Language Models and RNN
训练Trick
这里的内容是讲一些克服过拟合的trick的,但OpenAI的结果显示,其实不存在所谓的过拟合,只存在double descent。我在里面也讨论了下面trick的内容。 论文链接: https://arxiv.org/abs/1912.02292 而这篇paper我已经做过解读,可以参考: Deep Double Descent Where Bigger Models and More Data Hurt
使用正则化应对过拟合
经典观点: 这个是L2正则。L2正则的原理就是,当我们去argmin theta J的时候,前半部分缩小是没有问题的。后半部分的正则项,如果想要小,那么每个theta都不能太大,这就会让theta整体趋于小,也就是说,不让某个神经元过于敏感,从而防止过拟合的发生。
目前观点:
⚠️ 过拟合的奇怪表述
这里有个很怪的说法,slide认为训练集的误差接近0就叫过拟合,我认为不是,我认为过拟合是一个相对概念,train降test升才叫过拟合,单看train降到0也不能叫过拟合,但是为了展示这个观点,我把观点放在这。
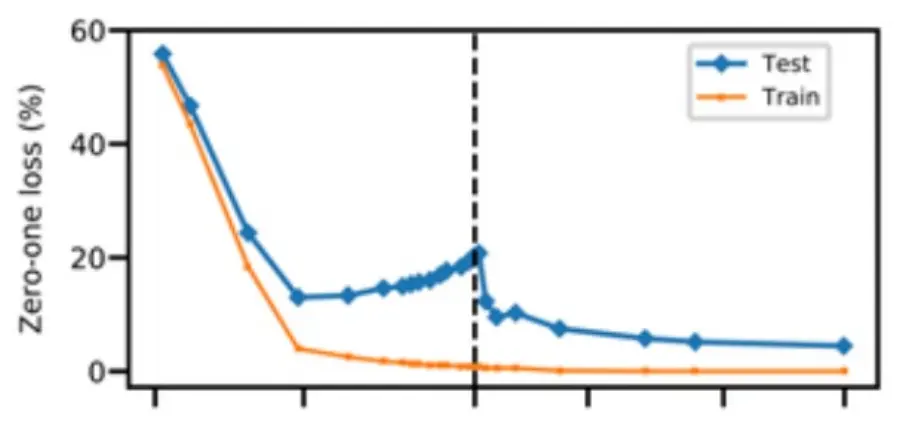
目前观点认为,正则化只是增加模型的泛化性,和过拟合没关系,即使你疯狂过拟合(这里指train loss接近0),你的test也可以降,因为你家了正则。 下面的图,横轴是模型规模。
使用Dropout应对过拟合
训练时按照p的概率使得神经元输入为0,测试时输出乘以1-p。最后乘1-p是因为p是drop的概率,所以1-p就是不drop,也就是期望。 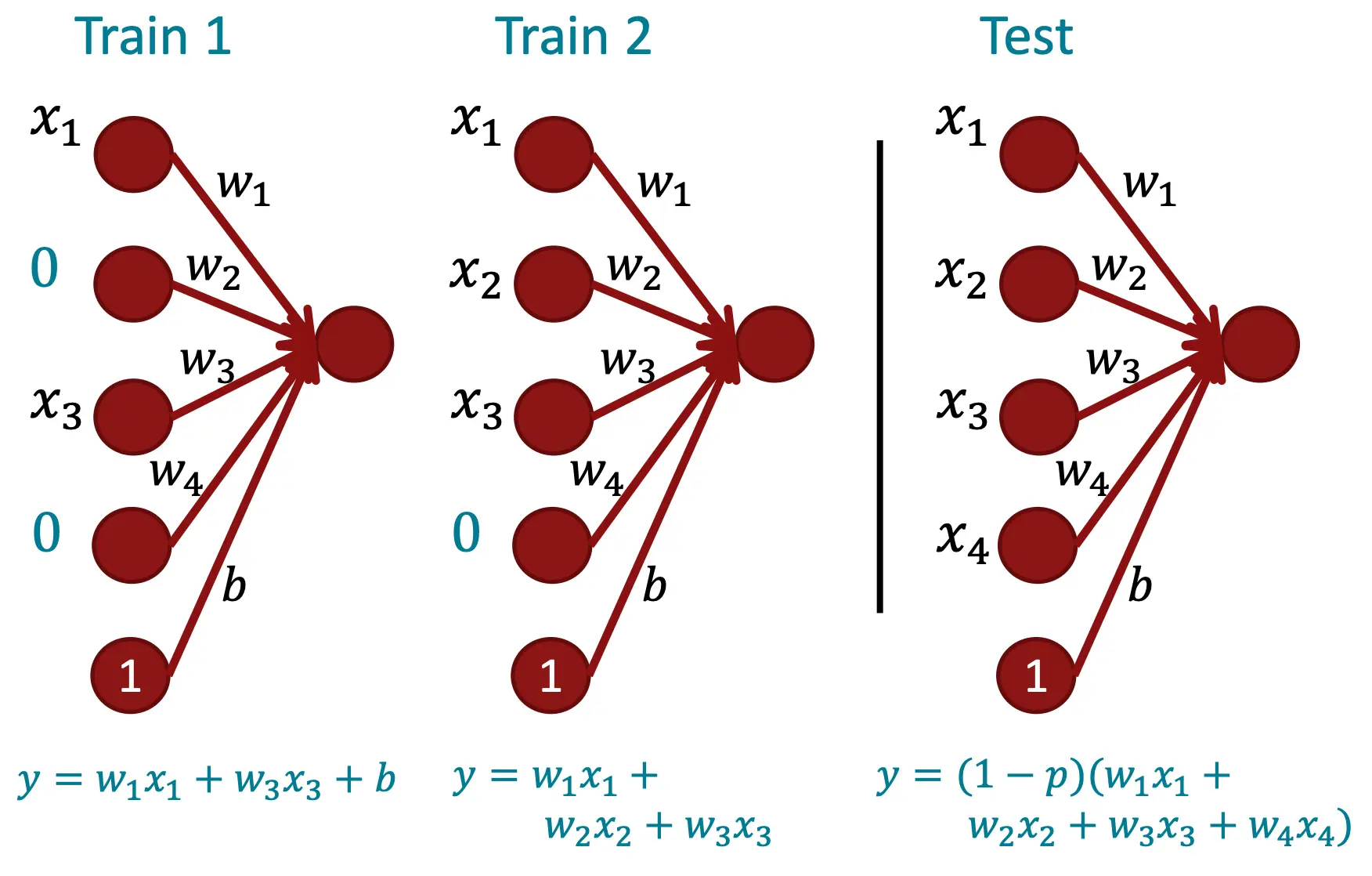 这种每次屏蔽一部分神经元的方法,可以避免模型中神经元共适应(co adaptation) 为什么dropout有效呢?原因是,
这种每次屏蔽一部分神经元的方法,可以避免模型中神经元共适应(co adaptation) 为什么dropout有效呢?原因是,
- 很多时候特征是互相依赖的。如果所有的神经元都有效,那么神经元可能会过度依赖这种关系从而过拟合。通过随机屏蔽的方法,可以让特征独立地发挥作用,减少对依赖关系的利用,从而增强泛化性。所以dropout也被看成是特征依赖的强正则化。
- 另一方面,dropout相当于训练了多个子模型,并进行了集成,降低了单一模型过拟合训练数据的风险
- 在测试时通过权重调整整合子模型的能力。
权重初始化
如果权重全部设置为0,那么输出一样,就会学到相同的特征。 所以就会有下面的方法:
- w都随机成小随机数
- 对于隐藏层的b,设置为0,对于输出层,也就是最后一层的b,设置成结果的平均值,或者avg(sigmoid^-1(结果))
- 把所有w按照uniform(-r, r)生成。r别太小太大
- Xavier 初始化确保输入层和输出层的激活值具有相同的方差,从而避免梯度消失或梯度爆炸问题。这有助于减缓梯度消失或爆炸问题,特别是在深层网络中。var为方差,n为神经元数量。
- 随着层归一化Layer Normalization的应用,对这些初始化技巧的需求可能会减少。
Optimizer
对于大多数优化器,建议的初始学习率是 0.001。
- SGD 足够好用 ,但手动调整学习率对于获得良好效果至关重要。学习率初始值可以设置得较高(例如 0.1 或 0.01)。随着训练的进行,每隔 k 个 epoch 将学习率减半,以应对损失函数的下降。
- Adagrad能够自动调整参数的学习率,适合稀疏特征问题。但容易“早停”(stall early),即后期学习率会过小,导致训练停滞。
- RMSprop改进了 Adagrad,控制了学习率的衰减速度,更适合深度学习中的长时间训练。
- Adam结合了 Adagrad 和 RMSprop 的优点,适合大多数任务,是许多场景下的默认选择。
- AdamW考虑了权重衰减的优化(weight decay),更适合大型模型。
- NAdamW在 AdamW 基础上引入了 Nesterov 动量加速,更适合语言模型(如词向量)和速度要求较高的场景。
Language Model
Intro
总的来说,Language Model是一种预测下一个词是什么的模型。 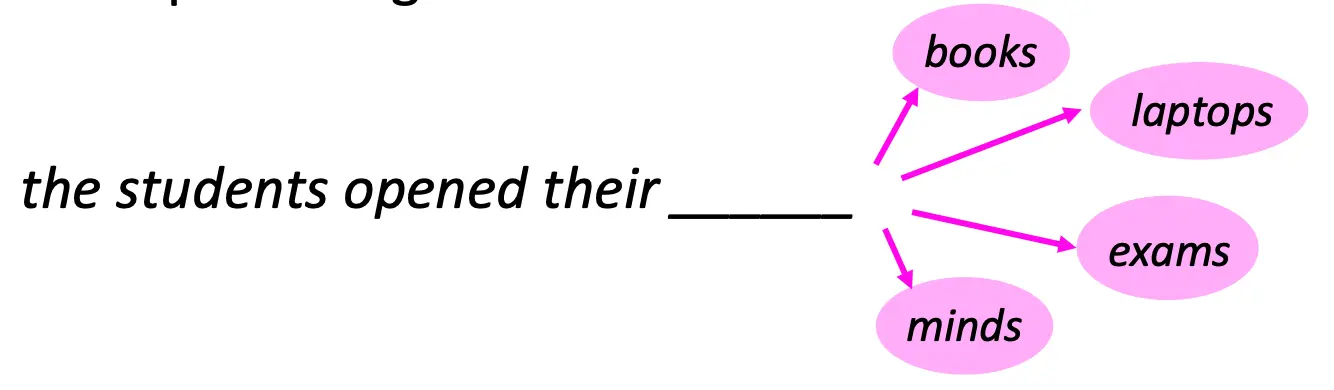 如果更正式的写,就是这样:
如果更正式的写,就是这样:
xt是前面的词,而xt+1可以是语料库V里面的任何一个词。 语言模型也可以这样解释:LM是一个系统,可以为一句话分配概率。 例如,如果我们有一句话x1 ... xT, 那么这句话的概率就是:
而这就是LM的核心功能。你通过条件概率的链式法则把一个概率拆解成下面的联乘形式后,语言模型的作用就体现在给定前面的词x1 - xt-1, 预测xt的概率。
这里就是LM的一个应用: 
n-gram Language Model
n-gram LM 是在DL出现之前最常用的一种语言模型。 n-gram是由 n 个连续单词 组成的单词块。 例如句子The students opened their _____ 1-gram: “the”, “students”, “opened”, “their” 2-gram: “the students”, “students opened”, “opened their” 3-gram: “the students opened”, “students opened their” 4-gram: “the students opened their”
想法就是,收集关于不同n-gram的频率统计数据,并利用这些数据来预测下一个单词。
n-gram有一个假设,叫做Markov assumption: 每个单词 x(t+1)的出现只依赖于前面 n−1个单词,而不依赖更久远的上下文。n是n-gram的n
而根据条件概率的公式,我们有:
那我们怎么得到n-gram和(n-1)-gram的联合概率呢?用大型语料库中的频率估计概率:
例子:  那么在这个例子中,语料库中student open there book 是400次比 student open their exams是100次,所以4-gram LM选择book为w。 但是如果联系更前面的上文,我们知道proctor是监考员,所以应该选择exam。这是n-gram的问题之一。接下来我们来讨论n-gram的问题:
那么在这个例子中,语料库中student open there book 是400次比 student open their exams是100次,所以4-gram LM选择book为w。 但是如果联系更前面的上文,我们知道proctor是监考员,所以应该选择exam。这是n-gram的问题之一。接下来我们来讨论n-gram的问题:
问题1: 稀疏性问题 (Sparsity Problems)
问题1: 如果分子从来没有出现过怎么办?
引入 平滑技术 (Smoothing),从而让模型可以处理所有分子不存在的情况。
问题2: 如果分母从来没有出现过怎么办?
可以用backoff策略。回退上下文。
实际上,n 越大,n-gram 的组合数量呈指数增长,导致数据稀疏性加剧。通常n 不会取太大值(通常不超过 5),否则模型的稀疏性问题会难以解决。
问题2: 储存问题(Storage Problems)
如果你的语料库有V个词,那么可能的n-gram就有
实际中,一个3-gram的LM的效果是这样的:
today the price of gold per ton , while production of shoe lasts and shoe industry , the bank intervened just after it considered and rejected an imf demand to rebuild depleted european stocks , sept 30 end primary 76 cts a share .
语法大概没问题,但是不连贯,所以考虑想要用神经网络。
Fixed-window Neural Language Model
无稀疏性问题,也没有存储问题。 但有新问题:窗口永远不够大,且由于每个词在的位置不一样,每个词被处理的权重也不一样,这不一定是一个缺点,就是在这里提一下。 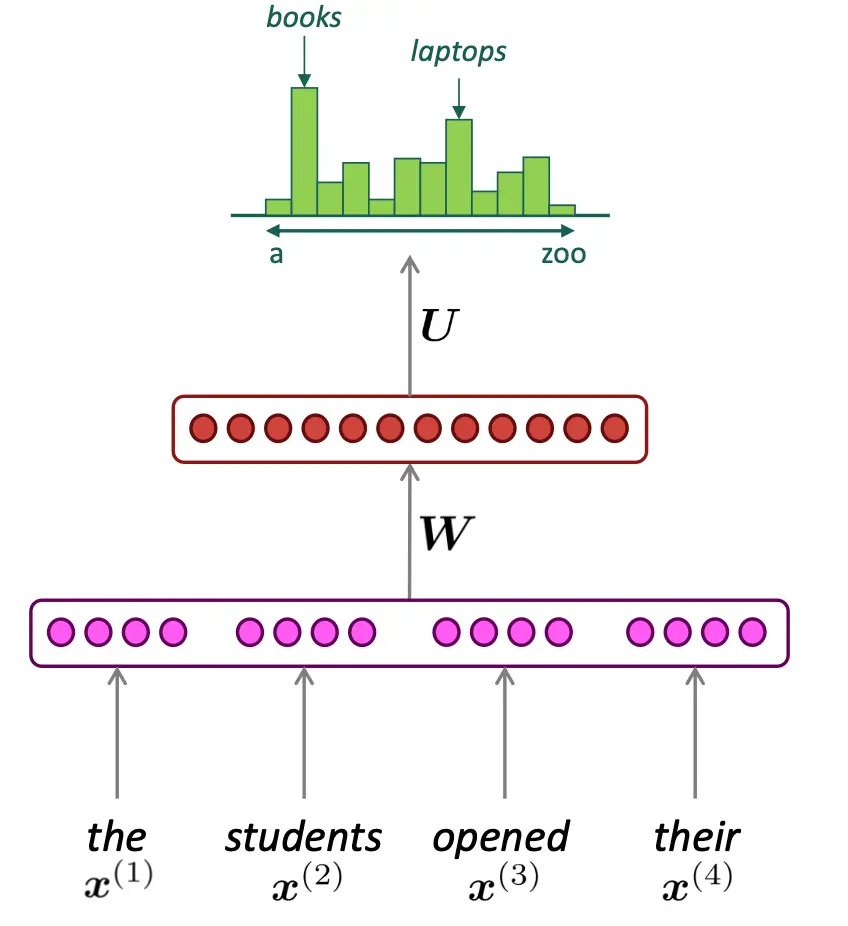
RNN
以前学过,这里简单聊一下。首先就是一个简单的例子:
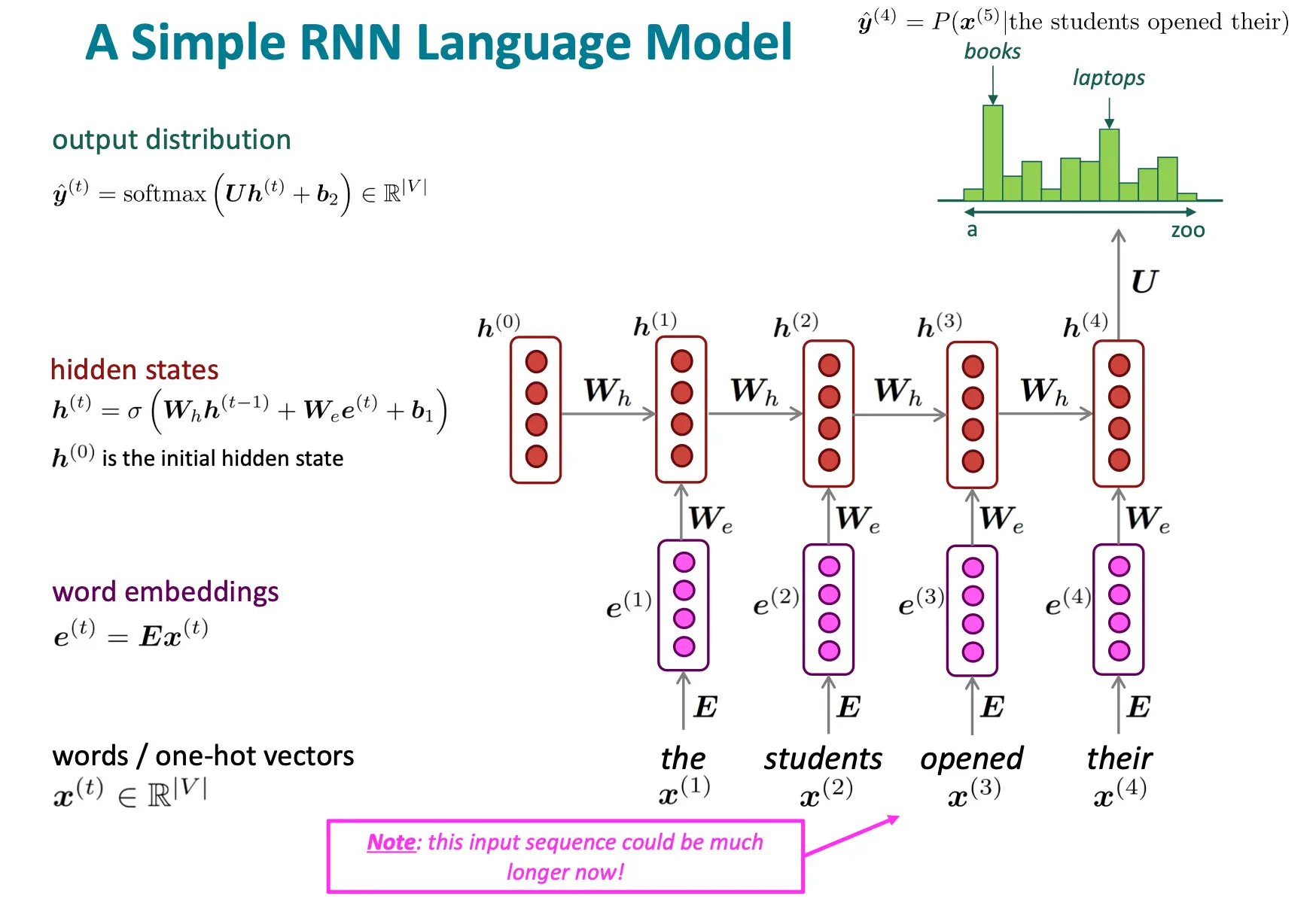 RNN优点:任意长度都可以处理,且所有长度的W维度都一样。每个时间步词的处理都是对称的。 缺点:慢,且难以利用很长时间步以前的内容。这些缺点将会在后面详谈。
RNN优点:任意长度都可以处理,且所有长度的W维度都一样。每个时间步词的处理都是对称的。 缺点:慢,且难以利用很长时间步以前的内容。这些缺点将会在后面详谈。
如何训练RNN?
拿一个大文字语料库
而整个训练集上的loss就是这样:
训练的示意图如下: 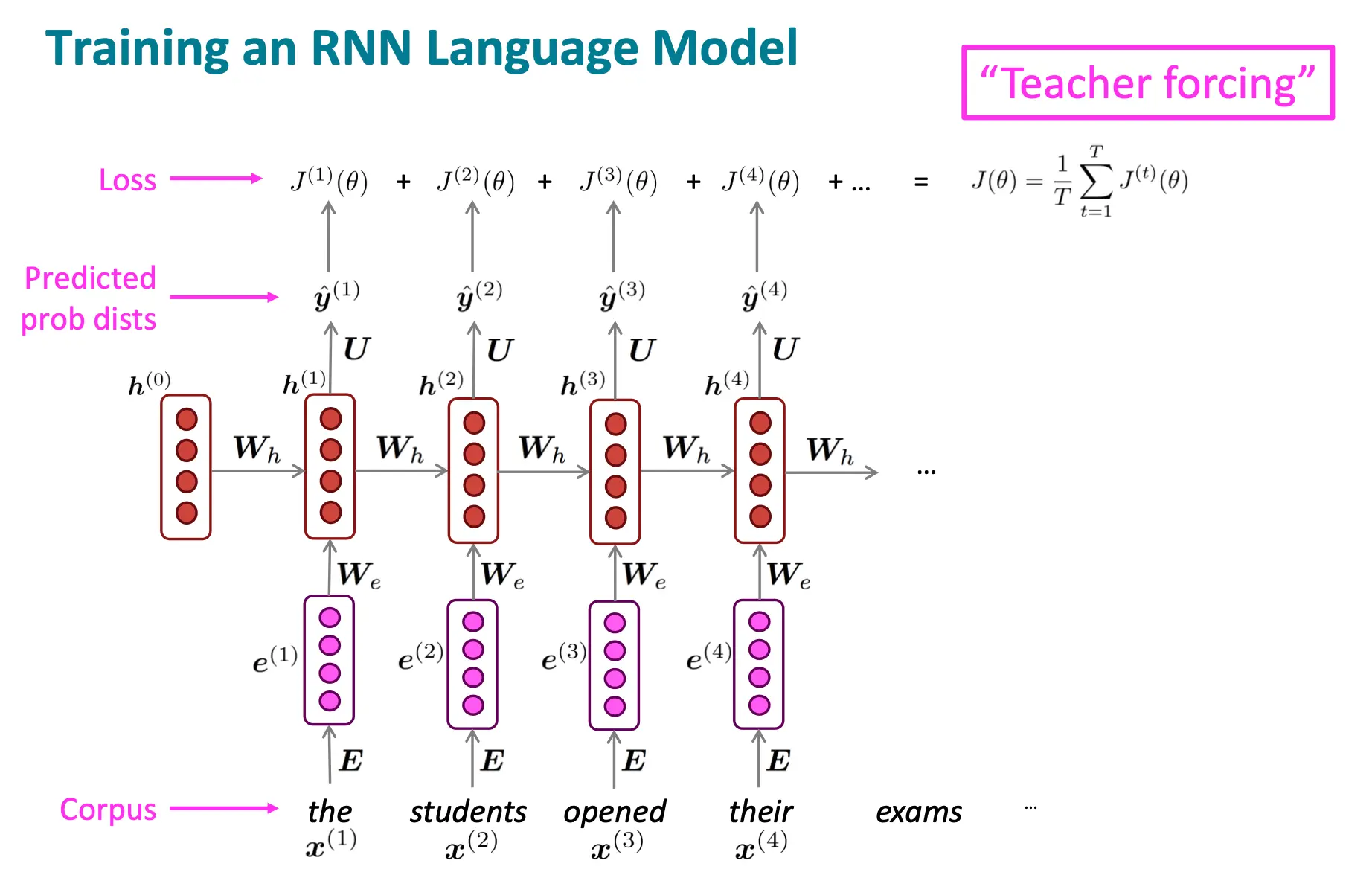
这里面存在一个叫Teaching Forcing的技巧,或者叫训练与测试的差距: 就比如说,当我们给出the这个词的时候,我们输出的东西是y1hat, 输出的hidden state是h1,但是问题就是,真实场景中,我们应当拿y1hat作为x2输入,而不是ground truth x2,students。在这里输入ground truth x可以快速帮助模型训练,防止错误累积,导致模型训练不稳定。 但Teaching Forth其实也存在潜在问题。 在测试阶段,模型需要使用自己预测的结果作为下一步的输入,这可能与训练阶段的行为不一致,从而影响性能。
训练时,我们会使用SGD, 非minibatch版,因为minibatch其实就是加起来平均罢了。
那么,RNN是怎么反向传播的呢? 总的来看,是这样的:
这说明了总梯度由于minibatch会沿着Jt展开,而由于Jt收到前面时间步的影响,所以Jt要顺着i展开。 为什么?我们举个例子。假设是一个长度为3的RNN: 那么根据rnn的公式:
那么J3怎么算呢?
其中括号中的内容是i的值。 我们介绍一下J3对Wh的梯度怎么算:
前一部分,很容易看出答案是g'(Wyhi) * Wy 后一部分呢?还要继续展开:
这里,h2对这个式子算常数,所以就不继续展开了。 实践中经常只回退20步,也就是如果t=50,那么只算J30-50。 所以,一个有三个单词的句子的梯度J = J1 + J2 + J3, 算出总J之后,再梯度下降,这是比较常用的版本。而每个J1,J2,J3,在算Wh的梯度的时候,都要沿着i再展开一次。展开原因比较直观的图是这样的: 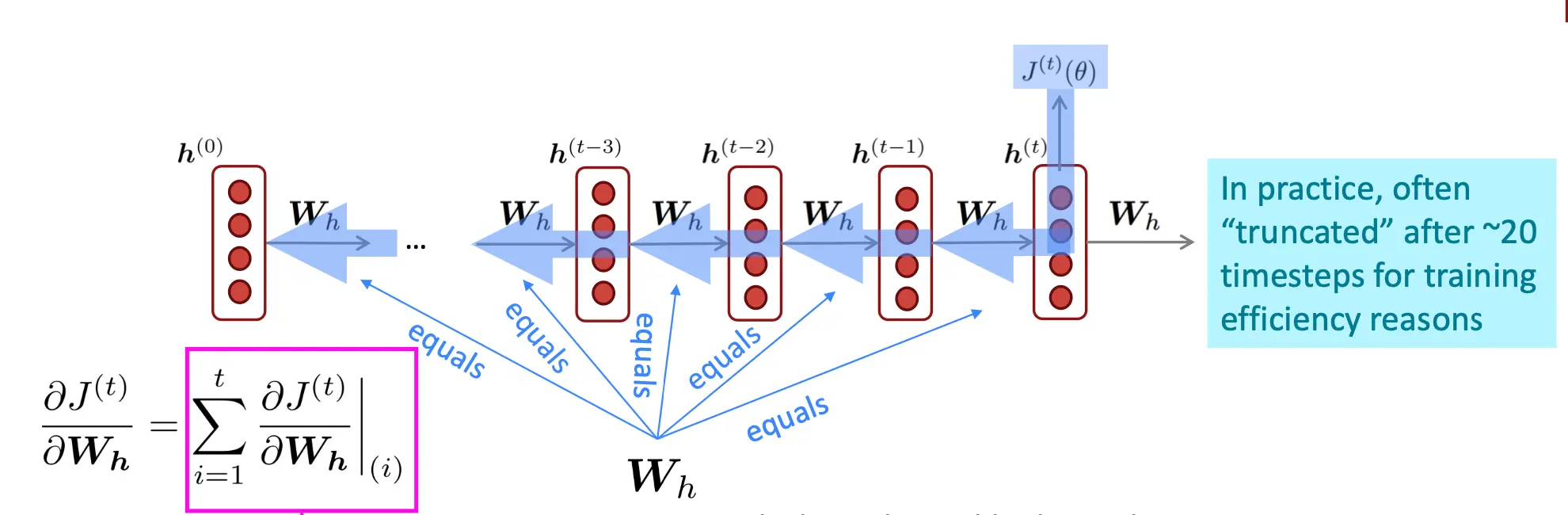
利用Perplexity评估LM
perplexity定义如下。在这里面,xt+1并不是随便一个词,而是正确的下一个词。所以说这个定义衡量了你预测的完全准确度,从exp J theta的形式也能看出来。然而,他只能衡量一模一样的词。如果你的词不一样,但是意思一样,perplexity是衡量不出来的。所以后面会有更好的指标,比如BLEU(生成文本与参考文本的 n-gram 重叠程度), ROUGE(基于召回率计算生成文本与参考文本的 n-gram 重叠、最长公共子序列等), 
RNN的梯度累积问题
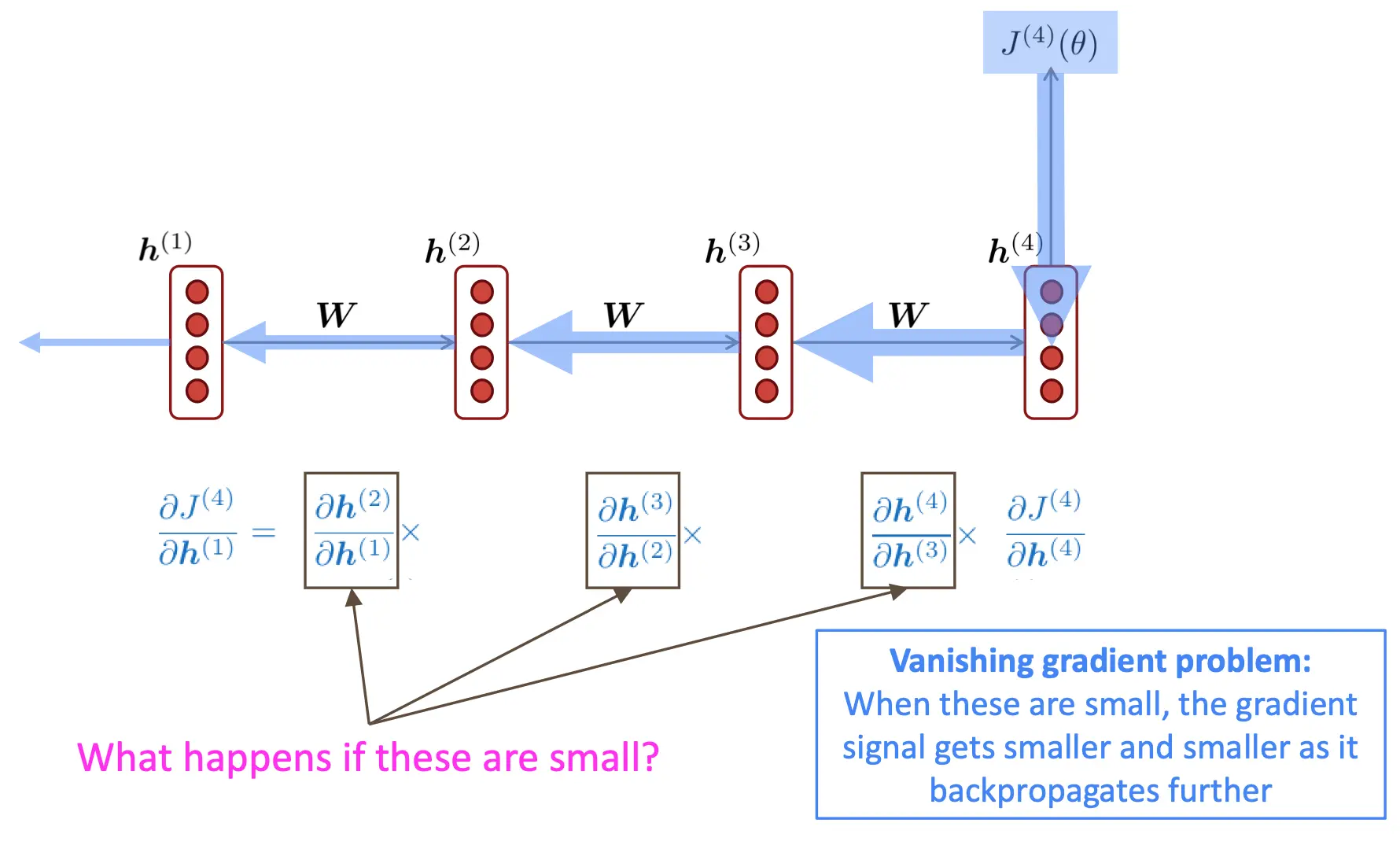 在计算Jt对Wh的梯度的时候,我们的计算方法是,在t之前每一时间步的ji对wh的梯度算出来相加。而对于每一步(以第三步对时间步第三步为例),我们有
在计算Jt对Wh的梯度的时候,我们的计算方法是,在t之前每一时间步的ji对wh的梯度算出来相加。而对于每一步(以第三步对时间步第三步为例),我们有
说明了计算Jt对Wh的梯度时,我们要用到Jt对那一时间步hi的梯度。现在我们让t为4,i为1,那么像上图一样,J4对h1的梯度要经过很多个hi+1对hi偏导的联乘。那么,我们写一下h的表达式:
那么,为了方便问题,我们让激活函数为恒等函数。那么ht对ht-1的偏导就可以写成:
然而,由于距离比较远,我们要联乘,所以有:
其中右上标l是指数。也就是说,随着时间步离当前步越远,梯度会随着Wh指数级变化。如果Wh比较大,那么j对h的偏导就会爆炸,如果Wh比较小,那么梯度就消失了。
INFO
进一步,我们来考虑为什么这个梯度消失/爆炸是有问题的。因为J4对Wh的偏导,是i在1-4的情况下J4对Wh偏导的和。所以说,可能3,4贡献了梯度,而1,2没有贡献梯度,结果梯度还是有的。远一点的词贡献小一点,貌似问题不大。 但其实还是有问题。由于是指数级的变化,如果趋势是梯度消失,那么早期时间步的梯度贡献被严重压制,即使后面时间步的梯度较大,它们也无法弥补早期信息的丢失。这就与n-gram遇到的问题有点像了。
面对梯度爆炸,我们是有简单的解决方法的。就是clipping。直觉:沿着相同的方向迈出一步,但步伐更小。
面对梯度消失,是不好处理的。 因为h是不断被重写的,我们需要改变架构,比如LSTM,Attention,residual connection。
Why LM
为什么我们需要LM? 以前的答案可能是,容易benchmark,所以可以帮助我们衡量我们模型的能力。LM也作为NLP tasks的组件存在着,尤其是那些有关生成文字,估计文字概率的任务,比如预测输入,语音识别,手写识别,拼写/语法纠正,作者身份识别,机器翻译,摘要生成,对话系统。
但目前被证明,NLP的所有任务都能被LM所克服。 LLM都是LM,我们可以prompt来让LM做很多任务。
RNN做一些事情的架构如下: 词性标注: 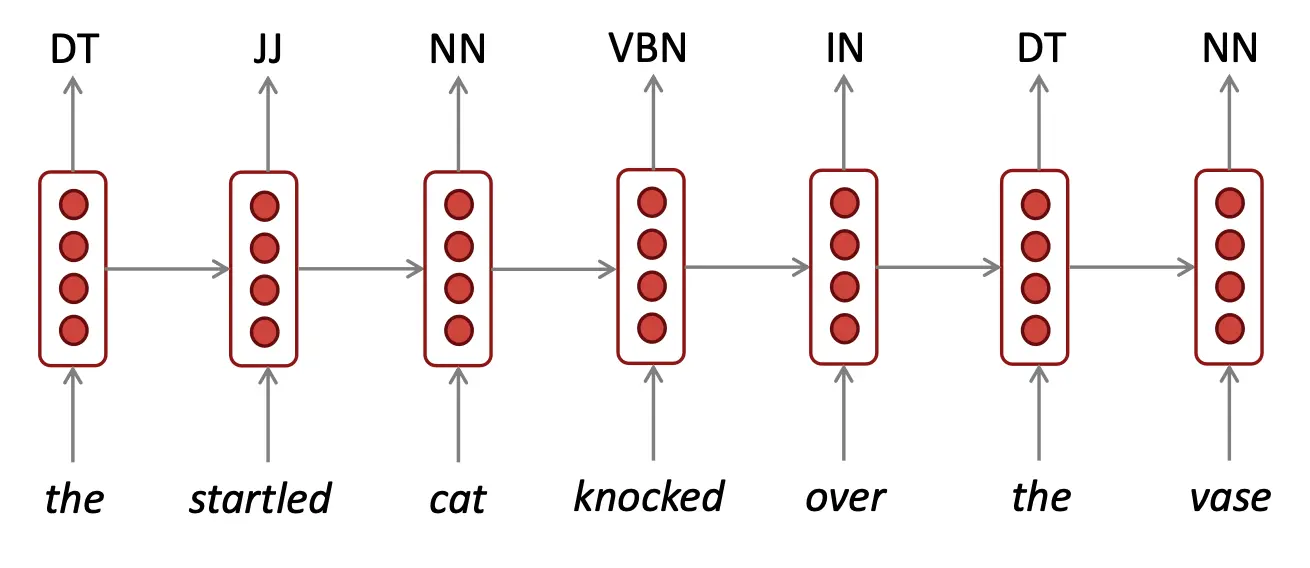
情感分类: 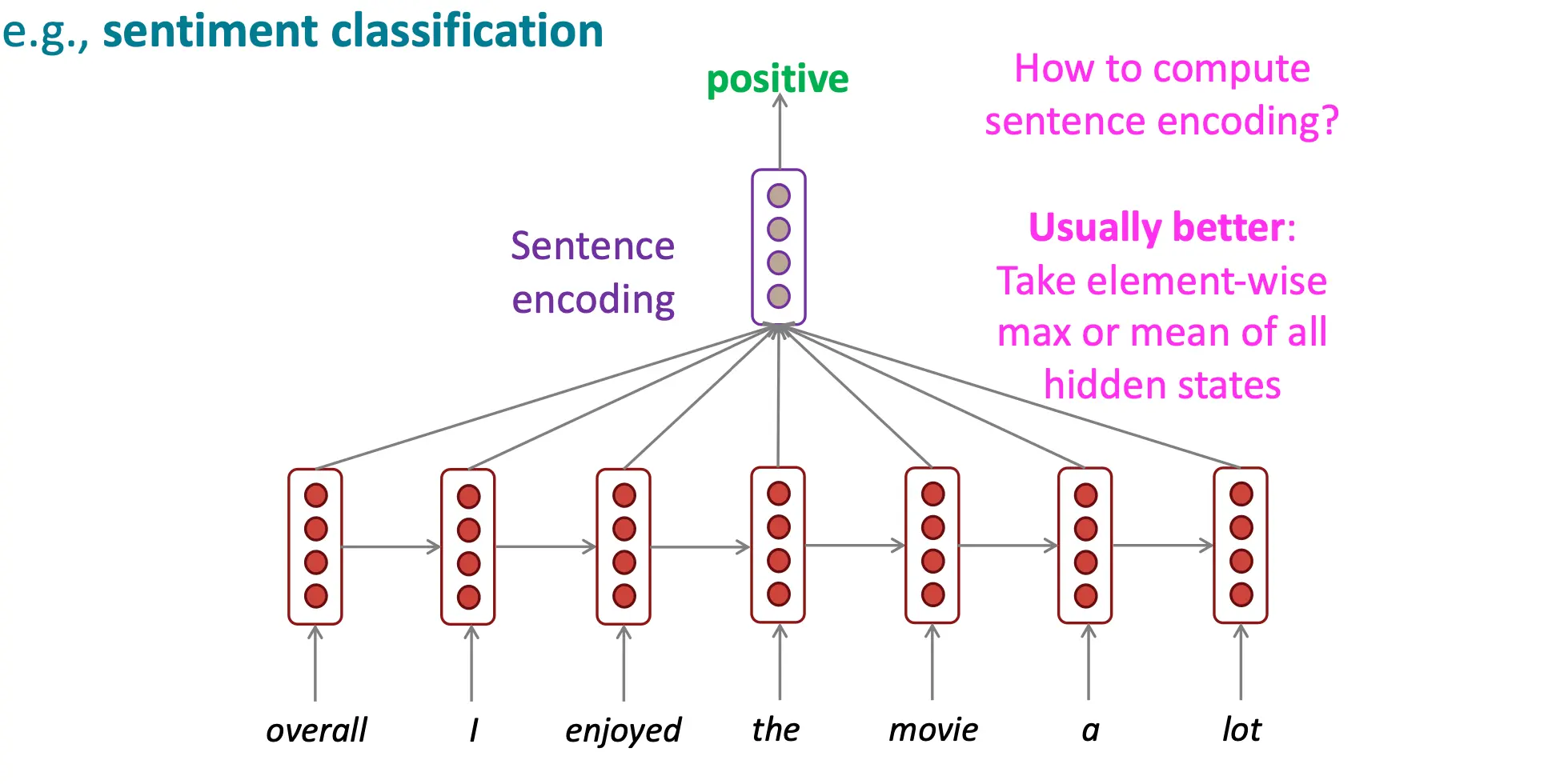
被当作encoder:
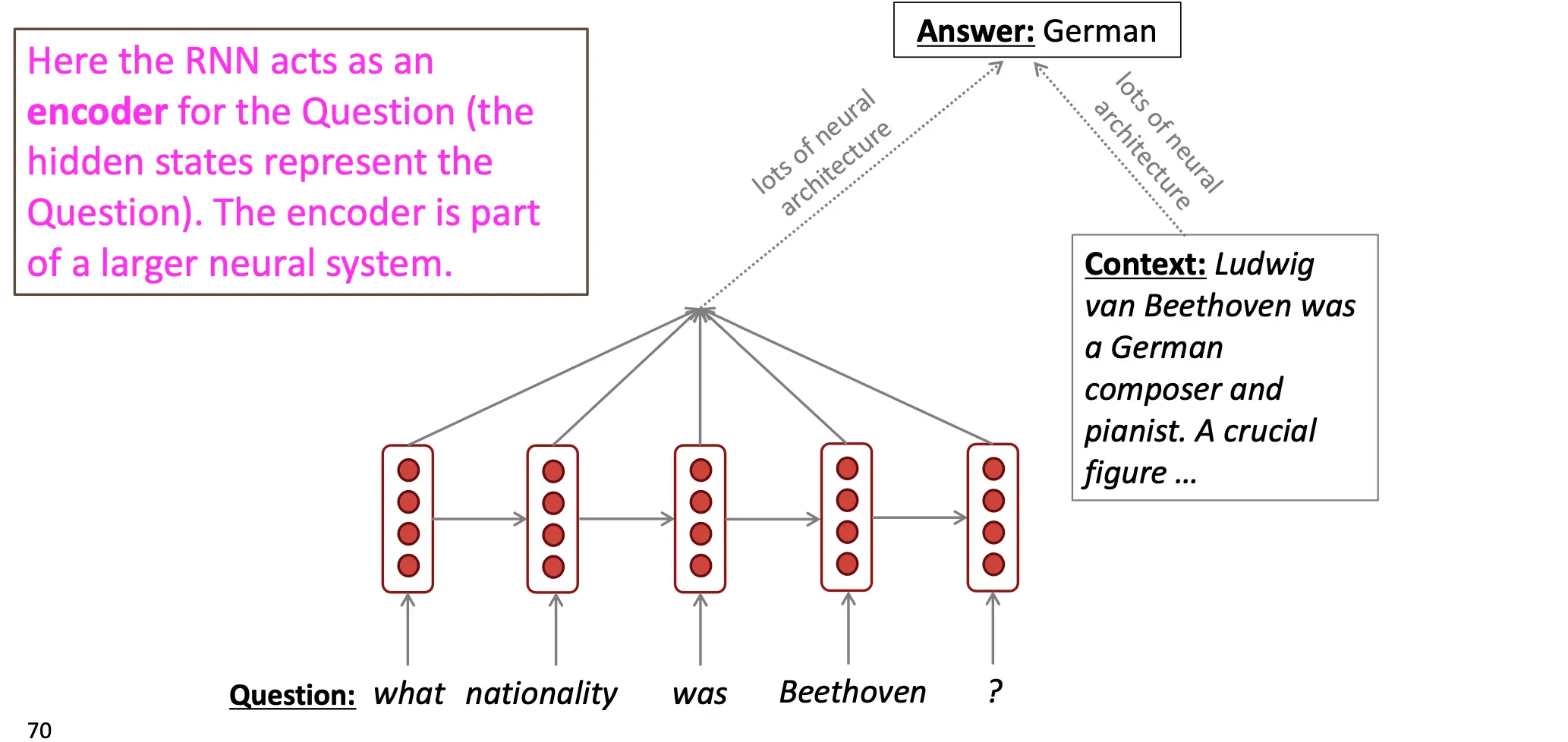
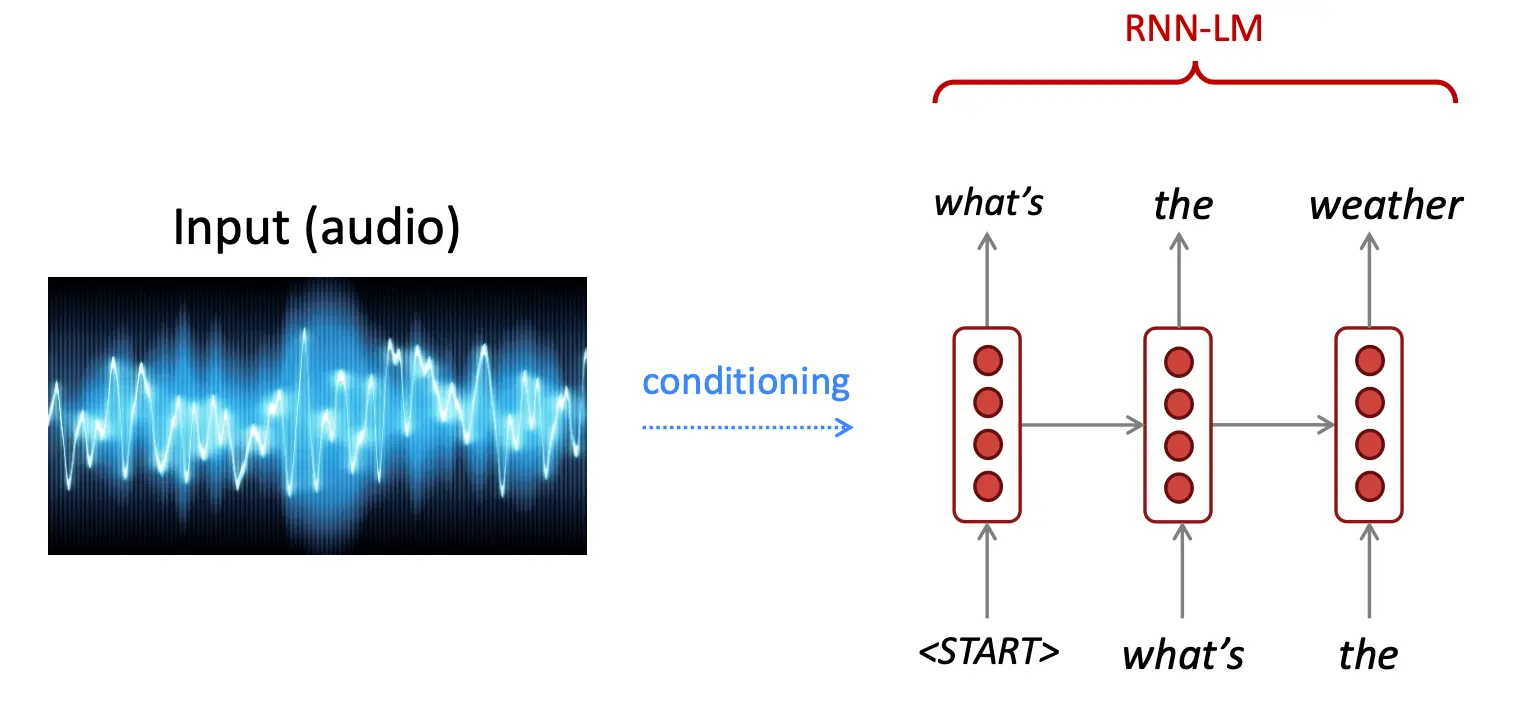
语音识别:条件LM。音频作为先验输入给模型,这样可以提高预测准确率。
 Larry Shi
Larry Shi