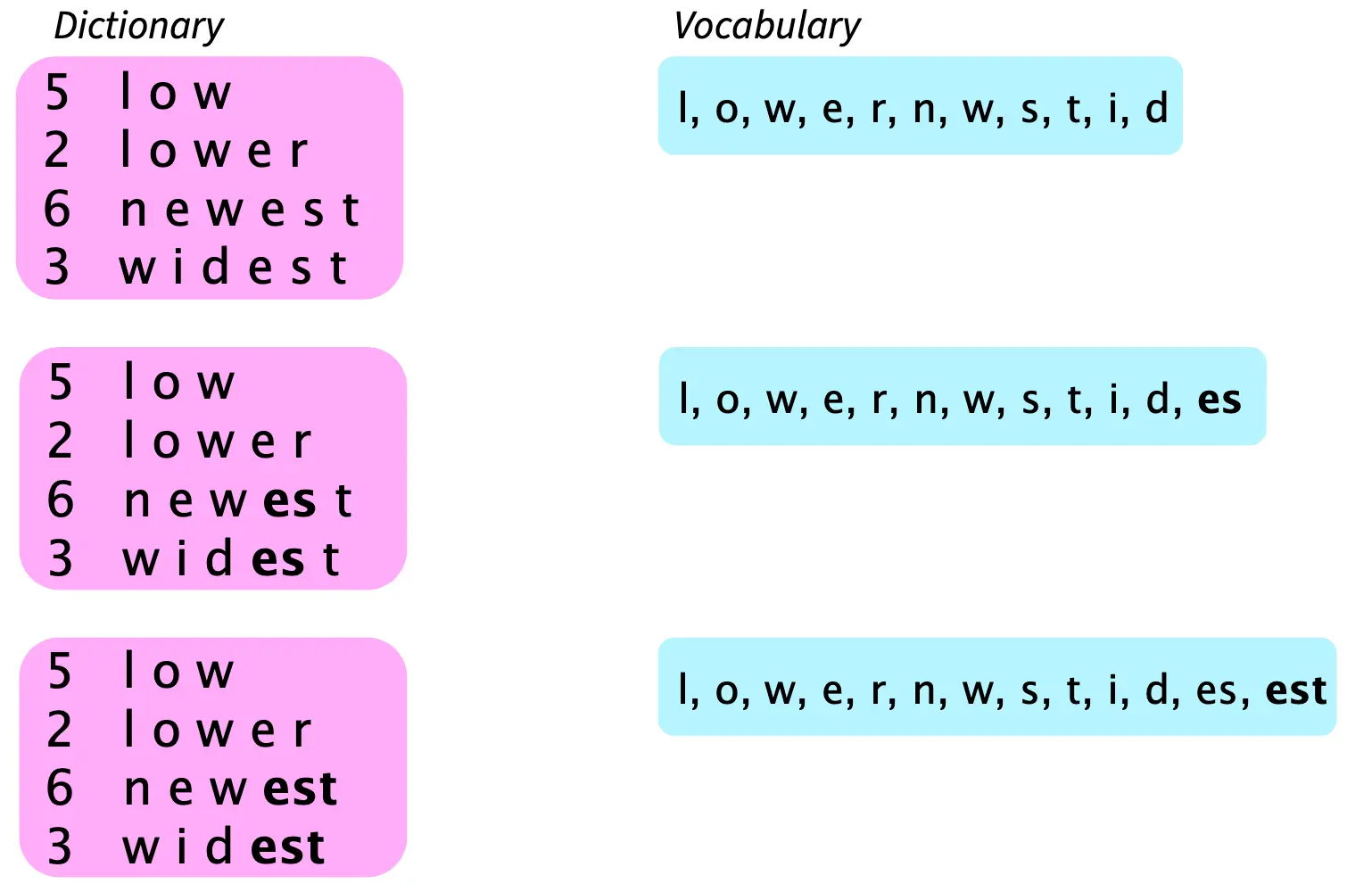 子词建模后的词语:
子词建模后的词语: 
Word Embedding to Pretraining
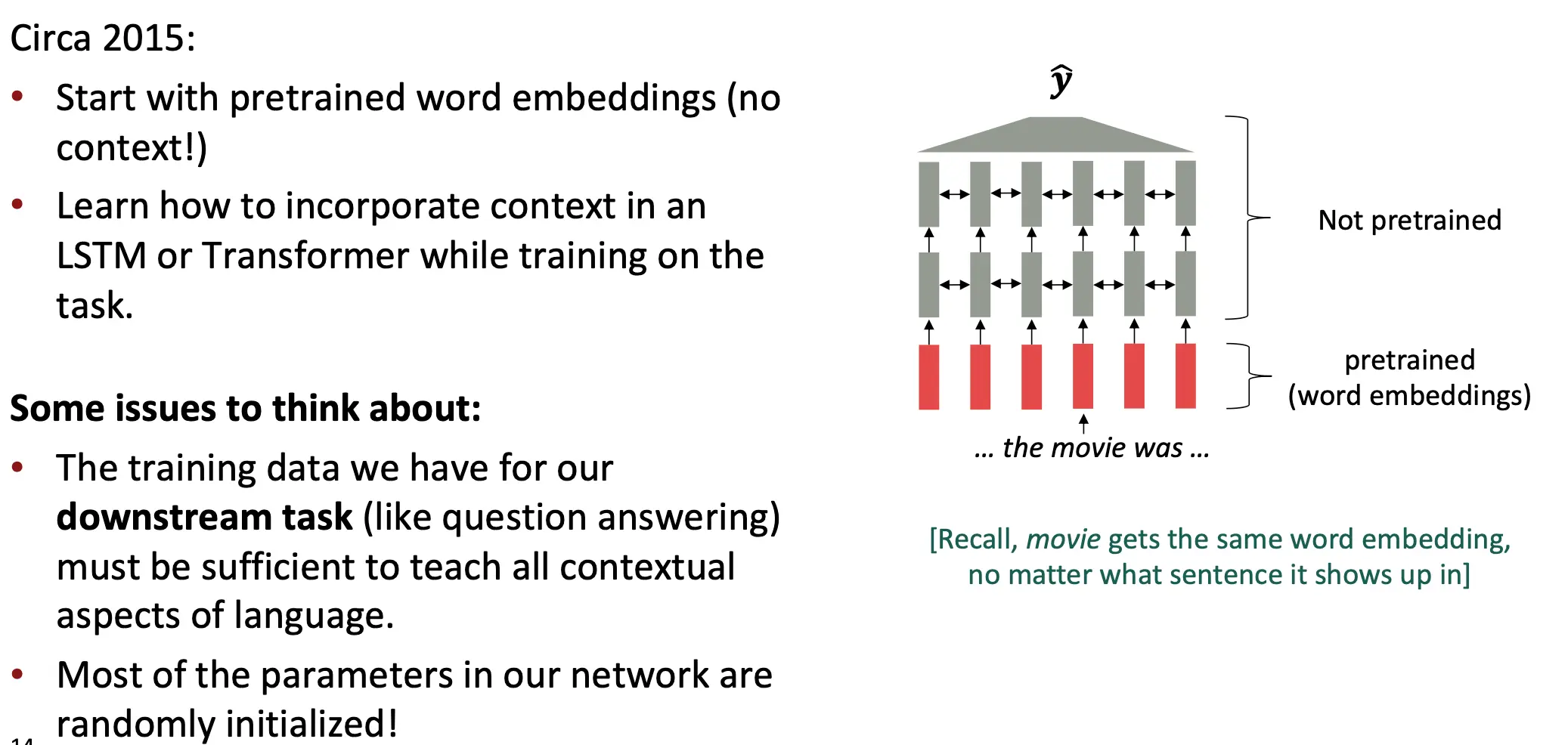
一个单词的意思在不同的上下文中有着不同的意思,比如I record the record. 原来是怎么做预训练的呢?只做word embedding的预训练。 那么就有问题:
- 下游任务的模型必须负责串联上下文语义
- 没有预训练(灰色)的部分比较大,模型训练慢,还可能不好训练
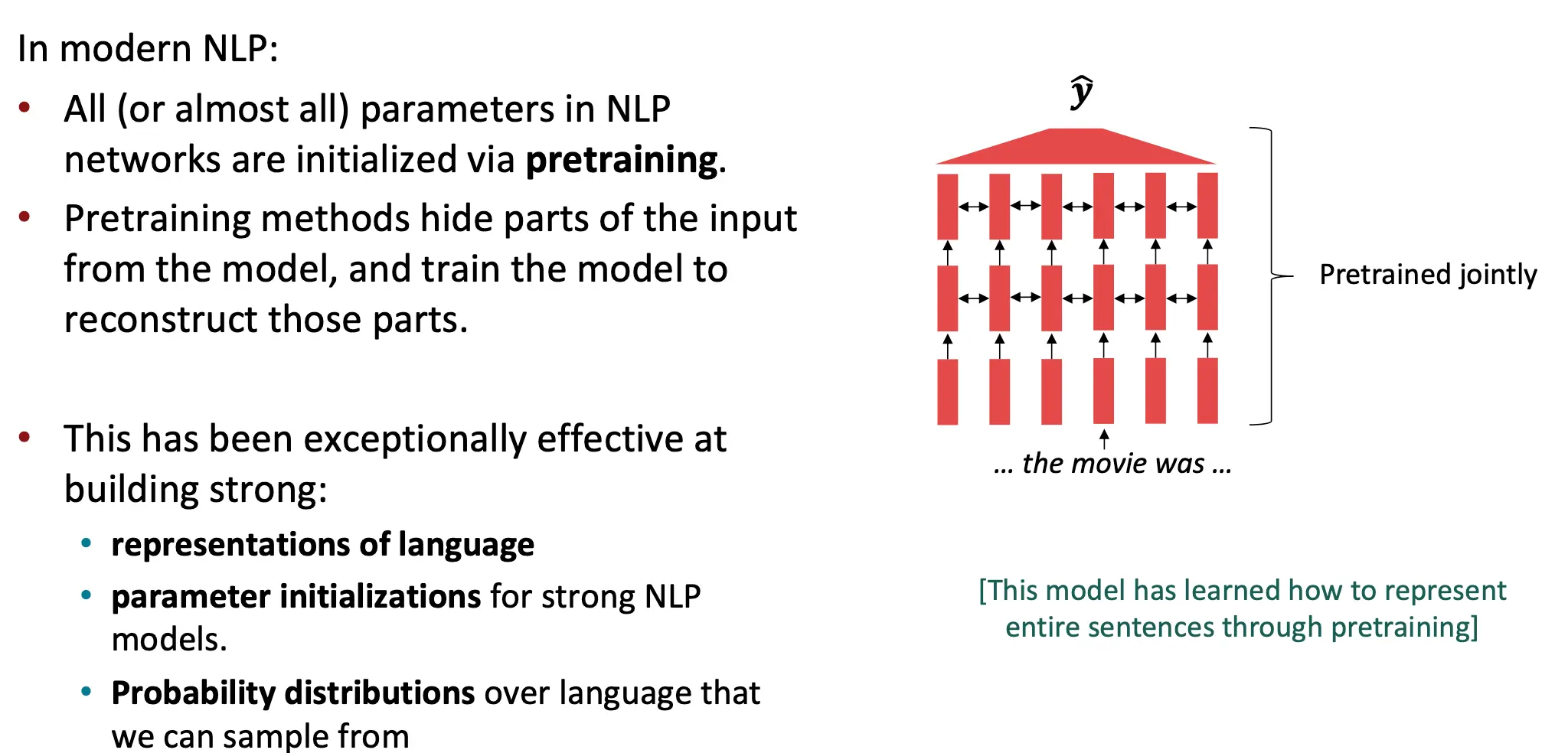
那么目前我们是怎么做的呢?预训练整个模型 现代 NLP 模型中,几乎所有的参数(权重)都会通过预训练来初始化。让模型在大规模无监督语料上学习到通用的语言表示,从而为下游任务(如情感分析、问答系统等)提供一个强大的起点,而不是从零随机初始化模型参数。
预训练方法的核心是掩码语言建模(Masked Language Modeling, MLM) 或类似技术
- 在输入中随机隐藏(mask)一些部分(例如单词或子词)。
- 训练模型根据上下文预测被隐藏的部分。 预训练方法在以下几个方面表现出色:
- 语言表示(representations of language):
- 模型通过预训练学会了如何表示语言中的语义和句法信息。
- 例如,单词“bank”在不同上下文中可以表示“河岸”或“银行”,模型能够捕捉这种多义性。
- 参数初始化(parameter initializations):
- 预训练为下游任务提供了良好的参数初始化,使得模型在小规模标注数据上也能快速收敛。
- 语言概率分布(probability distributions over language):
- 预训练模型学会了语言的概率分布,可以用来生成流畅、连贯的句子(如 GPT 系列模型)。
接下来,对预训练language model整体做一个轮廓描述。 首先,用神经网络(如 Transformer 或 LSTM)在大规模语料上训练LM,网络学习如何根据上下文生成合理的下一个单词,并保存训练后的网络参数。 之后,在少量标注数据上针对具体任务(如情感分类、问答、翻译等)进行微调,适配模型到具体的下游任务。 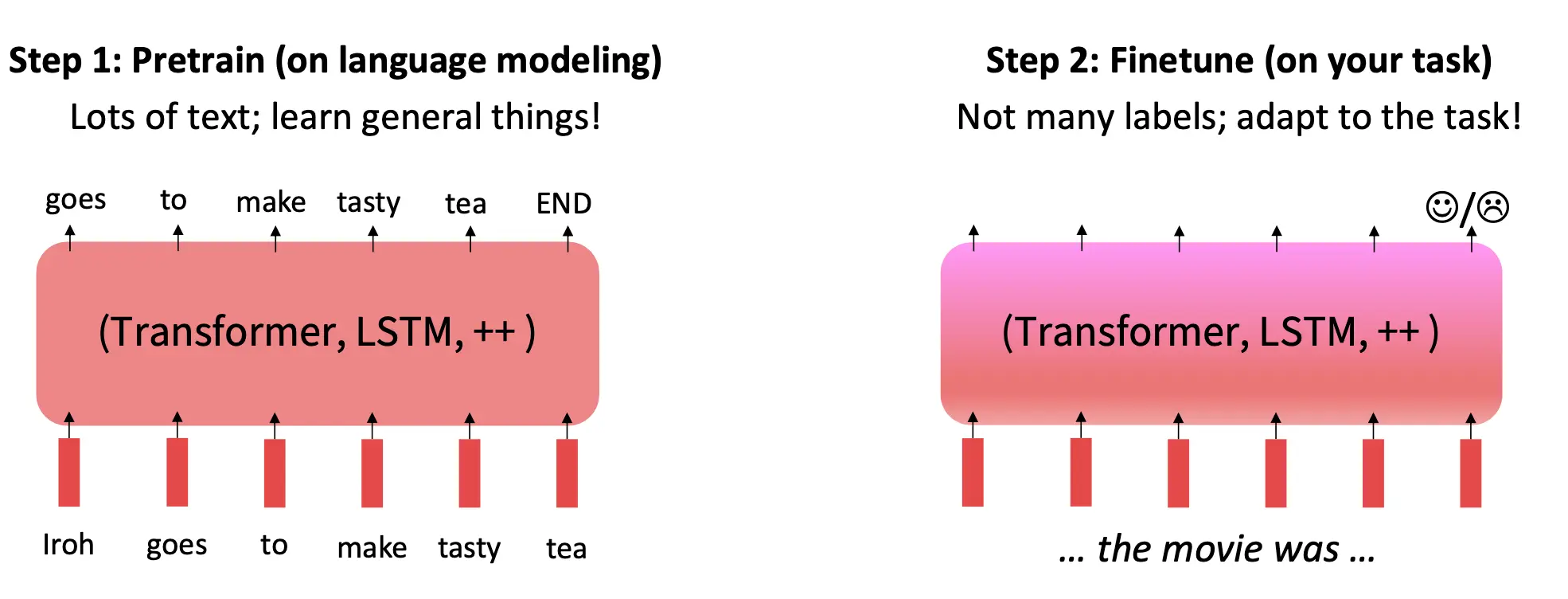 为什么预训练可以提供好的性能?因为预训练找到了一个好的参数起点,减少了优化难度,使得微调过程更稳定。
为什么预训练可以提供好的性能?因为预训练找到了一个好的参数起点,减少了优化难度,使得微调过程更稳定。
下面是一些常用的大型语料库: 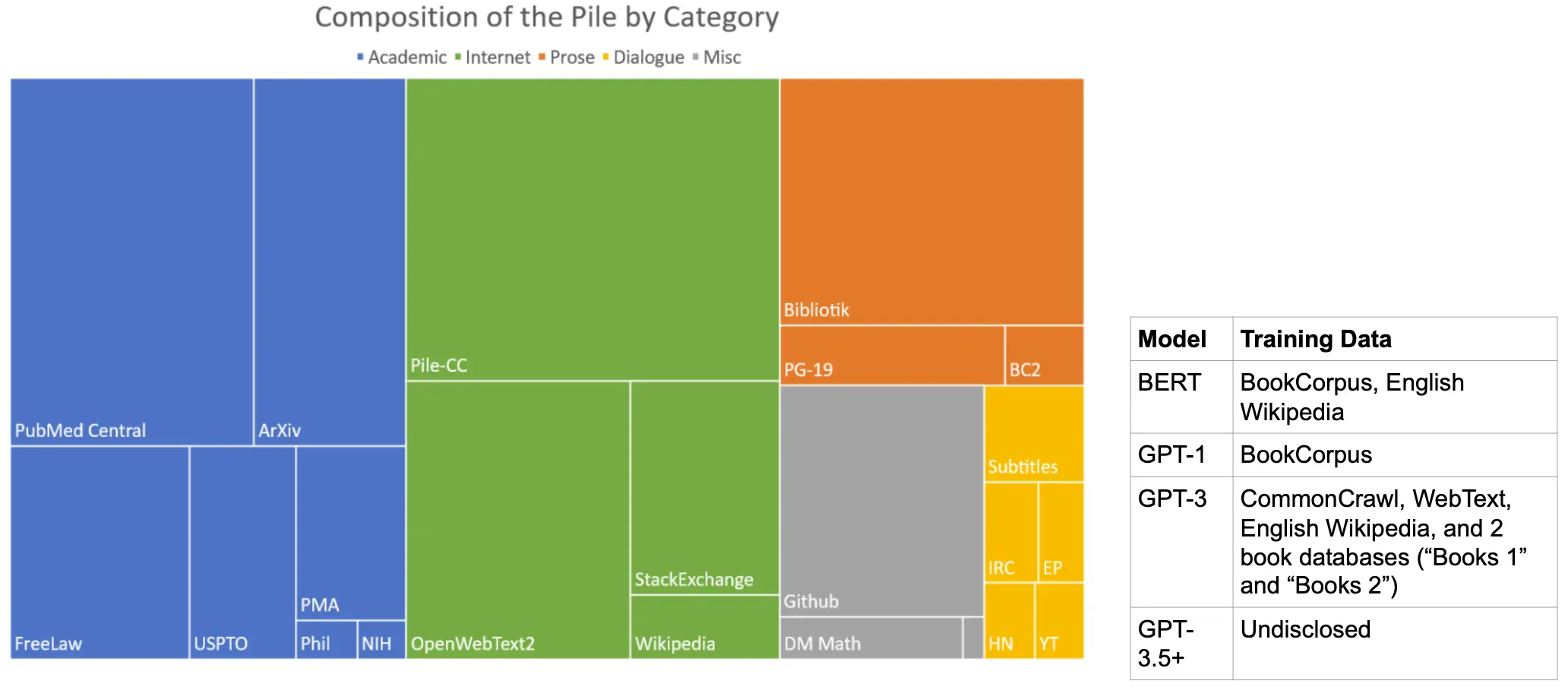
Encoder Pretraining
由于LM只能借助上文,应当是autogressive的,而Encoder是可以借助双向上下文的,所以说不能被当作LM用。 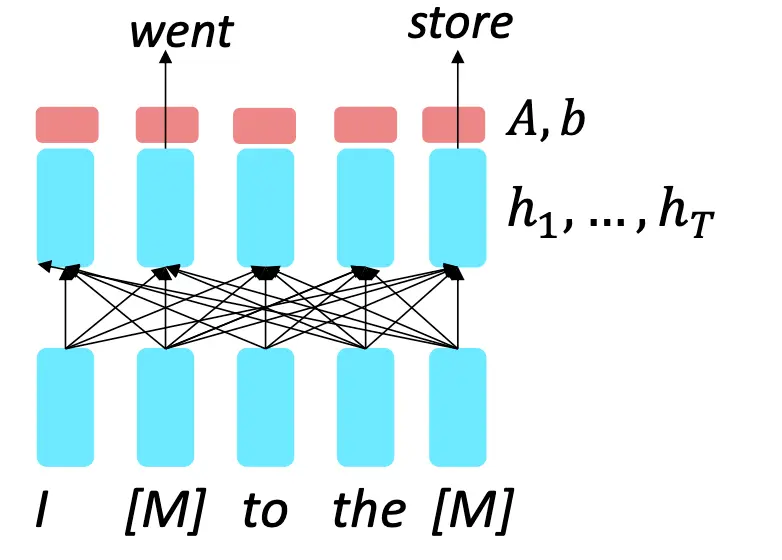 所以,我们不能用训练LM的范式去预训练Encoder。我们要用一种mask语言模型范式训练。思想是将输入序列中的一部分单词替换为特殊的
所以,我们不能用训练LM的范式去预训练Encoder。我们要用一种mask语言模型范式训练。思想是将输入序列中的一部分单词替换为特殊的 [MASK] 标记,然后让模型预测这些被掩码的单词。
BERT: Bidirectional Encoder Representations from Transformers
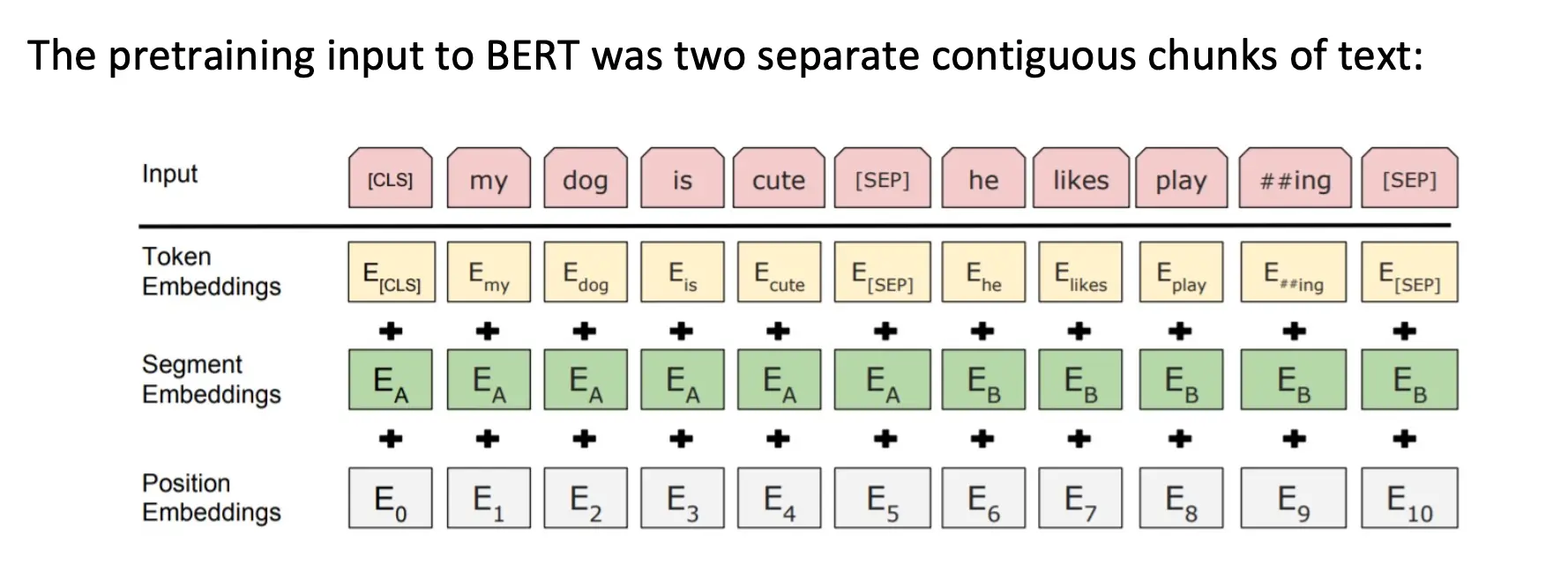
BERT就是通过Masked LM的方法预训练出来的。 下面是BERT对于Mask的参数设定:  BERT 在预训练时包含两个任务:Masked LM 和 Next Sentence Prediction (NSP)。NSP 的目标是让模型判断两段文本是否相邻。然而,后续研究(如 Liu et al., 2019)表明,NSP 对模型性能的提升有限,甚至可能是不必要的。
BERT 在预训练时包含两个任务:Masked LM 和 Next Sentence Prediction (NSP)。NSP 的目标是让模型判断两段文本是否相邻。然而,后续研究(如 Liu et al., 2019)表明,NSP 对模型性能的提升有限,甚至可能是不必要的。
- 任务目标:
- 如果第二段文本是第一段文本的后续,则标签为 "IsNext"。
- 如果第二段文本是随机采样的,则标签为 "NotNext"。
 一些BERT的details:
一些BERT的details:  BERT在很多任务上赢了:
BERT在很多任务上赢了:
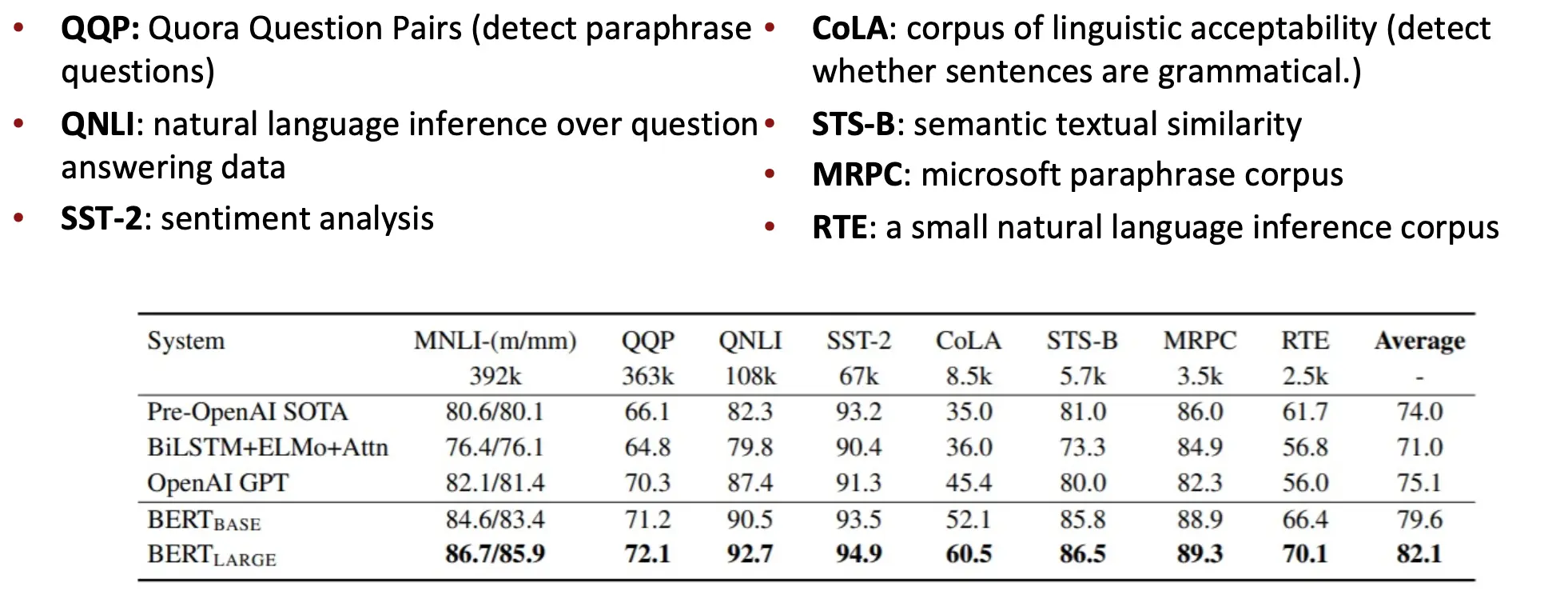
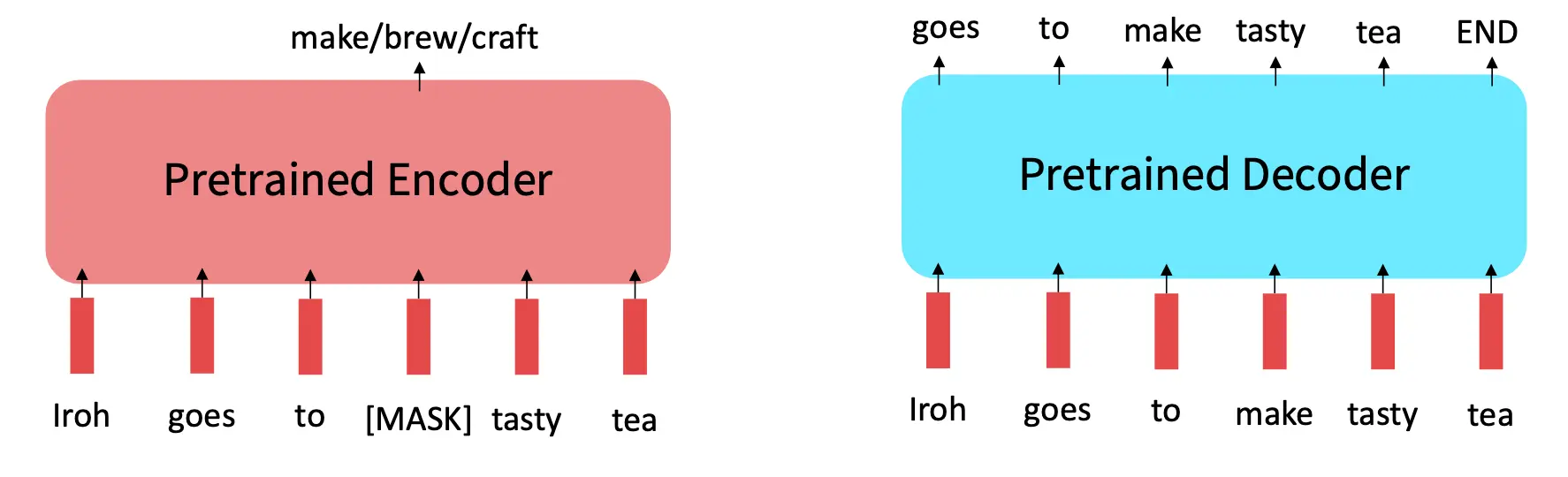
BERT 和其他预训练编码器(如 RoBERTa)表现出色,但它们的设计并不适合所有任务。编码器无法很好地支持序列生成任务(如文本生成、翻译),因为它们的训练目标(如 Masked LM)不是为生成一个接一个的单词设计的。 因为他能利用上下文,不能autogressive,所有不能做LM任务。如果要LM,那就用Decoder。
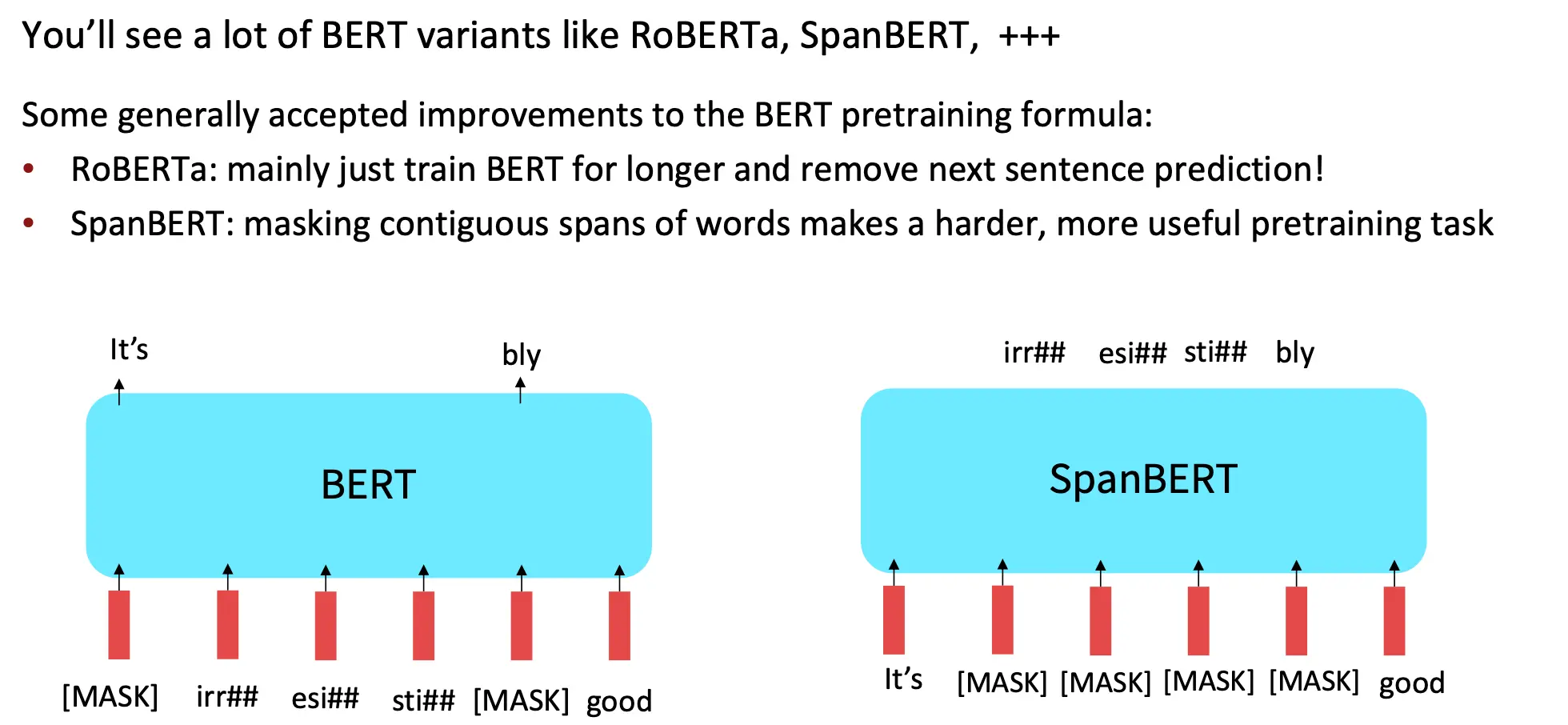
 还有一些其他版本的BERT:
还有一些其他版本的BERT:
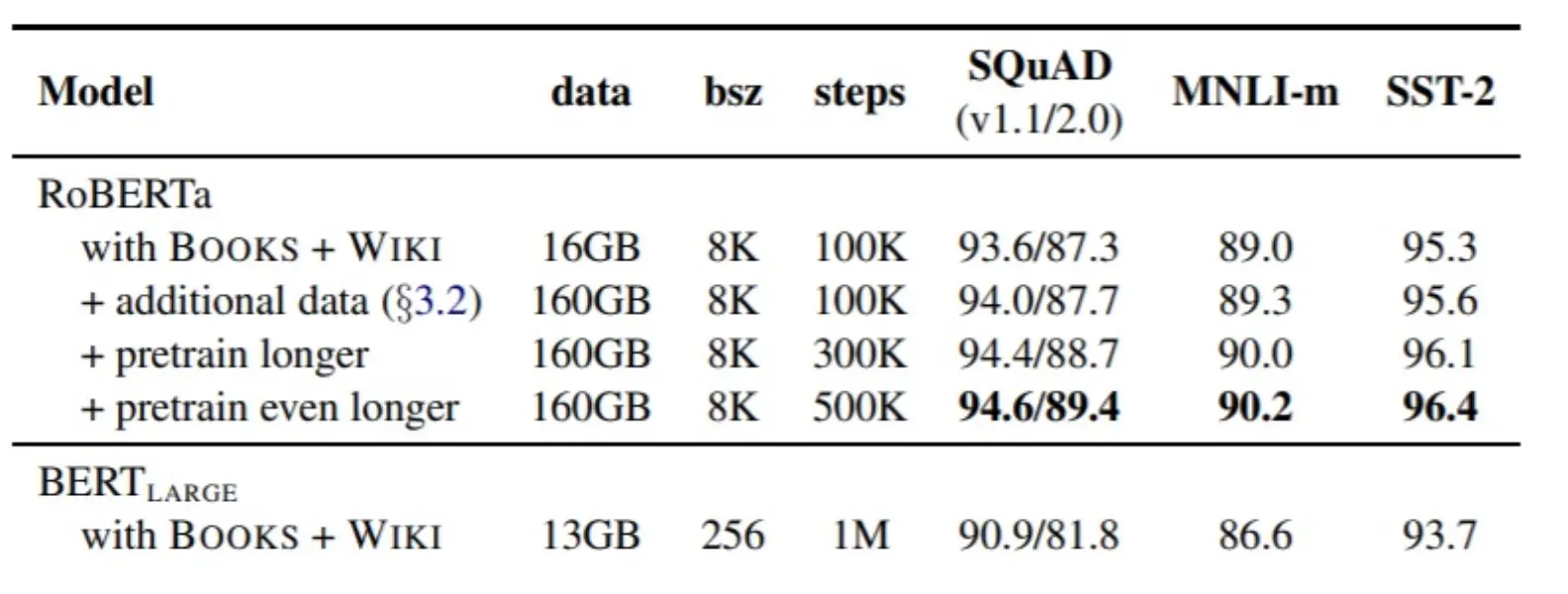
从RoBERTa论文中得出的一个结论:更多的计算资源和数据可以改善预训练,即使不改变基础的Transformer编码器。
Encoder-Decoder Pretraining
Encoder-Decoder其实是可以做一些类似于LM的工作的,但是它不是完全autogressive的,而是给一些前缀用来给Encoder双向上下文利用,这一部分不是自回归的,但后面可以用解码器进行文本生成,后一部分是自回归的。 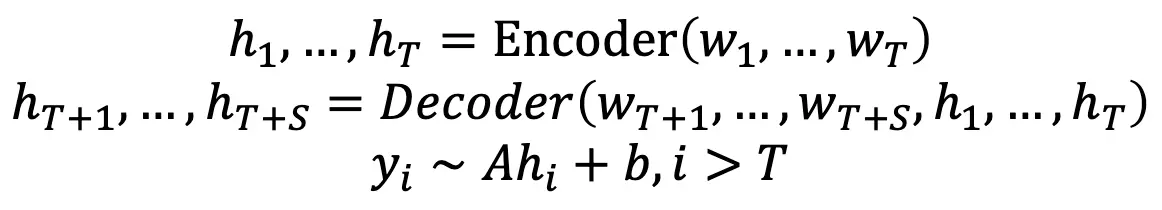
T5 Model
用unique的,不同span的mask去遮挡输入,让decoder预测mask掉的东西,长度不一样。
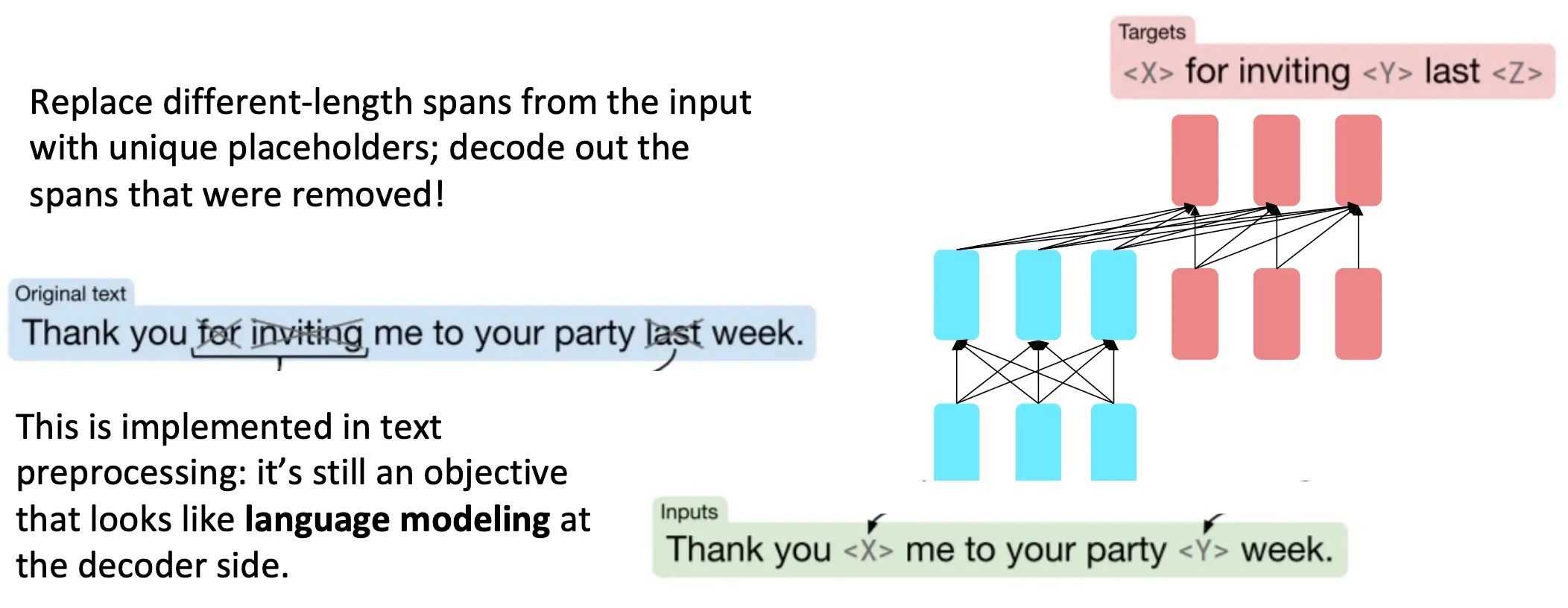
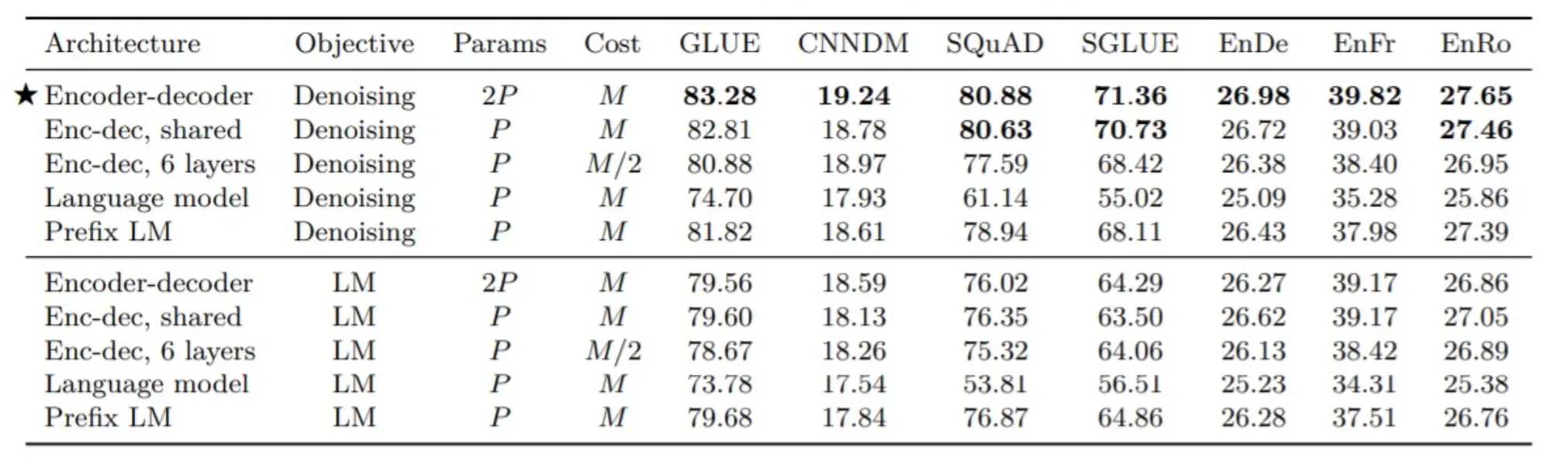
在很多领域内,编码器解码器结构要比纯解码器(如GPT)要好,比如片段修复,一种去噪声任务。
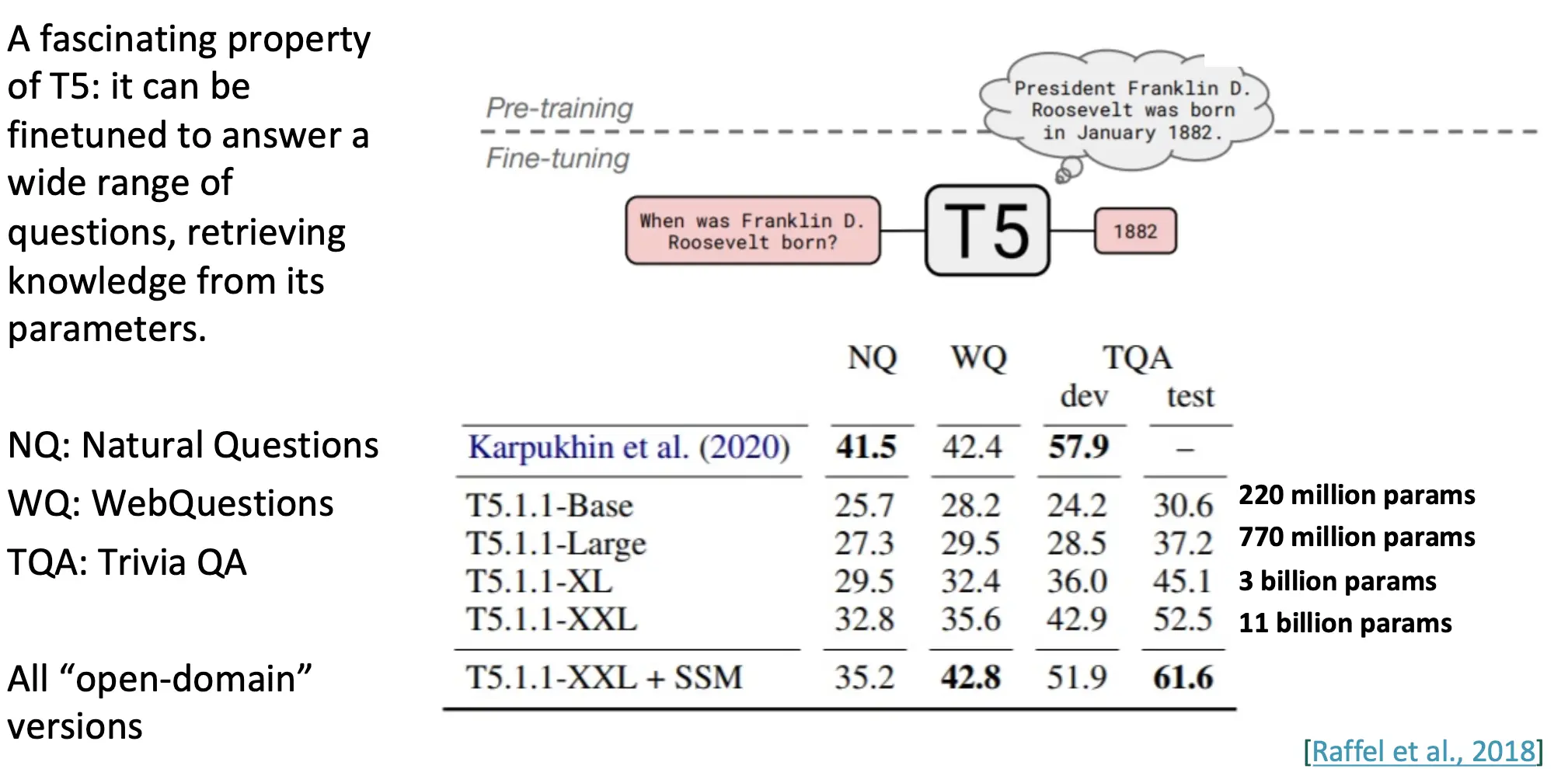
T5的一个很棒的点在于,你可以对一个使用去噪任务pretrained的T5进行fine tune之后用于回答各种类型的问题,而不需要依赖外部知识库。T5 能从其参数中直接检索知识,并生成答案。
Decoder Pretraining
All the biggest pretrained models are Decoders.
你可以很轻松地去fine tune Decoder,通过加一些线性层之类的。
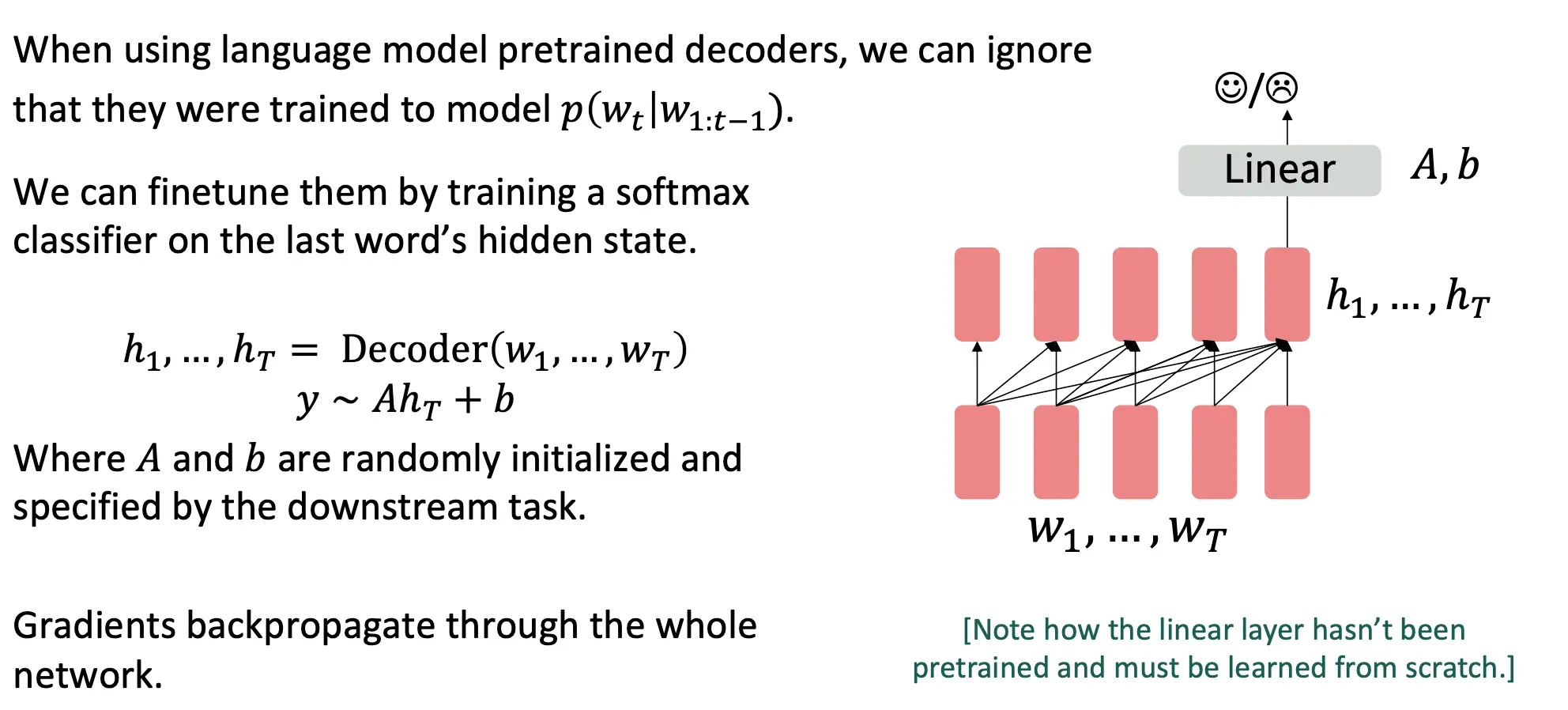
Decoder预训练的任务就可以是LM,这很自然。这就让他具有了对话比较强,总结比较强的天性,因为这些任务都是要输出序列的任务。
GPT: Generative Pretrained Transformer
2018 年的 GPT 在解码器的预训练上取得了巨大成功!
- 使用了具有 12 层的 Transformer 解码器,总共有 1.17 亿(117M)参数。
- 隐藏状态的维度为 768,前馈隐藏层的维度为 3072。
- 使用 Byte-Pair Encoding(字节对编码),进行了 40,000 次合并操作。
- 在 BooksCorpus 数据集上进行训练:包含超过 7000 本独特的书籍。
- 数据集中包含大段连续文本,有助于学习长距离依赖关系。
- “GPT”这个缩写并未出现在原始论文中;它可能代表“Generative PreTraining”(生成式预训练)或“Generative Pretrained Transformer”(生成式预训练 Transformer)。
那么,GPT是怎么用于微调任务的呢?这里来举个Natural Language Inference的例子。
- 目标:给定一对句子,判断它们之间的关系是:
- Entailing(蕴含):假设句子可以从前提句子推导得出。
- Contradictory(矛盾):假设句子与前提句子矛盾。
- Neutral(中立):假设句子与前提句子无直接关系。
 那GPT怎么处理输入呢?
那GPT怎么处理输入呢?
[START] The man is in the doorway [DELIM] The person is near the door [EXTRACT]GPT 模型在处理自然语言推理(NLI)任务时,会将输入的句子对(前提和假设)转换为一个序列,并在序列的末尾添加一个特殊标记 [EXTRACT]。然后,模型会生成这个序列的表示(即将整个序列编码为一个向量表示),并从**[EXTRACT]** 标记对应的表示中提取关键 接下来,通过一个线性分类器(Linear Classifier),对这个表示进行处理,以预测句子对之间的逻辑关系是三种之一.
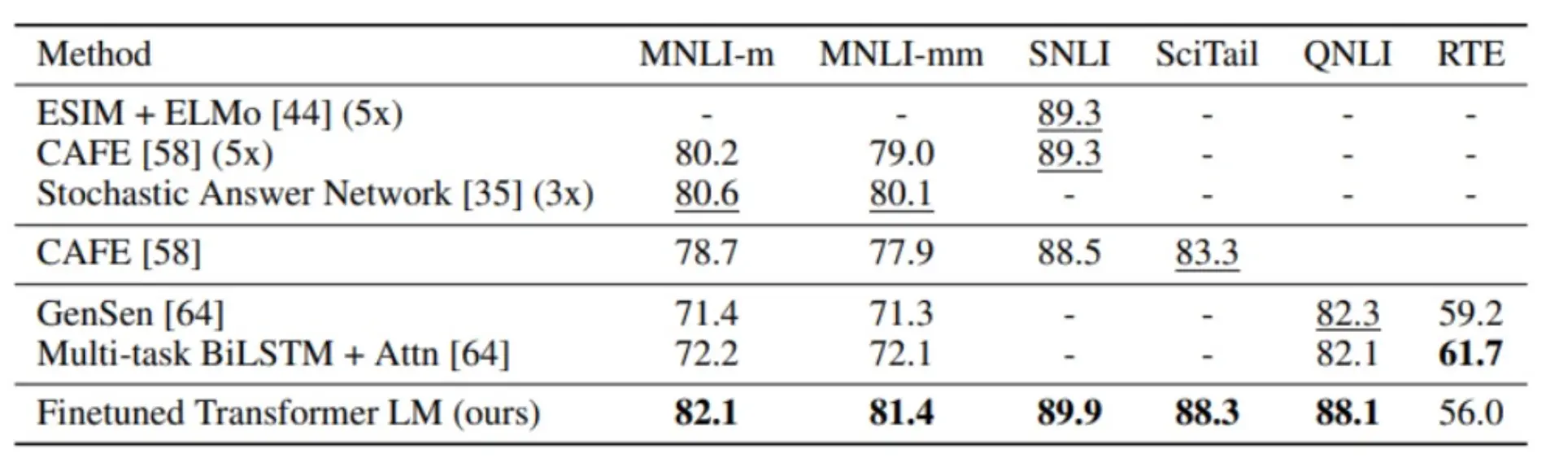
在这个下游任务上,GPT很牛
GPT-2
GPT-2是GPT的一个更大版本(1.5B),经过更多数据训练,显示出能够产生相对令人信服的自然语言样本。 
GPT-3
so far, 我们是怎么用Pretraining Model的呢?主要有两种用法:
- 采样生成,从模型定义的分布中进行采样,可能通过提供一个提示(prompt)来引导生成。例如,输入一个问题,模型生成答案。相当于直接利用了GPT的生成能力,天生就可以
- 微调用于下游任务,模型在特定任务上进行微调,通过梯度下降更新模型参数,使其适应具体任务。需要额外的训练步骤和计算资源,但能够显著提升模型在特定任务上的表现。
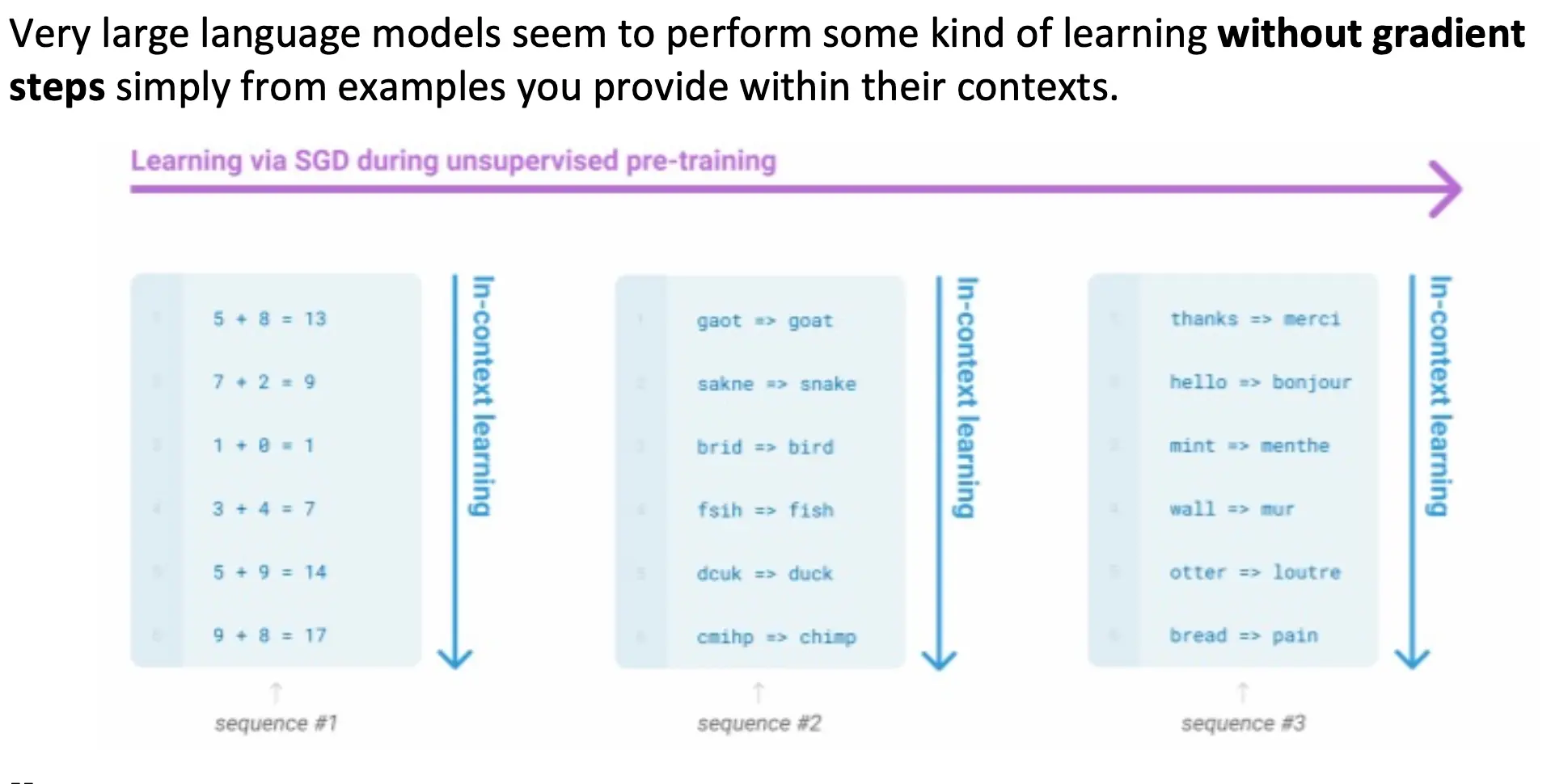
然而,GPT-3的出现带来了一种新用法,也就是In-Context Learning. 超级大的语言模型本身就带有了这种能力。也就是说,你像是采样生成一样给一个prompt,再给一些例子,那么模型在不需要微调的情况下,就能用于下游任务。

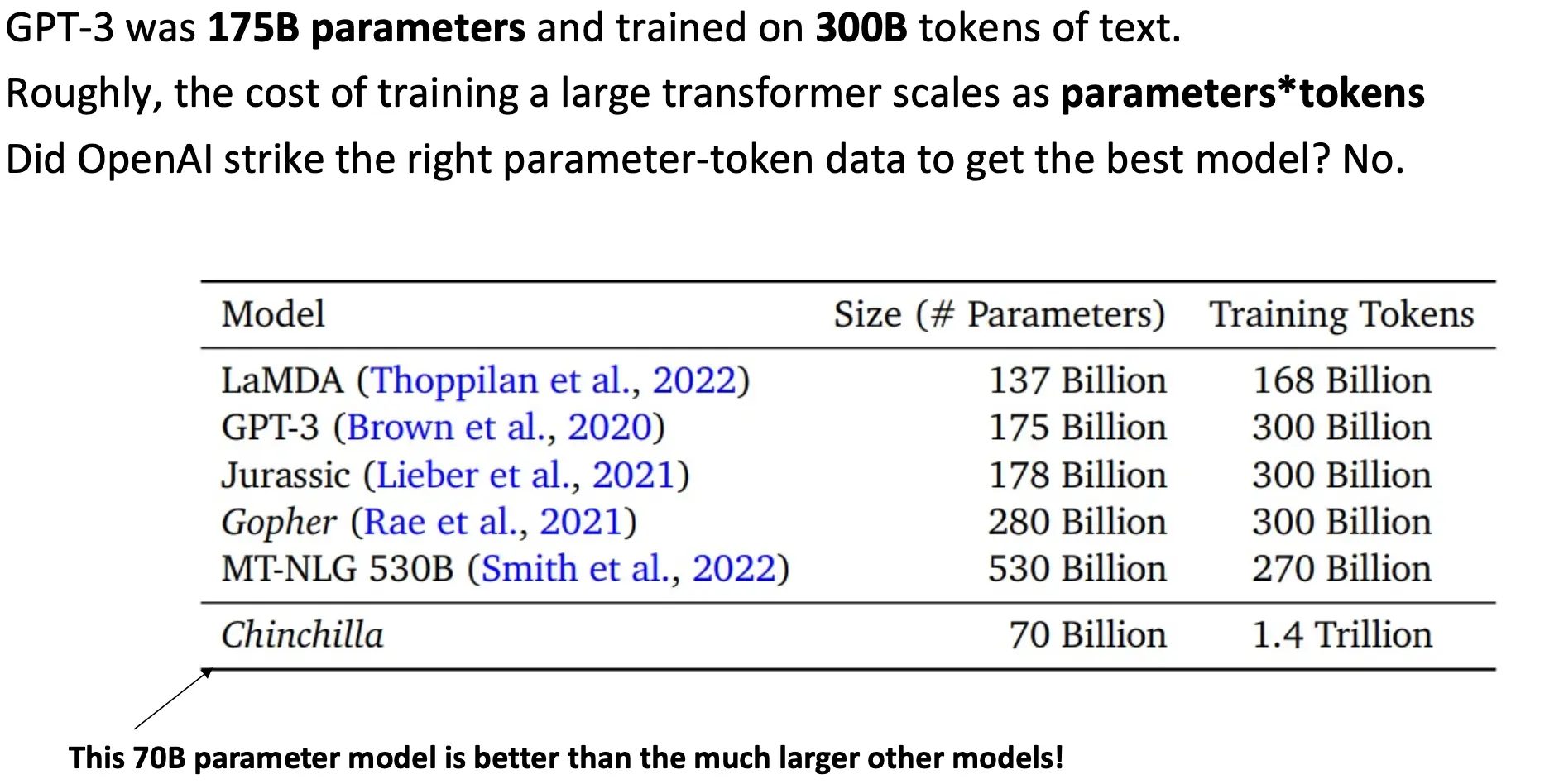
为什么总是提高scale?可以看看我在Transformer第一部分讲的Scaling Laws 7 - Transformer 总结下来的take away就是这几点:
- 扩大模型规模会导致困惑度可靠下降
- 训练一个尚未完全收敛的大型模型
- 可预测的扩展有助于我们对架构等做出明智的决策(公式,可以帮我们判断参数量,token数之间的比例关系,达到最佳应用比例,而不是参数量远大于token数) token其实就是分词分出来的数量。比如说: I am study in university -> I am study in uni 分 versity,那么这句话就是6个tokens 训练大transformer模型的cost基本就是tokens 乘 参数量。如果让二者比例对的话,可以用更少的参数量,更大的tokens数来达到一个更好的效果。
 Larry Shi
Larry Shi