Sequence to Sequence Models and Machine Translation
特征值推导 Vanilla RNN的梯度消失问题
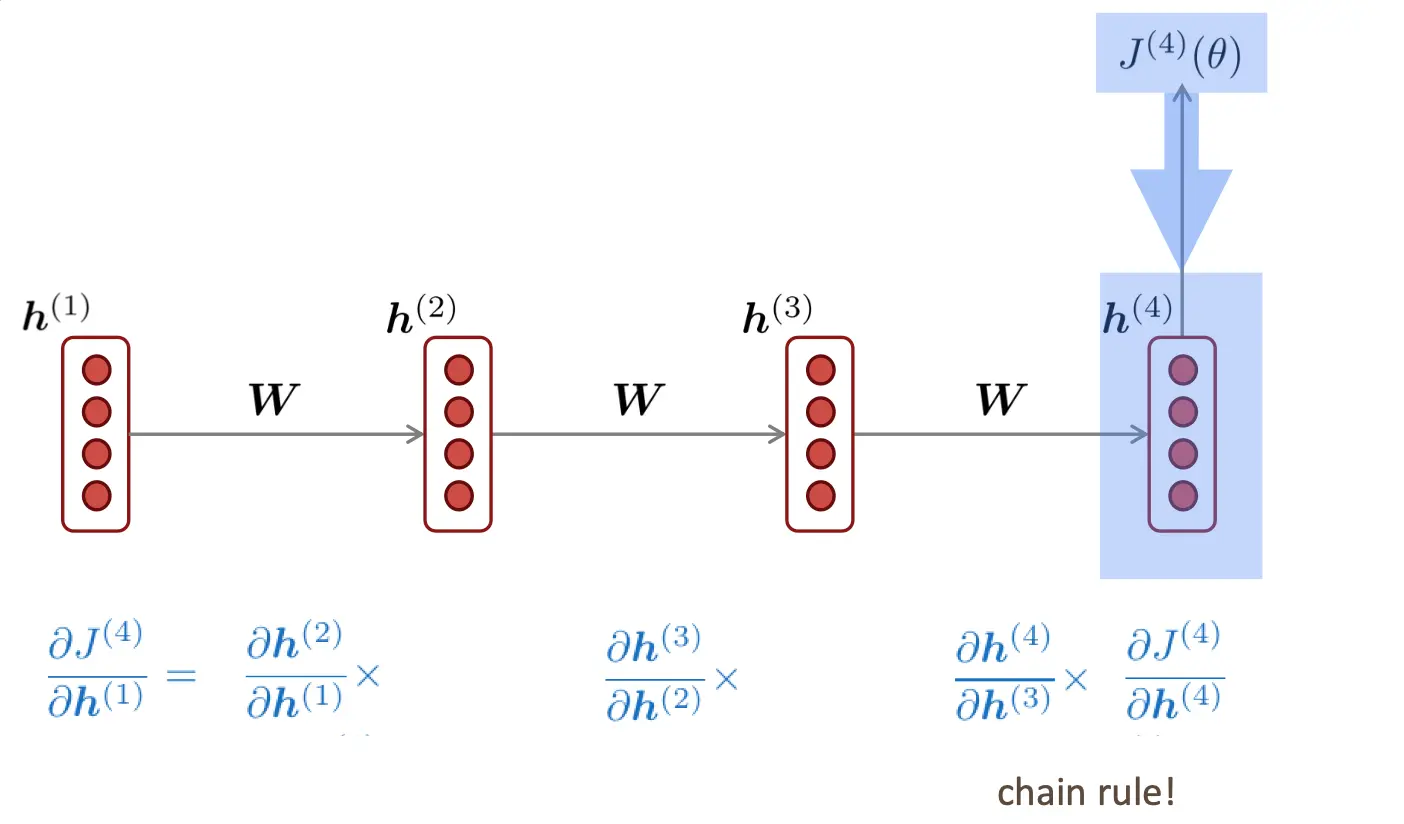 复习一下上次的知识。当J4想要对Wh求导的时候,由于Wh在第一步到第四步是共享的,所以是J对wh|i的加和:
复习一下上次的知识。当J4想要对Wh求导的时候,由于Wh在第一步到第四步是共享的,所以是J对wh|i的加和:
而当我们要计算
这里面就要用到
那么就是:
为什么会出现diag?慢慢来. 我们令:
那么
后半部分好说,就是Wh, 前半部分呢?由于sigma是逐个用在元素上的,所以h向量对z向量的偏导,就是一个jacobian矩阵:
所以就有上面的diag。 之后,为了简便运算,我们将sigma看为线形的恒等函数,那么diag就变成了eye矩阵了。所以有
之后,根据距离,就会有指数的堆积:
然而,你没法说Wh small,这是不严谨的,所以其实还能往下推。首先回忆一下特征值。对于矩阵
那么
这很直观。接着,对于任意向量x,其实都可以被q线性表示:
于是就有:
所以,我们说Wh小,不是说Wh某个元素小,而是特征值小。这样就能看出梯度消失:
这里我们把激活函数看成线形的了,但如果不是线性的,特征值的放缩仍然起主导作用。特征值需满足
我们可以用分开的记忆去做这件事。
LSTM
LSTM 是一种特殊类型的递归神经网络(RNN),1997年提出,专门设计用来解决 梯度消失问题,从而更好地捕获长期依赖信息。 LSTM 的设计通过“门机制”(如输入门、遗忘门和输出门)来有选择地保留或丢弃信息,从而解决了权重矩阵幂次导致梯度消失的问题。
TIP
现代 LSTM 的一些关键改进来自于 Gers 等人在 2000 年的工作,他们在原始模型上提出了重要的扩展,例如“遗忘门”的引入。 然而,其在2006年才被广泛关注。原因是Alex Graves 的研究引入了 CTC(Connectionist Temporal Classification),用于处理语音识别等序列学习任务。CTC 的发明极大地拓展了 LSTM 在实际应用中的能力。 LSTM 真正开始“爆火”是在 2013 年,当 Geoffrey Hinton 将其引入 Google 的语音识别系统后。这是因为 Alex Graves 在 Hinton 的团队中完成博士后研究。通过 Hinton 的推广,LSTM 被成功应用于工业界,特别是在大规模语音识别任务中展现了卓越的性能。
设计
不同于vanilla RNN,其有两个state。 在t步时,有hidden state
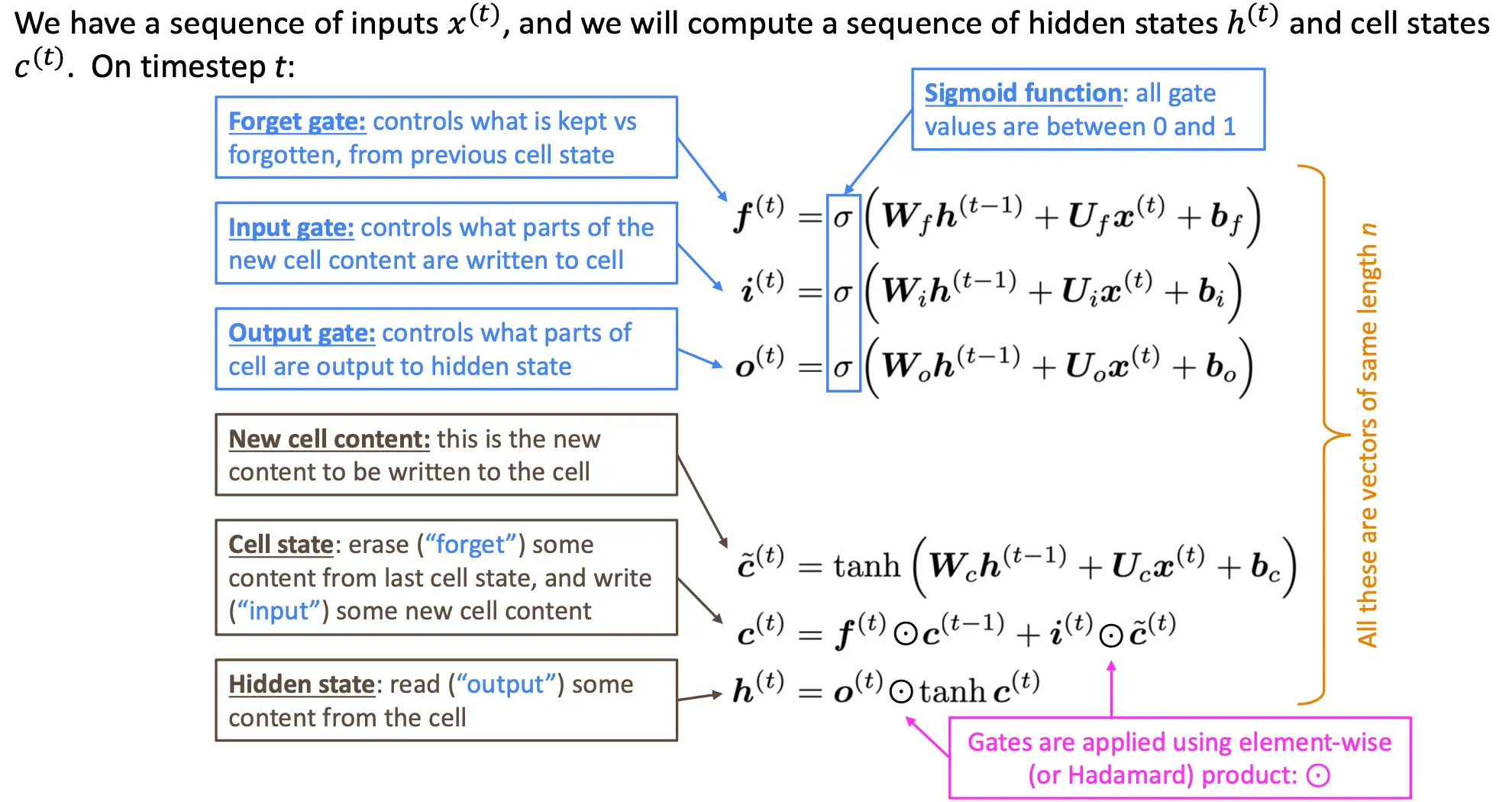 接下来看其结构:
接下来看其结构: 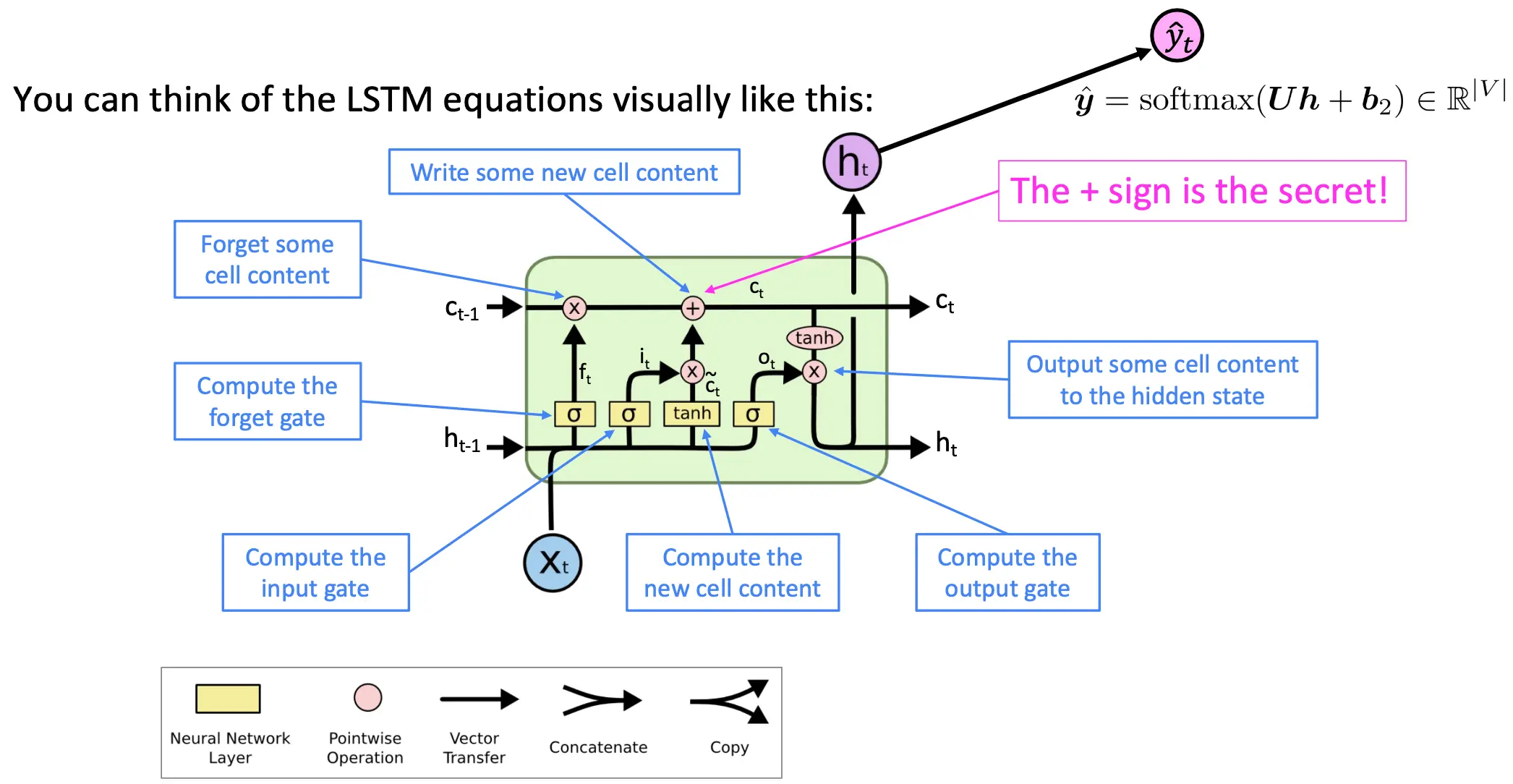 接下来看一下为什么说LSTM解决了梯度消失的问题。
接下来看一下为什么说LSTM解决了梯度消失的问题。
梯度推导
参考:How LSTM networks solve the problem of vanishing gradients
RNN中梯度爆炸的原因是我们需要计算递归导数
那么
代入导数,就是:
那我们把这四项记为At Bt Ct Dt. 那么损失函数Ek对W的导数就可以记为:
可以看到,其实ACD都会比较小,因为乘了一堆激活函数。但是B不会,因为B是ft,而ft在0到1.所以ft想忘,那么A+B+C+D -> B就小了,梯度就没了。如果ft不想忘,那么A+B+C+D -> B就大了,梯度就又有了。 你也许会说,那ft如果小的话,地图不还是消失吗?是的,但是没关系。因为ft的作用是遗忘,如果ft小的话,网络也认为该遗忘了,所以遗忘了没事。如果大的话,不该遗忘的时候就不会消失。
梯度消失专题
梯度消失/爆炸并不是RNN特有的问题。只不过RNN是最不稳定的罢了。它可以发生在所有类型的神经网络架构中,包括前馈网络(Feedforward)和卷积神经网络(Convolutional Neural Networks, CNN),尤其是在非常深的网络中。 链式规则和非线性激活函数的选择可能导致梯度在反向传播中逐渐变得非常小(梯度消失)或者非常大(梯度爆炸)。因此,底层的层学习得非常慢,导致训练困难。 解决方法:
- 残差连接(Residual Connections,ResNet)
- DenseNet(密集连接网络):每一层直接连接到所有未来层,确保信息和梯度可以无障碍地流动。
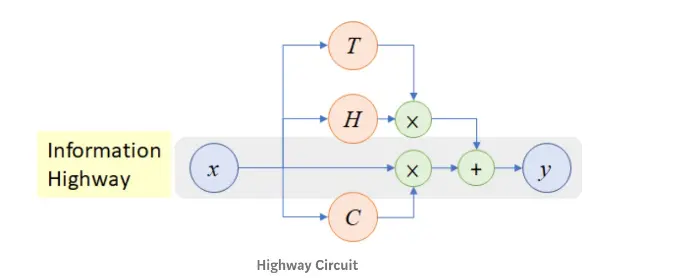
- HighwayNet(公路网络)类似于残差连接,但身份连接和变换层之间通过动态门控机制进行控制。灵感来源于LSTM的门控机制,但用于深度前馈网络或卷积网络。
RNNs其他用途
单词标签: 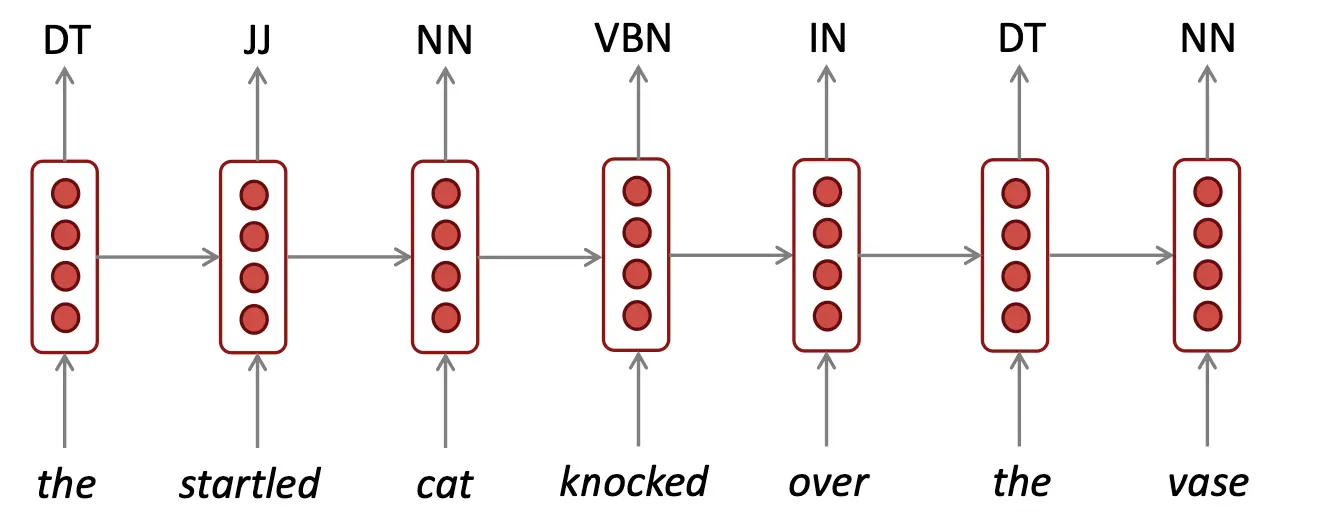 用作嵌入模型
用作嵌入模型 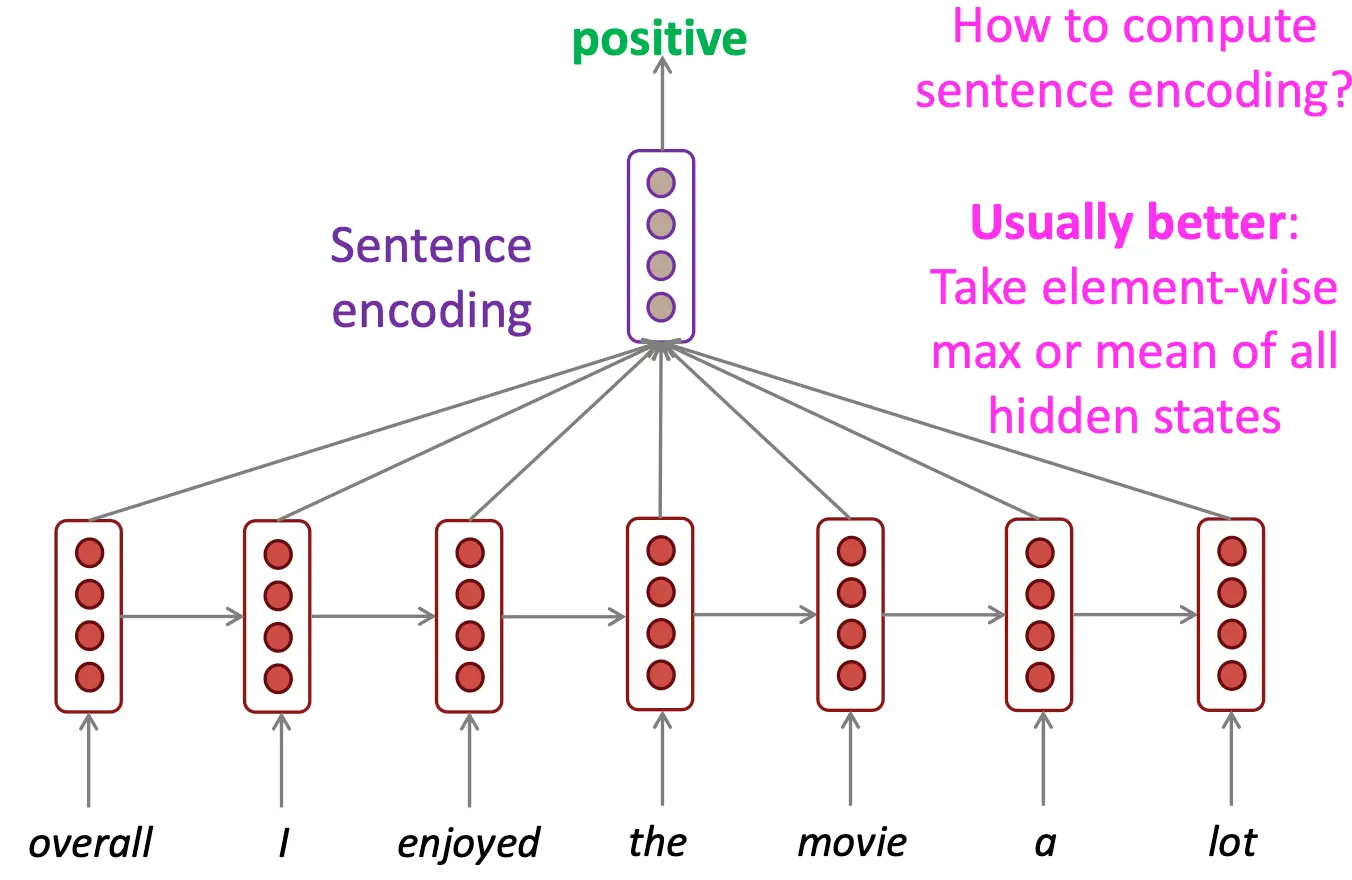
条件语言模型做语音识别 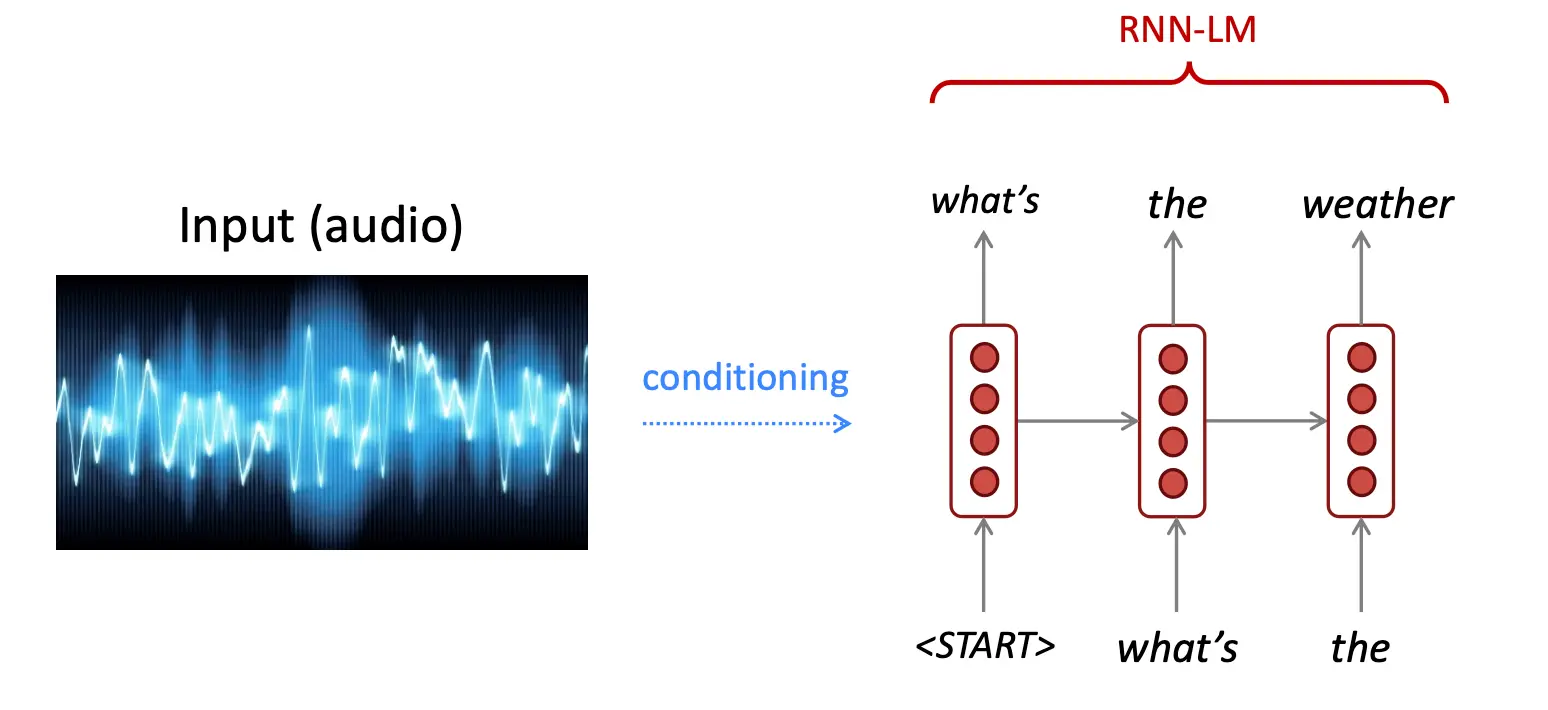
双向RNNs
在传递的过程中,ht只包含t之前的信息,而t之后的信息是没有包含的。 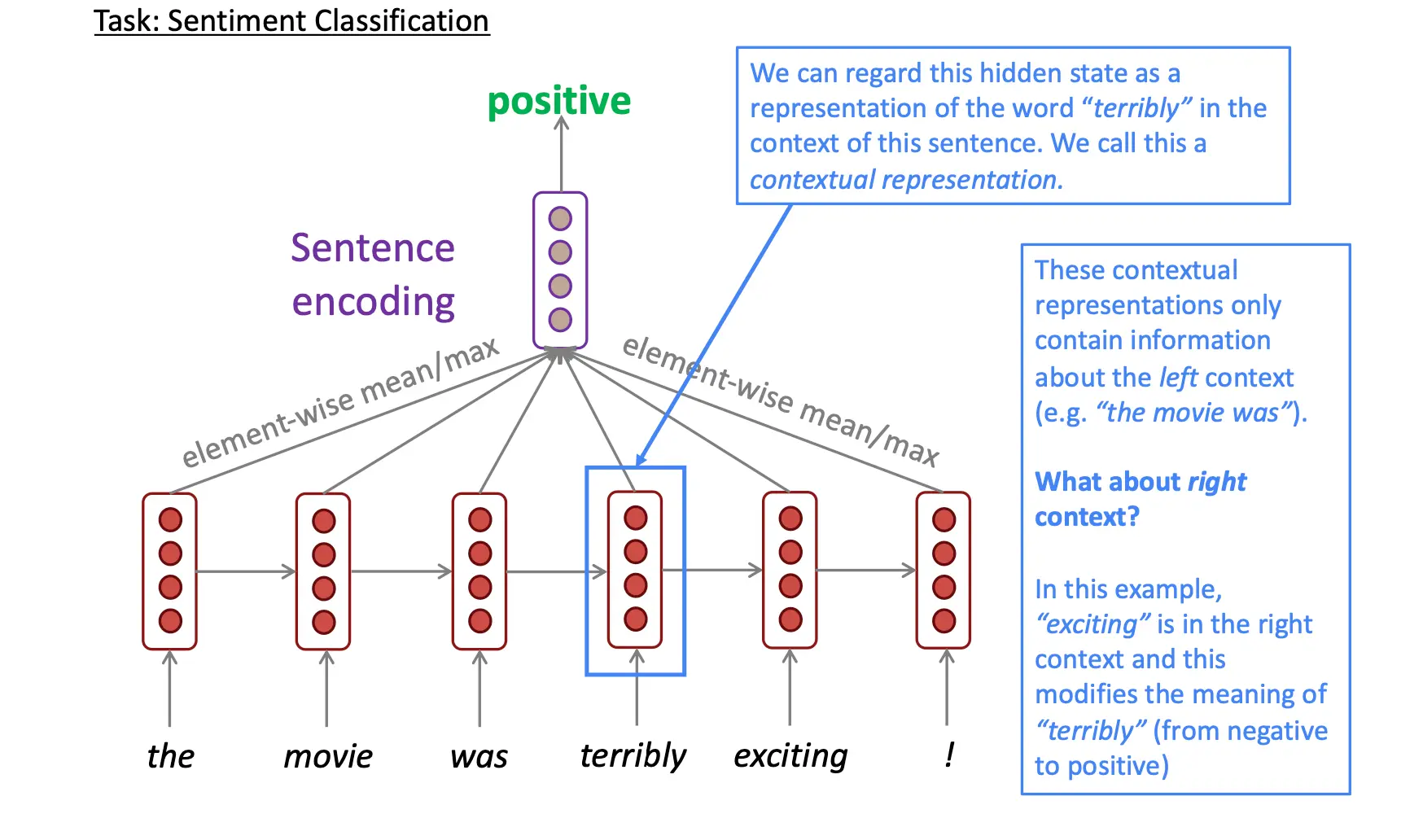 如果想要包含,就要双向rnn:
如果想要包含,就要双向rnn: 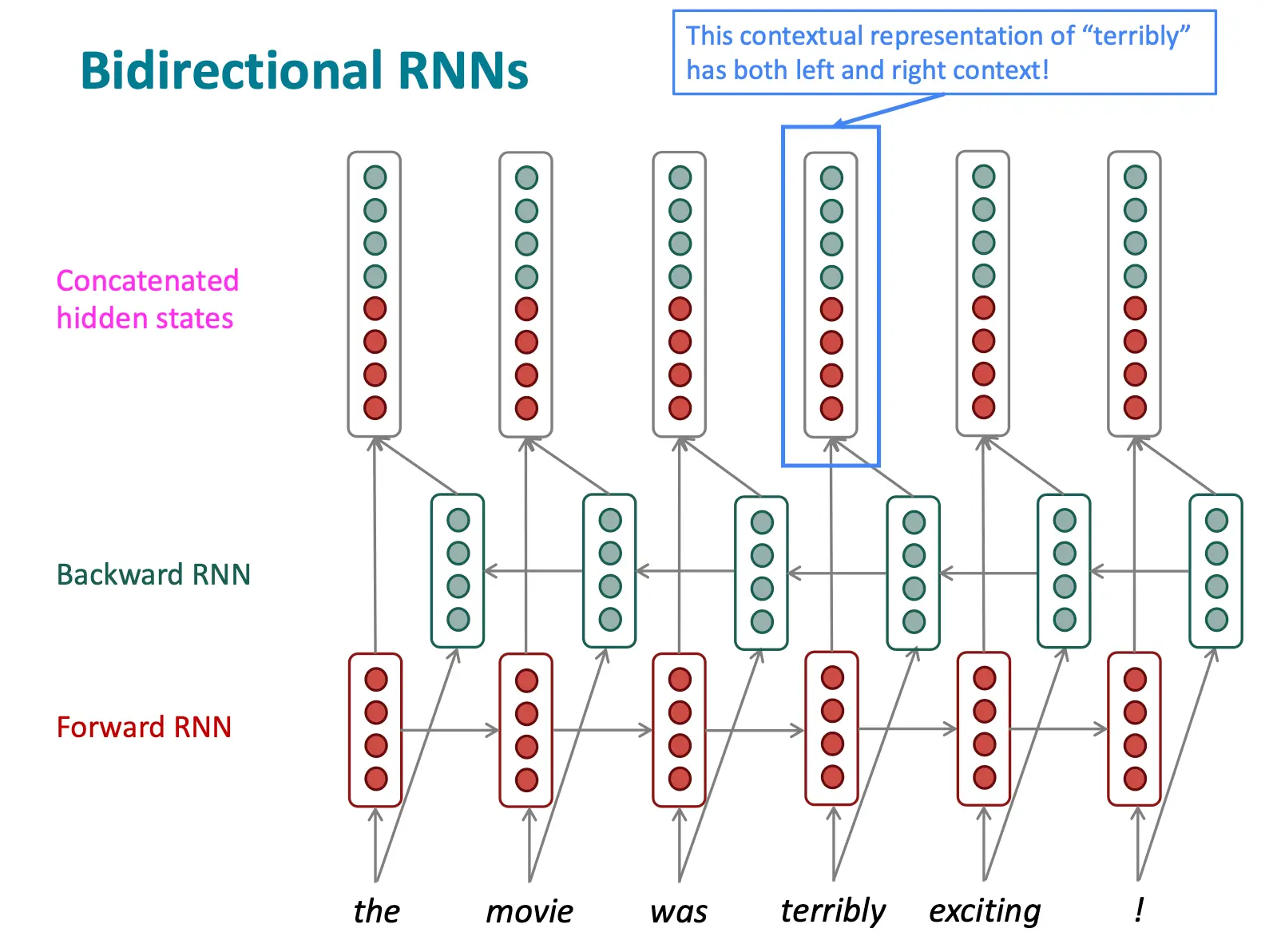 公式表示是这样的:
公式表示是这样的:
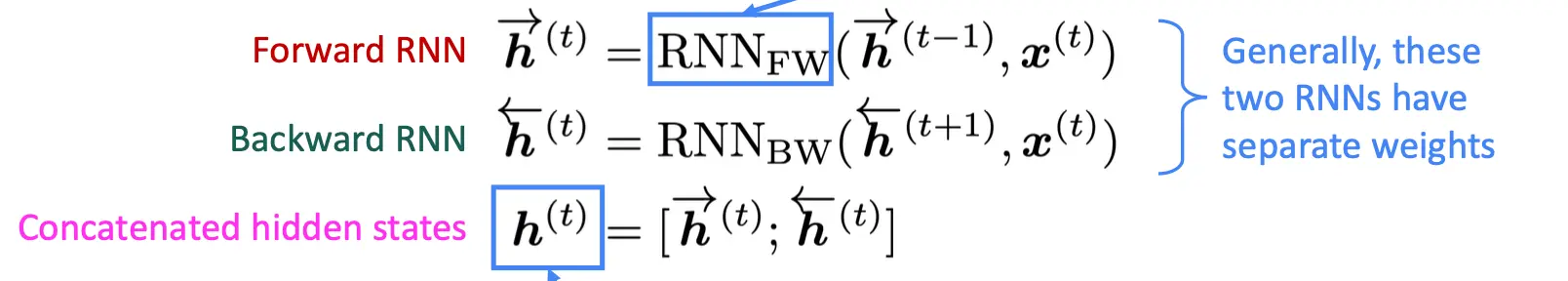
注意:只有在可以访问整个输入序列时才适用。不适用于语言建模(Language Modeling, LM),因为在语言建模任务中,模型通常只能使用左侧上下文(即过去的信息),而不能访问完整的输入序列。 但当你想要embedding的时候,双向RNN就很棒,可以默认使用双向RNN。BERT默认就用的这个。
多层RNNs
较低层的RNN应该计算较低级别的特征,而较高层的RNN应该计算较高级别的特征。
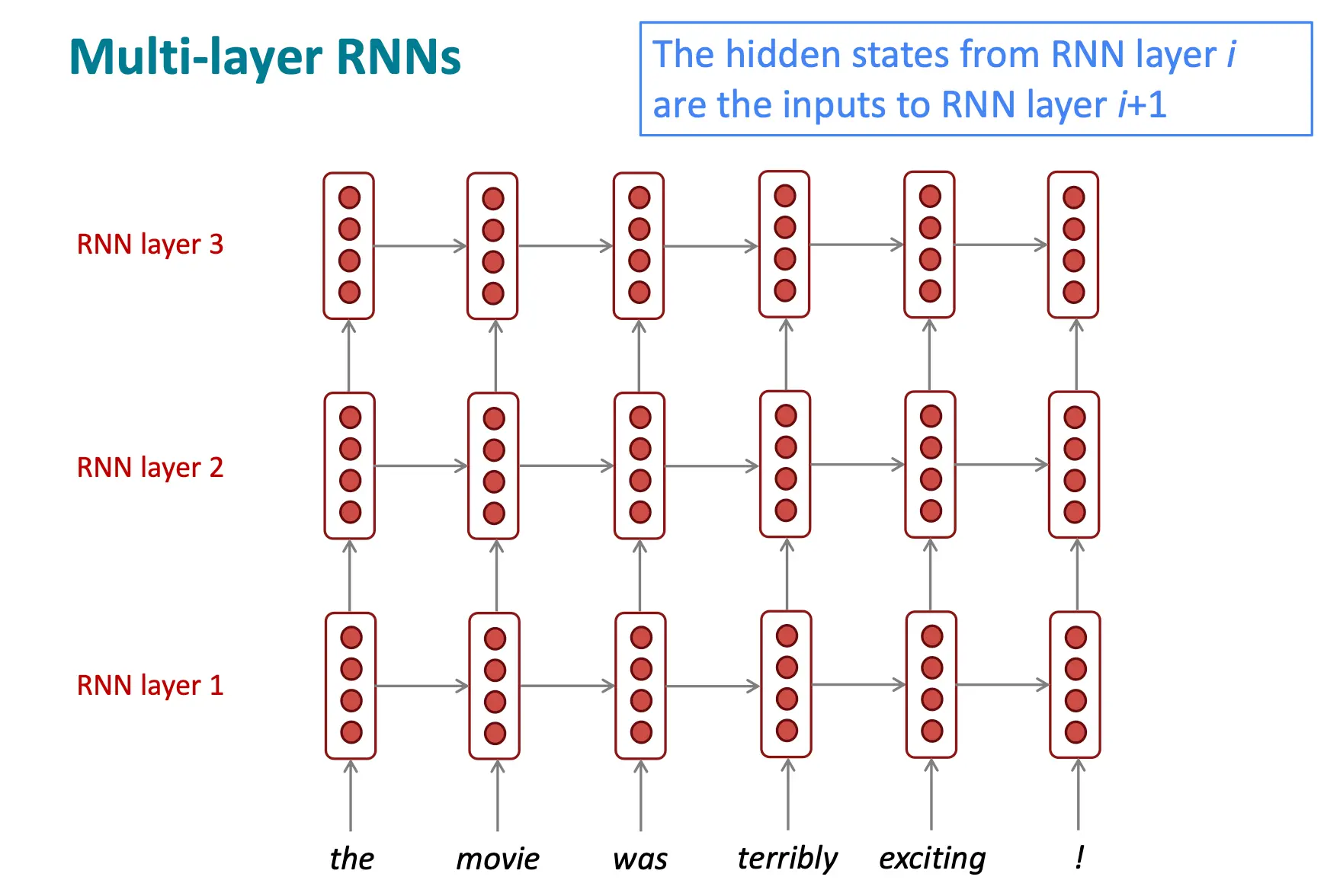 多层RNN允许网络计算更复杂的表示,比单层的高维度encoding效果要好 高性能的RNN网络大多都是多层的,只不过没有CNN或者FF那么深 比如说,2017 Britz et al的文章表示在机翻任务重,2-4层是RNN encoder的最佳层数,4层是RNN decoder的最佳层数。
多层RNN允许网络计算更复杂的表示,比单层的高维度encoding效果要好 高性能的RNN网络大多都是多层的,只不过没有CNN或者FF那么深 比如说,2017 Britz et al的文章表示在机翻任务重,2-4层是RNN encoder的最佳层数,4层是RNN decoder的最佳层数。
- 2层一般比1层好很多,但3层可能只比2层好一点
- 深层的RNN训练需要skip connections / dense connections (例如8层RNN) Transformer 网络中有大量类似跳跃连接的机制,后续会进一步学习。
2013-2015年,LSTM达到SoTA,如手写识别,语音识别,机翻,parsing,图像字幕。但2019-2014年,Transformer主宰了整个NLP任务。
机器翻译
机器翻译的研究始于20世纪50年代初,这一时期的研究发生在“人工智能”(A.I.)这一术语被创造之前。 机器翻译的研究得到了军事领域的大量资助,早期的机器翻译系统基本上是基于简单规则的系统,主要通过单词替换来完成翻译。 语言的复杂性远超简单的单词替换,且在不同语言之间差异巨大。
统计机器翻译
在1990s到2010s,机翻的方法来源于统计学习。 给定目标语言y,以及原语言x,根据贝叶斯公式,就有:
前面的P(y|x)是最终的翻译器模型,给定原语言给出目标语言,而后面的P(x|y)是给定目标语言翻译原语言,这其实不矛盾,因为这是一个语义对齐的过程。而P(y)代表了正常目标语言的分布,保证生成的目标语言是符合语法的。 你大概可以想象到,维护这样一个系统有多复杂,有多少特征工程,以及人力消耗。
神经网络机器翻译
seq2seq模型在机翻任务中表现出众。 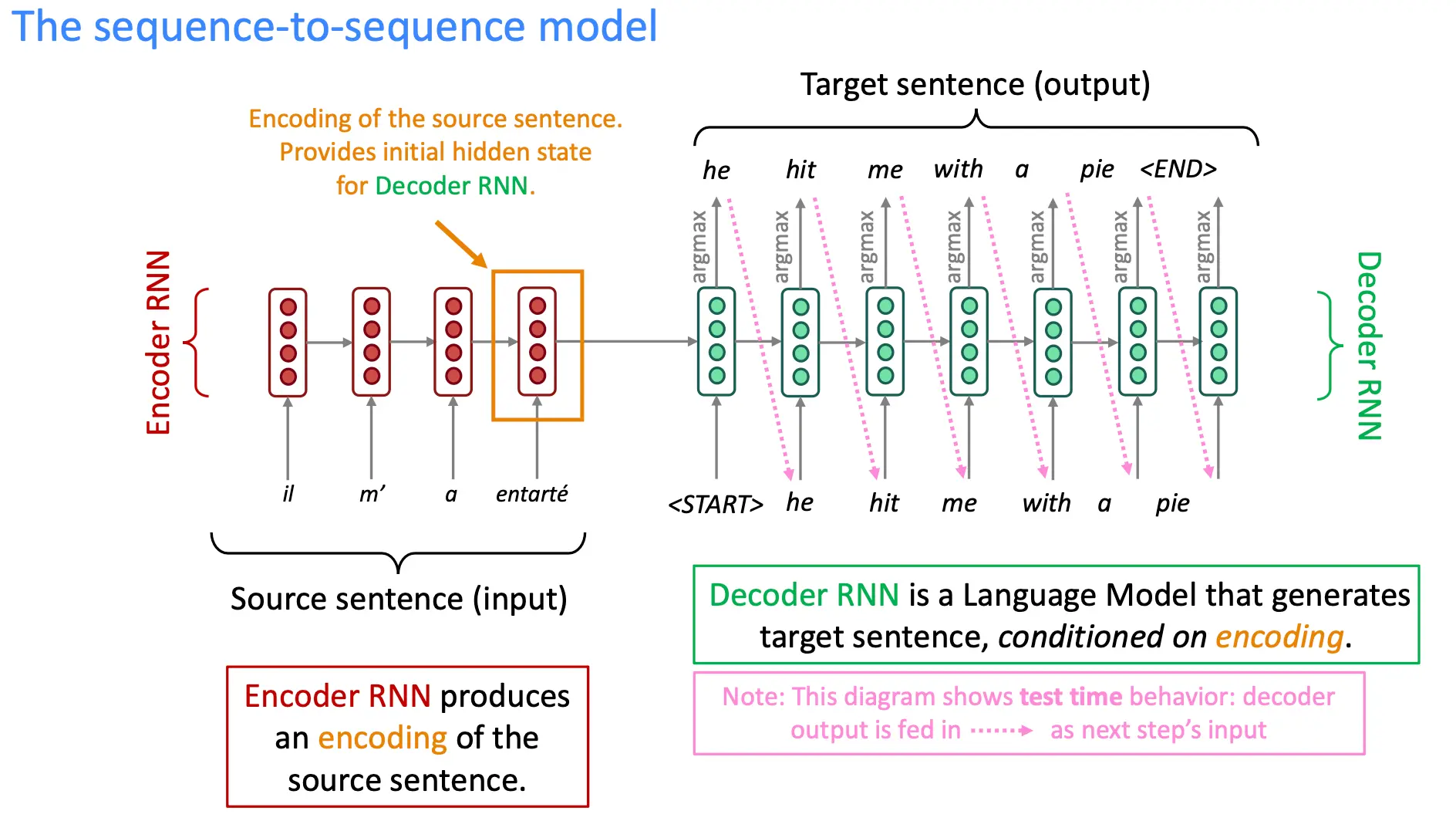
上面是测试时的架构。如果要训练的话,要用teaching force: 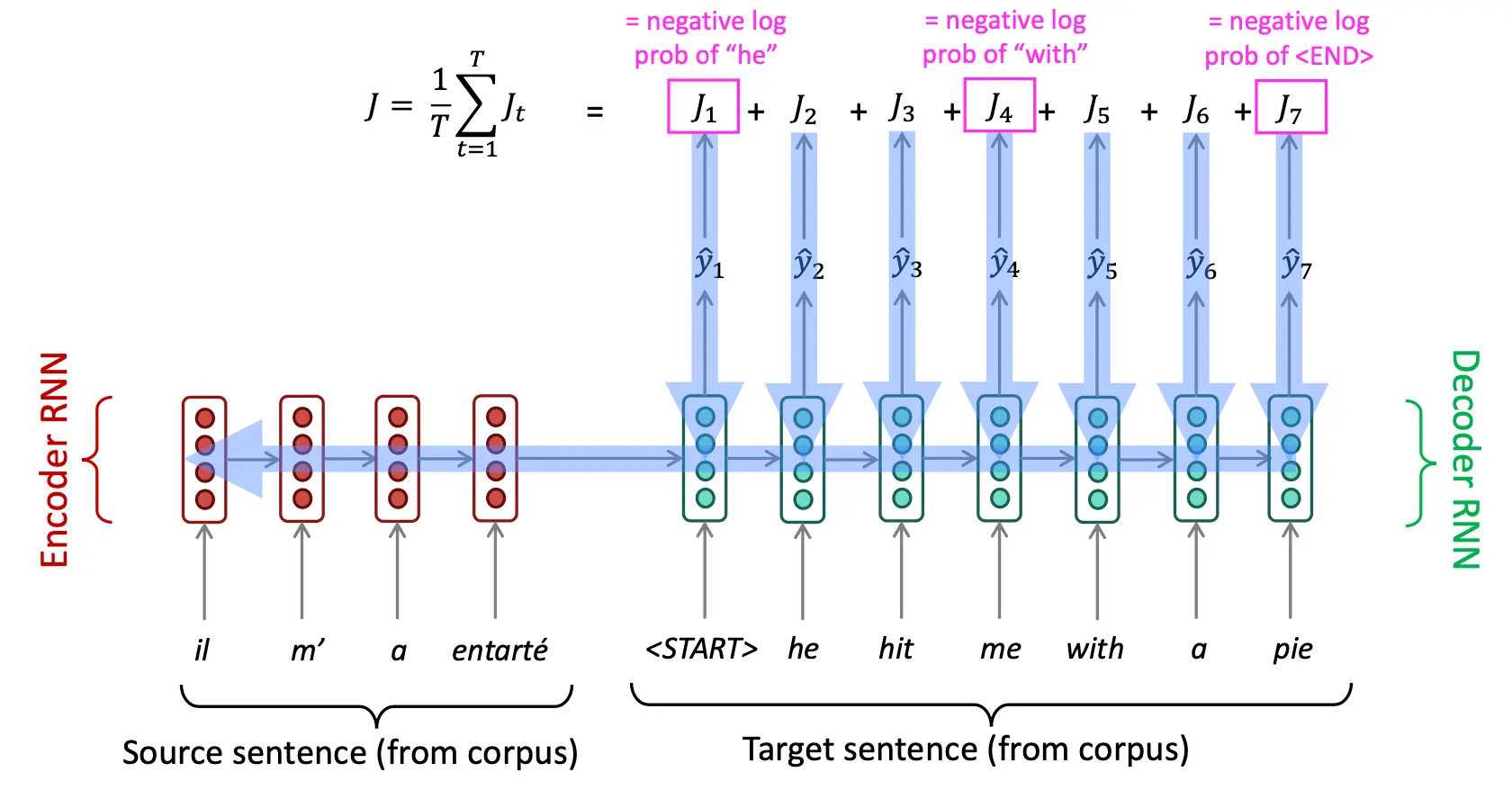
seq2seq的一个general notion是encoder decoder结构 一个网络用语将输入转化成一种神经表示,而另一个网络负责处理神经表示得到输出。 seq2seq在多项任务上都不错:
- 总结(长文 -> 短文)
- 对话
- parsing
- 代码生成
同时,seq2seq模型是一个 条件语言模型的例子,因为他是基于source sentence X做的
每一项 P(yt∣y1,…,yt−1,x)表示在给定源语言句子 x 和目标句子中已生成单词 y1,…,yt−1 的情况下,生成下一个单词 yt 的概率。 传统训练方法是使用大量的双语平行语料(源语言和目标语言的成对句子)来训练模型。 而近期非监督 NMT(Unsupervised NMT)成为研究热点,使用未对齐的单语数据和数据增强等技术来训练模型。
条件语言模型的优点是,直接建模P(y|x),而不是像贝叶斯方法一样建模P(x|y) 以及P(y)。而且端到端训练,能够更好地捕捉源语言和目标语言之间的复杂关系。
Multi-layer deep encoder-decoder machine translation net 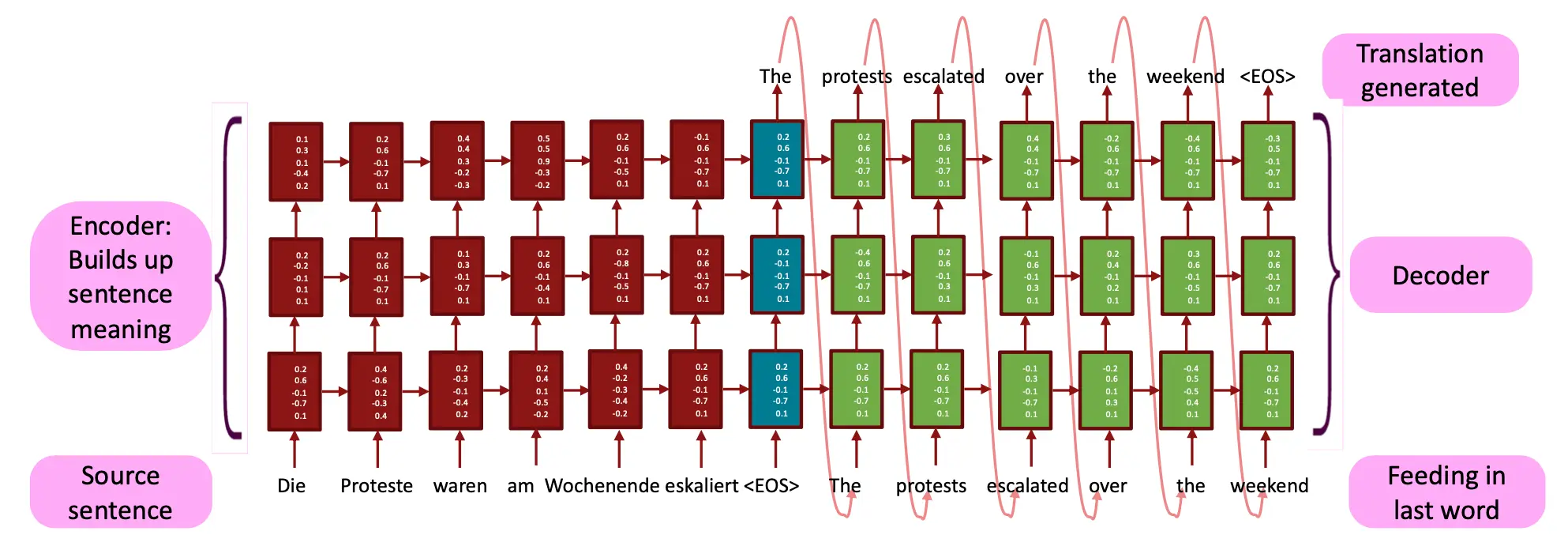 这里可以看到,conditioning,也就是对原文的编码可以算是bottleneck,成为了瓶颈,因为这么小的向量肯定让数据失真了。后续的注意力机制(Attention)被引入来缓解这一问题。
这里可以看到,conditioning,也就是对原文的编码可以算是bottleneck,成为了瓶颈,因为这么小的向量肯定让数据失真了。后续的注意力机制(Attention)被引入来缓解这一问题。
 Larry Shi
Larry Shi