Word Vectors
Word Vectors简介
Q: 以前的NLP是怎样让计算机中反映出词汇的意义呢?
A:
使用一个专家库如WordNet,其中包含了synonym set同义词集和hypernyms上位词。 缺点挺多的,比如需要人力,主观,缺少新意思,且在某些语境下可能不对。

one-hot向量表示词语
的确能表示了,但是太稀疏,且由于每个词的独热向量是正交的,所以无法衡量词之间的相似度。

现代做法:Word Vectors
理论依据是分布语义学:一个词的含义由经常出现在附近的词给出。You shall know a word by the company it keeps
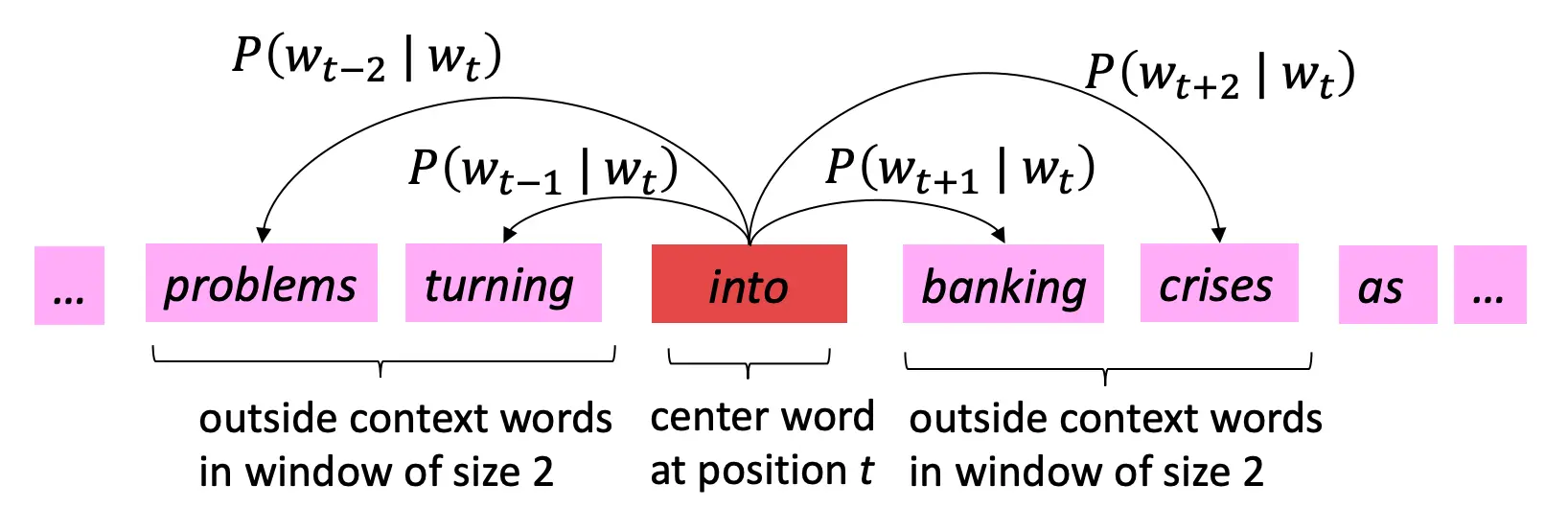
当一个词w出现在text中,它的context是它左右一个固定size的window中的词 
 可以看到,上下文确实给出了banking的意思。
可以看到,上下文确实给出了banking的意思。
所以我们希望,通过w的context,构建一个dense vector去embedding每个词。另外,我们也希望意义相近的词,通过向量的点乘,我们希望其得分更高,得分反应相似度。
Skip-gram, CBOW
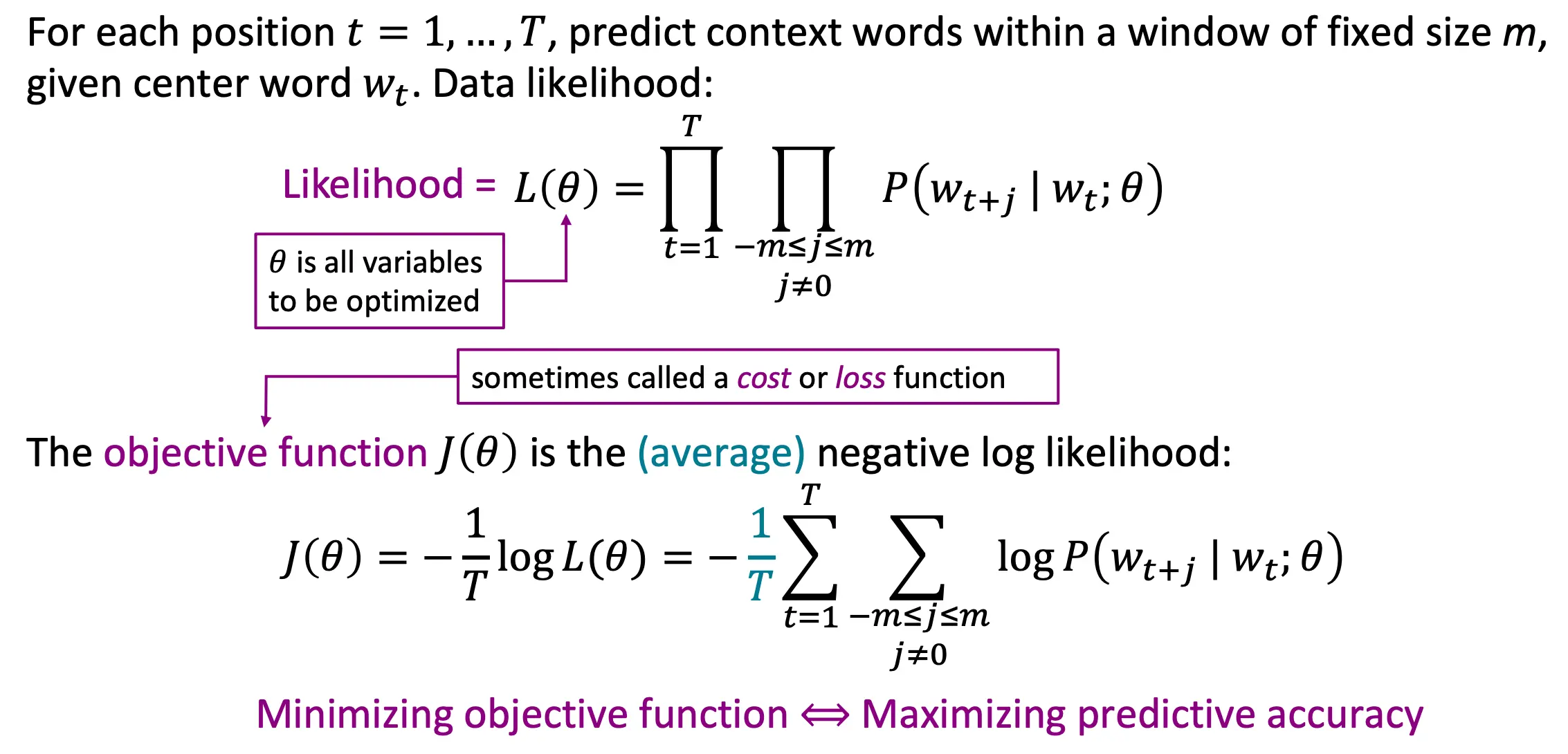
Word2Vec的思想是,由于一个词的意思可以通过其周围的词得到,那么反过来,当一个中心词出现的时候,周围几个词出现的概率也应该最大(这个是skip gram的想法,cbow的想法正好反过来,是用p(Wt|Wt+2))。
为了概率最大,很自然就想到了似然函数,以及常用的取对数简便运算的方法。
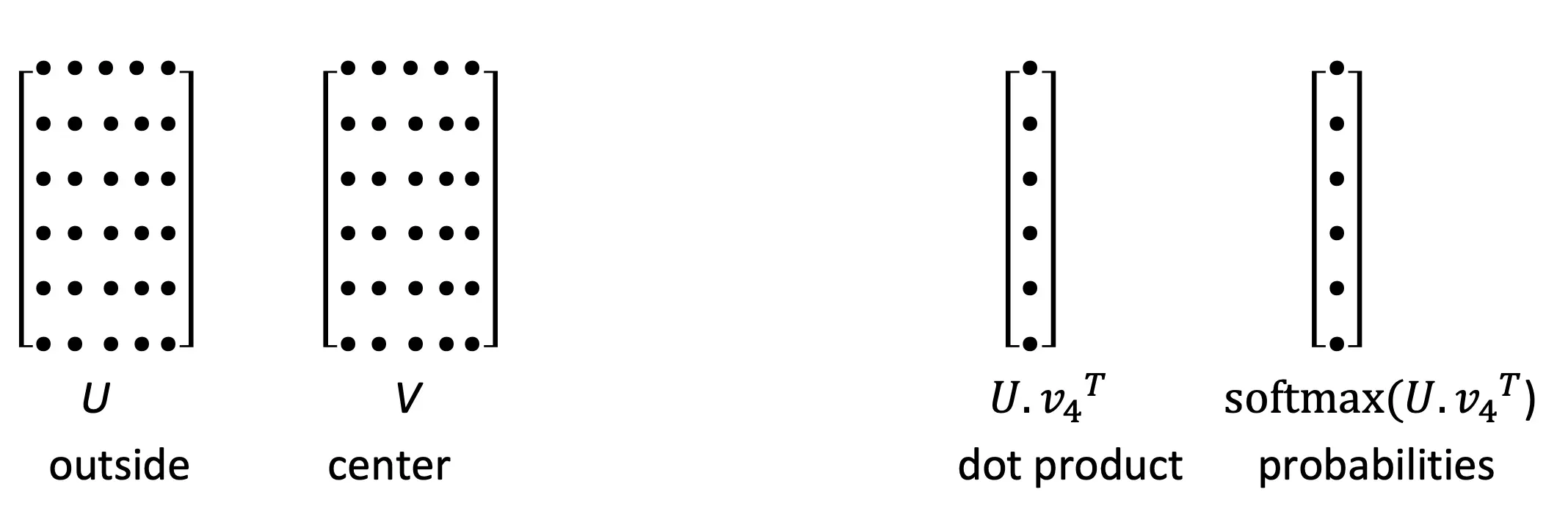
那么,P怎么算的呢?这里定义v_w是w做中间词的时候的词向量,u_w是w做上下文的时候的词向量。那么P就有利用softmax这样的定义: 注意,这里面的V大概率是你的语料库所有词。

这样,之后做梯度下降就可以了! 从向量化的角度看,就是这样计算的
这种做法之下,我们用V和U的平均值当作词向量,那么similar words在向量空间中的距离就会变近。 为什么要用两个向量?Easier optimization. 用于训练的损失函数:
- Naïve softmax(简单但昂贵的损失函数,在有许多输出类别时),上面讨论的就是这个,负log。
- 更优化的变体,如分层softmax
- 负采样 negative sampling
Negative Sampling
上面我们看到,分母那个巨大的加和乘法,计算量巨大,所以会有负采样。 负采样的想法是,我们不去管分母那个了,因为太大了。我们只去管context中,这些context的出现概率应该接近1,而不在context中的词,我们希望出现概率接近0。我们只需要采样几个不在context里面的词就可以
-log之后就变成优化最小了,所以前半部分随着优化会变小,后半部分由于也要变小,所以加负号。 这里我们用了sigmoid函数做激活,也是为了转为概率。 那么这些非context的点是怎么取出来的呢?就是靠采样,怎么采? 采样用了 P(w) = U(w)^3/4 / Z, 这里U是unigram分布。这样取power,可以让低频的词多被采样到。 这样需要优化的东西,就只有2m+1个词(m是半个窗口),以及2km个负采样,k是一个超参数。这样,梯度计算就很简单稀疏了。
co-occurrence counts做embedding
为什么我们不直接统计中心单词左右窗口内词出现的频率做embedding?就像这样:
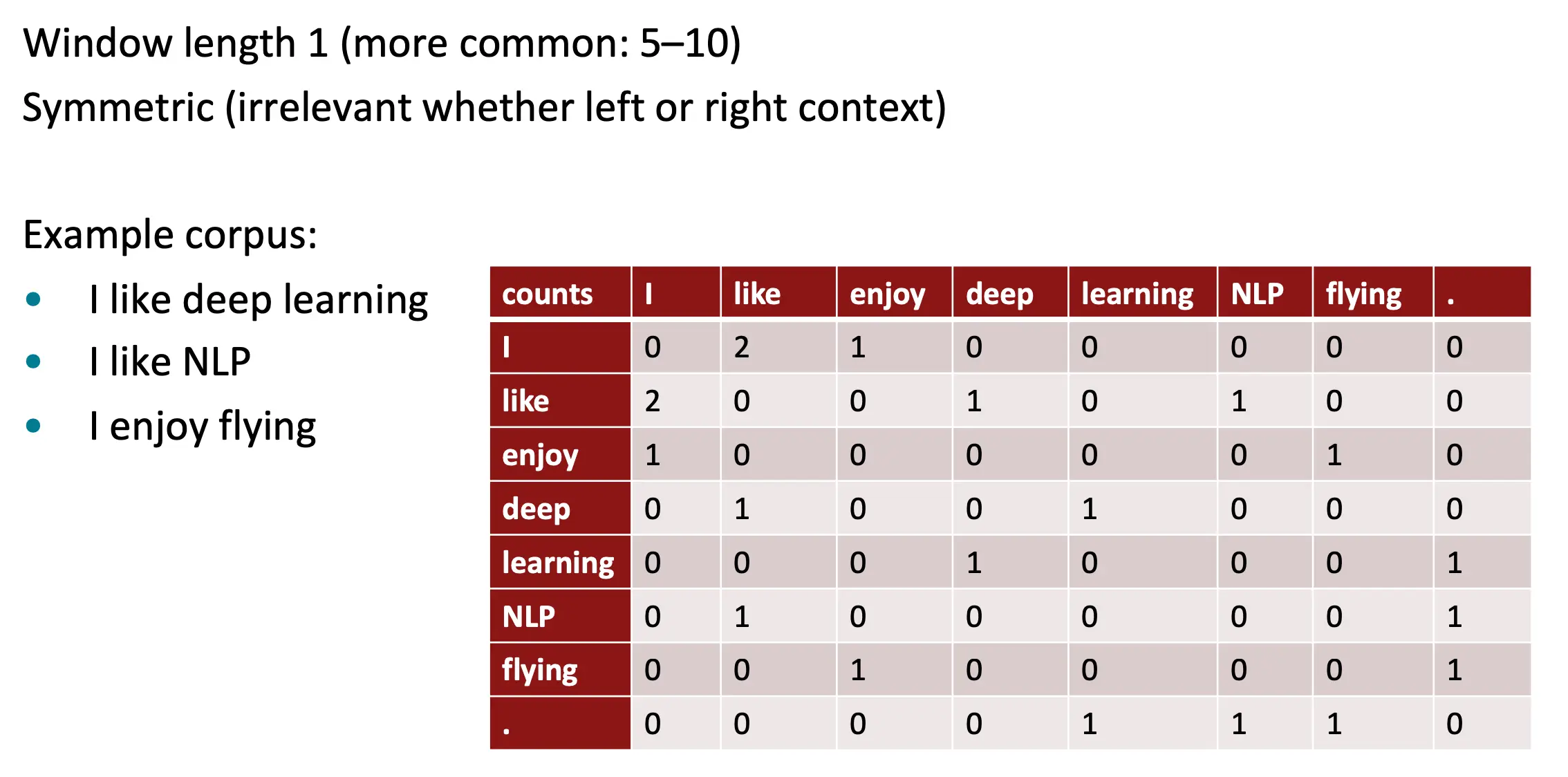
这就有一点问题。可以看出,vocabulary一边大,那么vector的size就会跟着变大,高维且稀疏,模型就不robust 那么接下来就是要降维度了。怎样才能做到vector稠密化呢?
经典方法:SVD分解
UV都是正交归一矩阵(即列向量为单位向量且正交)。 sigma是对角矩阵,其中对角线上的值为奇异值(表示矩阵的主要特征)。 降维的关键就在于,我们只保留前k个sigma,也就是只保留前k个奇异值 那么U和V的列向量就也只能截断到k维 但是,对于大规模矩阵,SVD 的计算成本较高。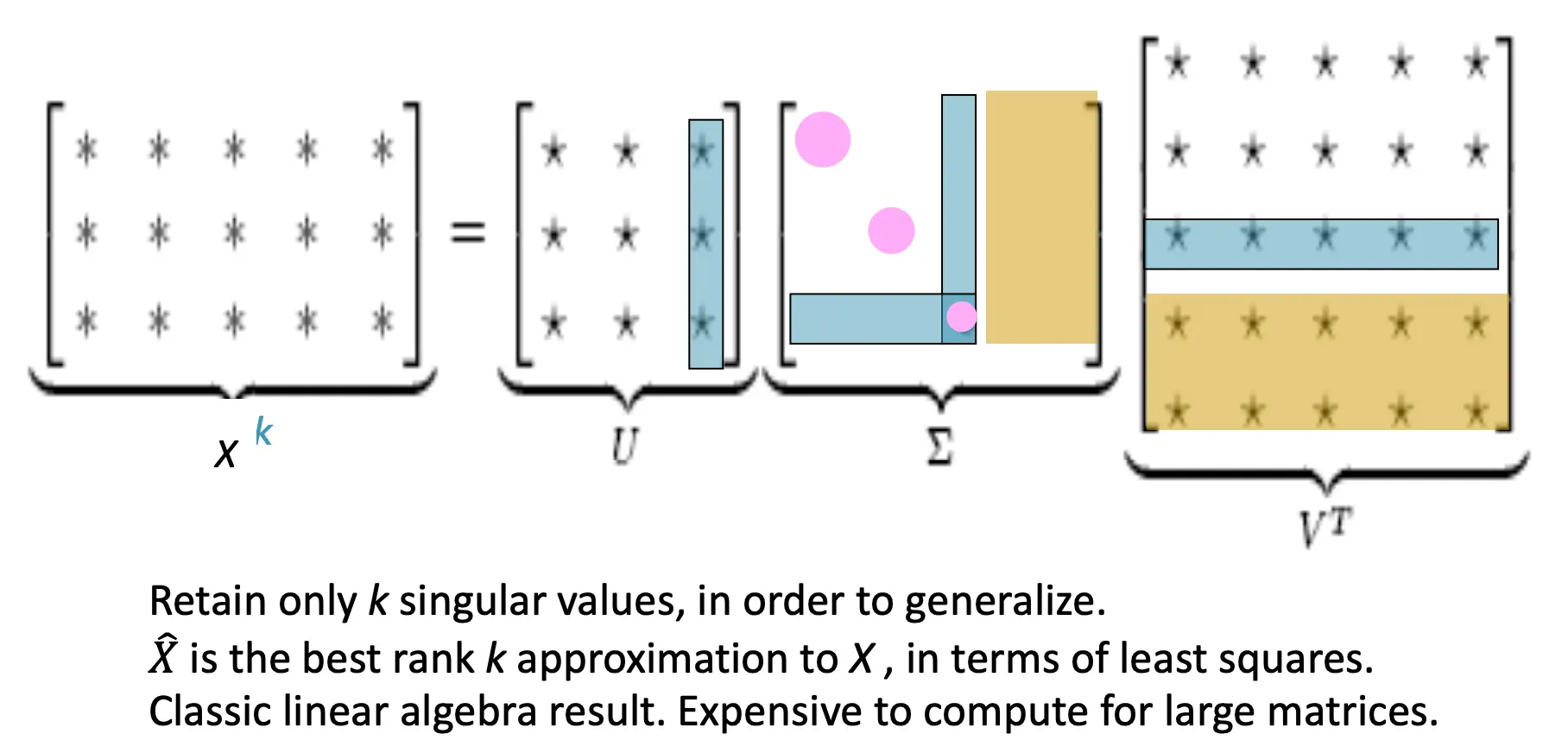
SVD分解的问题
如果直接对原始计数数据进行 SVD,结果往往不理想。这可能是因为矩阵包含了太多不重要或噪声信息。比如the he has这种功能次,可能出现很多次,导致权重过大。 那么如何解决呢?Rohde et al. 2005 in COALS
1、对计数矩阵进行缩放 (Scaling the Counts)
对频率取对数(log the frequencies)以压缩频率值的差距。 使用min(X, t)截断记数值,其中t约为100 直接忽略上面的功能词
2、加权窗口 (Ramped Windows)
使用加权窗口函数,使得距离目标词较近的词比远处的词权重大。这样可以捕捉更相关的上下文信息。
3、相关性替代计数 (Use Pearson Correlations)
使用皮尔逊相关系数代替计数。
Cov是协方差,sigma是标准差。皮尔逊相关系数衡量的是两个变量之间的线性相关性 这么做相当于做了一个标准化,限缩在[-1, 1]
这么做使用共现关系做embedding会有这样有趣的现象: 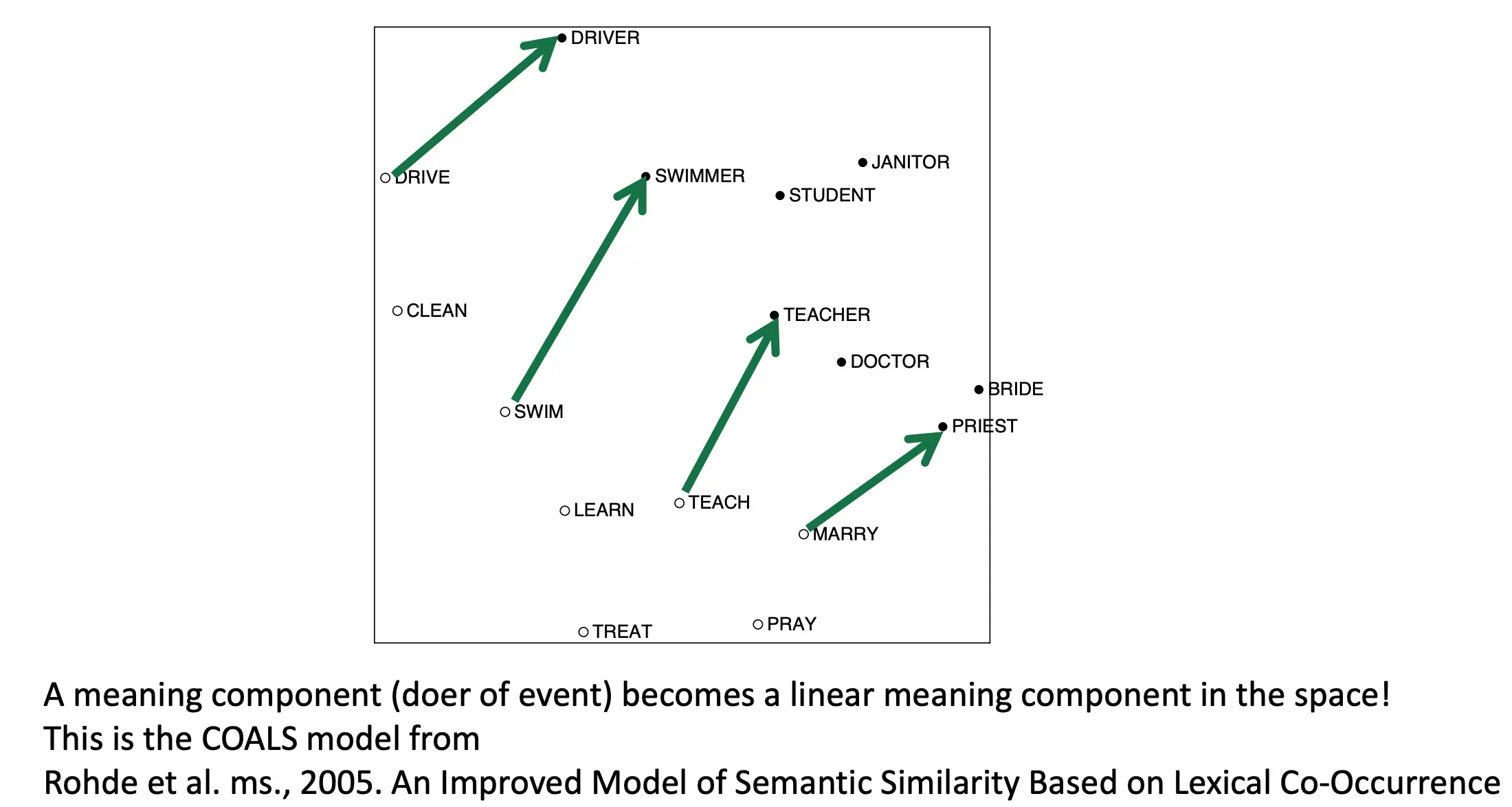
GloVe
GloVe: Pennington, Socher, and Manning, EMNLP 2014 在co-occurrence的实践中,我们有一个很显然的insight。频率的比值可以表示出现概率。红色表示较大概率,蓝色较小。 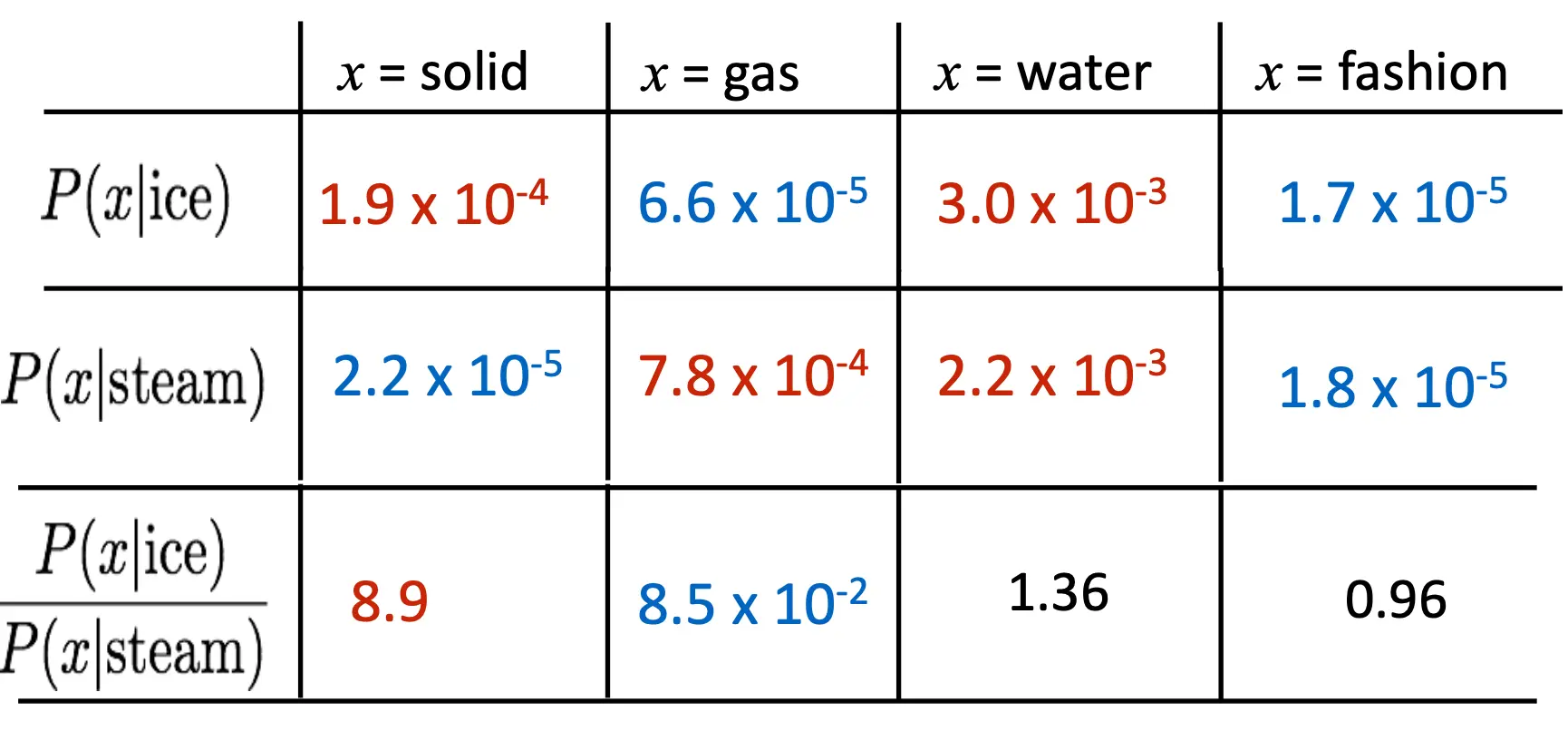
那么有了这个insight之后,再来一个basic: 如果两个词 i 和 j 共现的概率较高,表示它们在语料中的语义关联性强。 那么,我们就有:
那么,如果想要表示两个向量的差异的话,就会有
那么,就有损失函数:
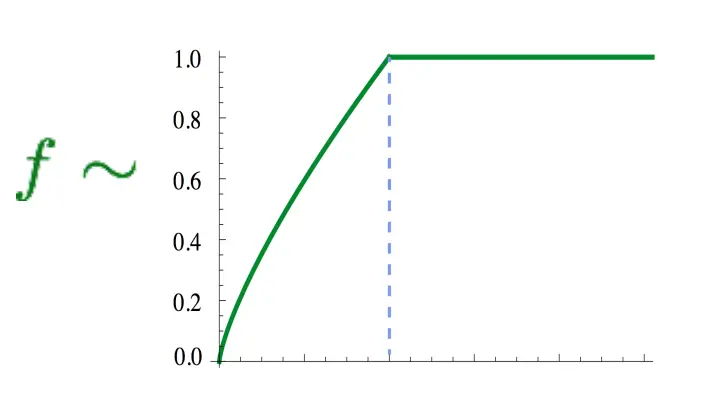
其中,Xij是ij的共现次数,wi是中心词向量,wj波浪是上下文向量,b是偏置,f是一个权重函数,当Xij小的时候,权重低,大的时候权重高。 这损失函数怎么理解呢?我们上面说,wiwj建模的是logP(i|j),是预测值,加上bi bj可以忽略,就是偏置。那么有以下表示,也就是目标值和实际值的差距。所以要缩小这个差距,就设计了J损失函数。
f大概长这个样子
如何评价一个Word Vector? Benchmark介绍
这种evaluation分为了Intrinsic和extrinsic。intrinsic纯评测你的词向量内部指标,extrinsic是评价搭配内容使用的大指标。
Intrinsic
Word Vector Analogies 类比任务
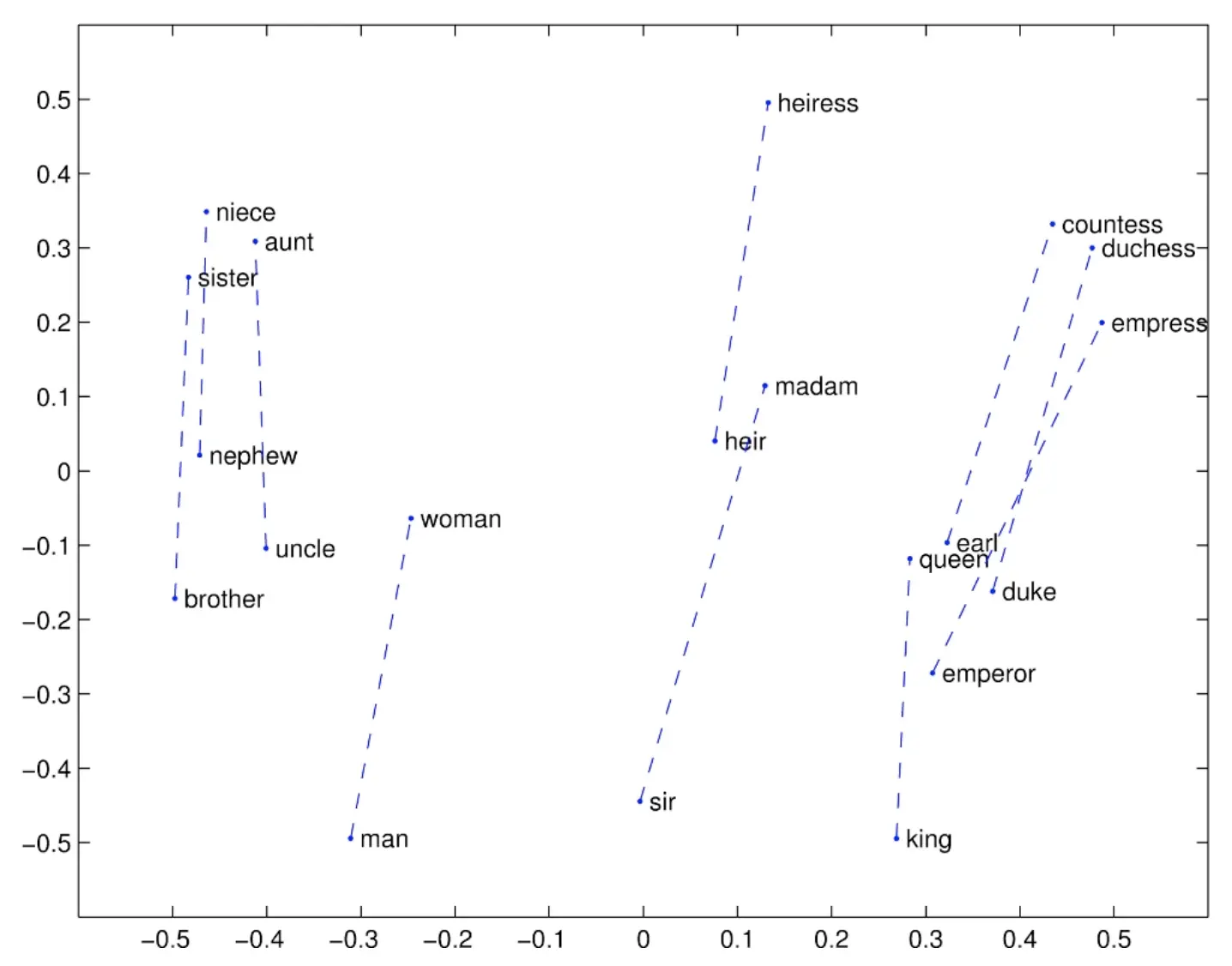
去计算a:b :: c:? 也就是man:woman :: king:? ?其实是Queen,就是看你的词向量能不能建模出这个向量关系。 
我们可以看到GloVe对于男女的嵌入其实就是做到这一点的:
Meaning similarity 意义相似度
找人去给词之间的相似度在0-10打分,然后看你词向量的距离,可以是余弦距离之类的,算出一个距离和标签比较,比较的方法可以是计算皮尔逊系数。 WordSim353 是一个经典的语义相似性评估数据集,包含 353 个单词对及其人类平均评分。
Extrinsic
Named Entity Recognition (NER)
目标是识别文本中的实体,并分类为“人名”、“组织名”或“地名”等。 "Chris Manning lives in Palo Alto." 中,Chris Manning 是人名,Palo Alto 是地名。 一个好的词向量模型应该能够更好地捕捉上下文中的语义信息,进而提升 NER 的准确性。  这玩意用途很多。可以在文档中追踪一个个体的出现次数,从而做到舆情监控,也可以做一些简单的问答系统,因为问答系统中回答的内容大部分都是命名实体。也可以加超链接,把内容链接到知识库。 接下来介绍一种简单的NER方法:Window classification using 二元逻辑回归。
这玩意用途很多。可以在文档中追踪一个个体的出现次数,从而做到舆情监控,也可以做一些简单的问答系统,因为问答系统中回答的内容大部分都是命名实体。也可以加超链接,把内容链接到知识库。 接下来介绍一种简单的NER方法:Window classification using 二元逻辑回归。

其中x_word是词嵌入向量,就是用上面的word2vec, glove或者fasttext,bert生成的。 你只需要以x向量为输入做一个二元逻辑回归就能完成任务。
歧异区分
一个词可能有很多种意思,比如bank这个词。怎么把不同的bank表示为不同的向量呢?
Context Cluster
Improving Word Representations Via Global Context And Multiple Word Prototypes (Huang et al. 2012) 聚类上下文:根据单词在不同上下文窗口中的使用方式,将上下文分为不同的类别(clusters)。 多义词的分配:对每个单词,分配到对应的不同聚类。例如,“bank” 可以被分配为: - bank₁:与“finance”、“money”相关的含义。 - bank₂:与“river”、“water”相关的含义。 重新训练:为每个聚类重新生成词向量,每个单词对应多个原型。 
线形拆分
Linear Algebraic Structure of Word Senses, with Applications to Polysemy (Arora, …, Ma, …, TACL 2018) 这个paper认为,一个多义词的词向量,是多个子意义词向量的线性组合
而其中a1 = f1 / (f1+f2+f3) , f是频率 这个方法的优点就是不用重新训练。而如何得到分解的成分数量呢?
- 你可以用聚类方法把上下文的词向量进行聚类
- 你可以用稀疏编码分解。每个多义词向量 vword 是稀疏的线性组合,即它的词义向量是可分离的。vword = W s, W是所有可能潜在的稀疏向量的拼接。
- 基于上下文依赖的分布信息。如果上下文可以用多模态分布(multimodal distribution)拟合,则每个模态对应一个词义。
 Larry Shi
Larry Shi