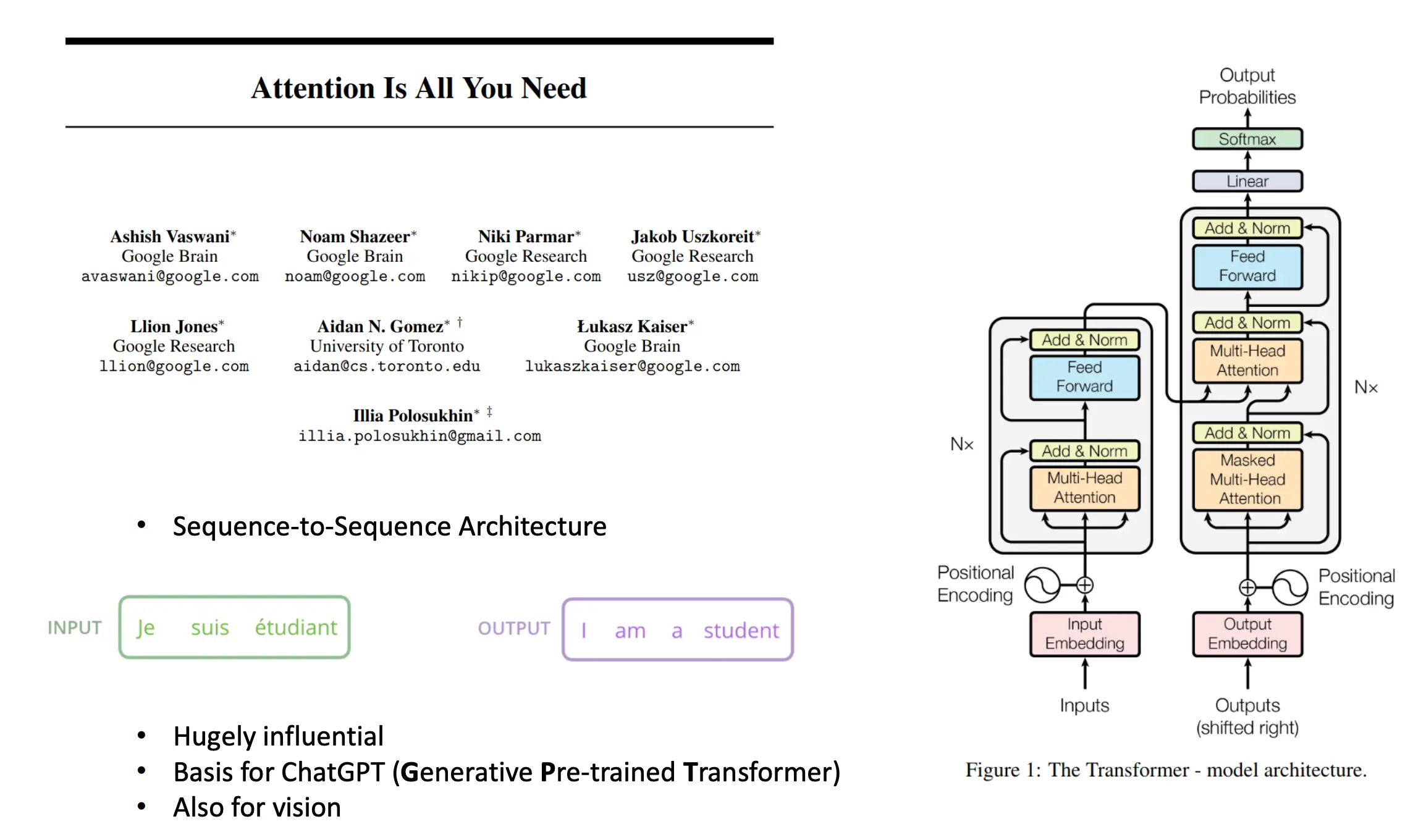
Transformers
Autoregressive models
我们在上一讲提到了生成模型的种类 9 - Diffusion,其中我们提到:  其实我们就是想要拟合一个概率密度估计(PDE)。 我们的目标是找到一个参数化的模型Ptheta,令
其实我们就是想要拟合一个概率密度估计(PDE)。 我们的目标是找到一个参数化的模型Ptheta,令
然而,这很困难。因为,有时候我们都不知道pdata是什么。另外,如果ptheta太复杂,我们都没法算出概率密度或者对数似然。 所以我们的做法是:
NOTE
当「直接最大化数据似然」maximize logpθ(x) 不可行时,就用「让模型生成的数据和真实数据在统计上难以区分」的策略来代替。
比如GAN,并没有给出一个可以直接计算概率密度的函数ptheta, 而是只定义了“如何从随机噪声z生成样本x_tild = G(z)这一过程。 因此我们 没法 在每一步算出 logptheta(x) 去让其最大化。我们采用的方法是,不停地从模型里采一大批样本x_tild, 用某种度量(或对抗网络)来衡量这些假样本和真实数据的“差别”,不断调整theta,让真实x和x_tild差距越来越小。
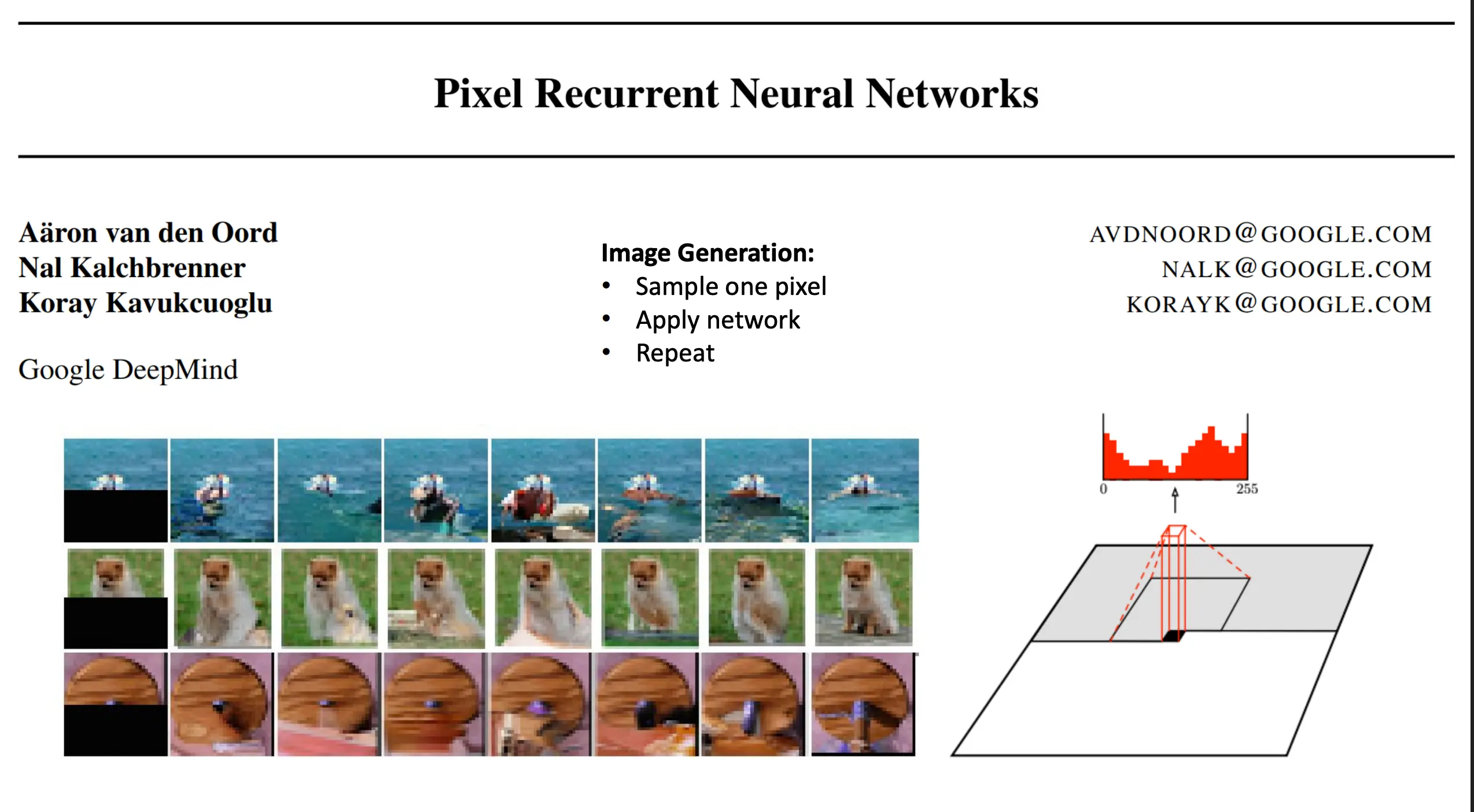
而对于自回归模型,做法是:利用概率论的链式法则,将对:
的联合分布
优势就是,精确似然:能直接写出并计算logptheta, 但缺点就是生成速度比较慢。
Transformer
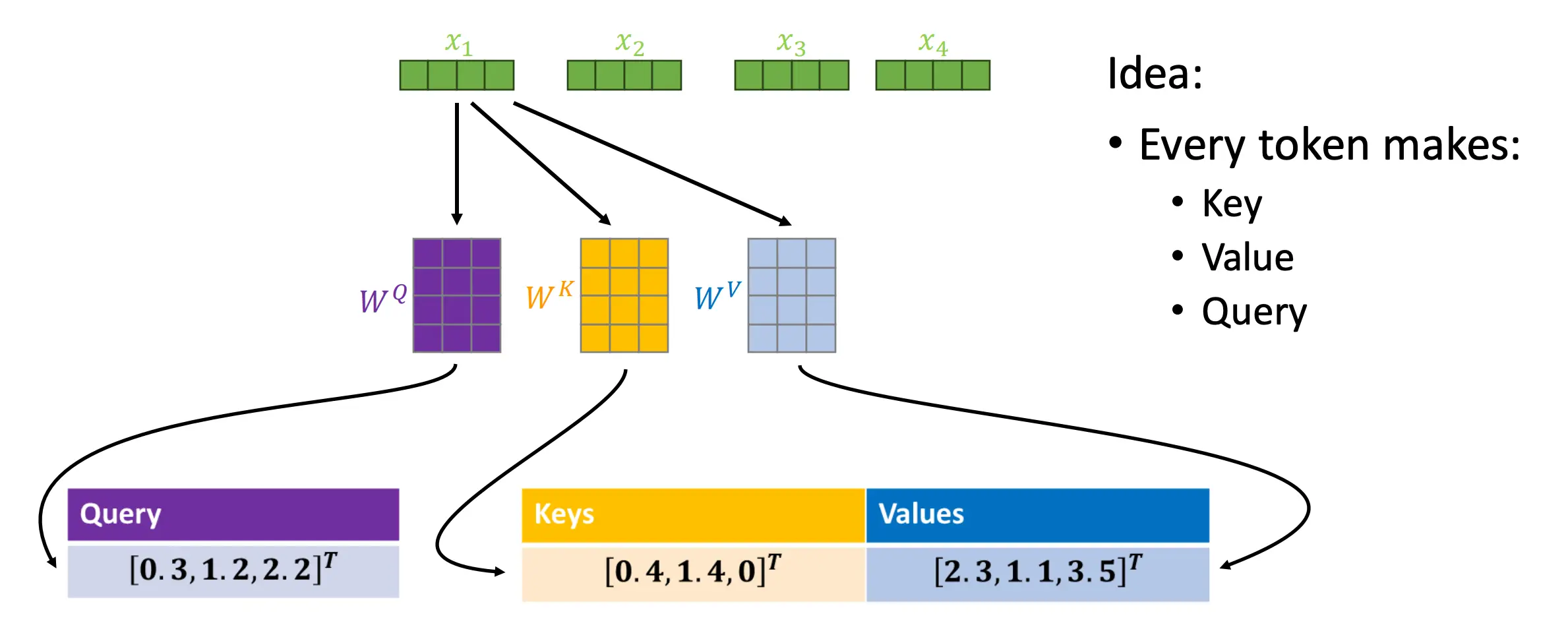
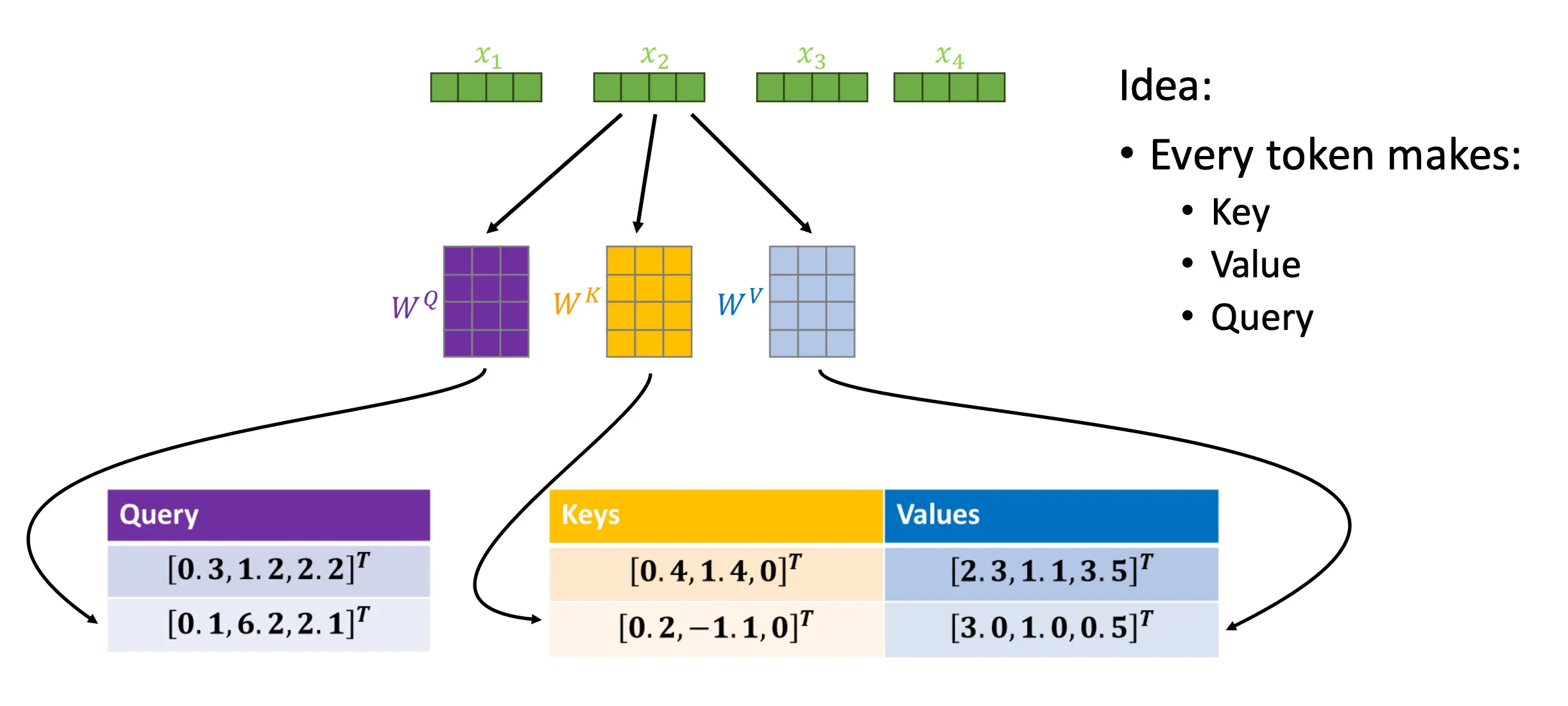
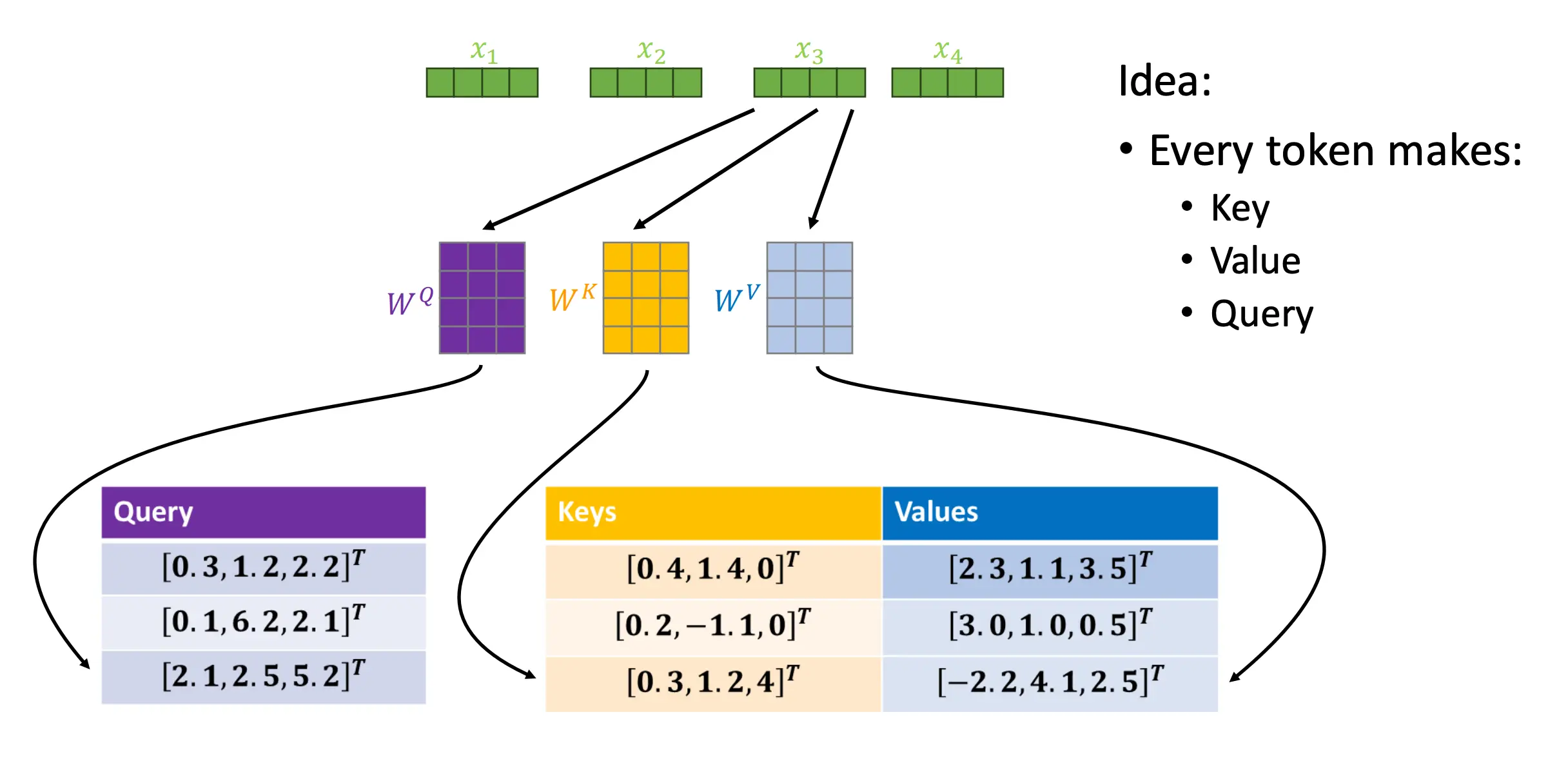
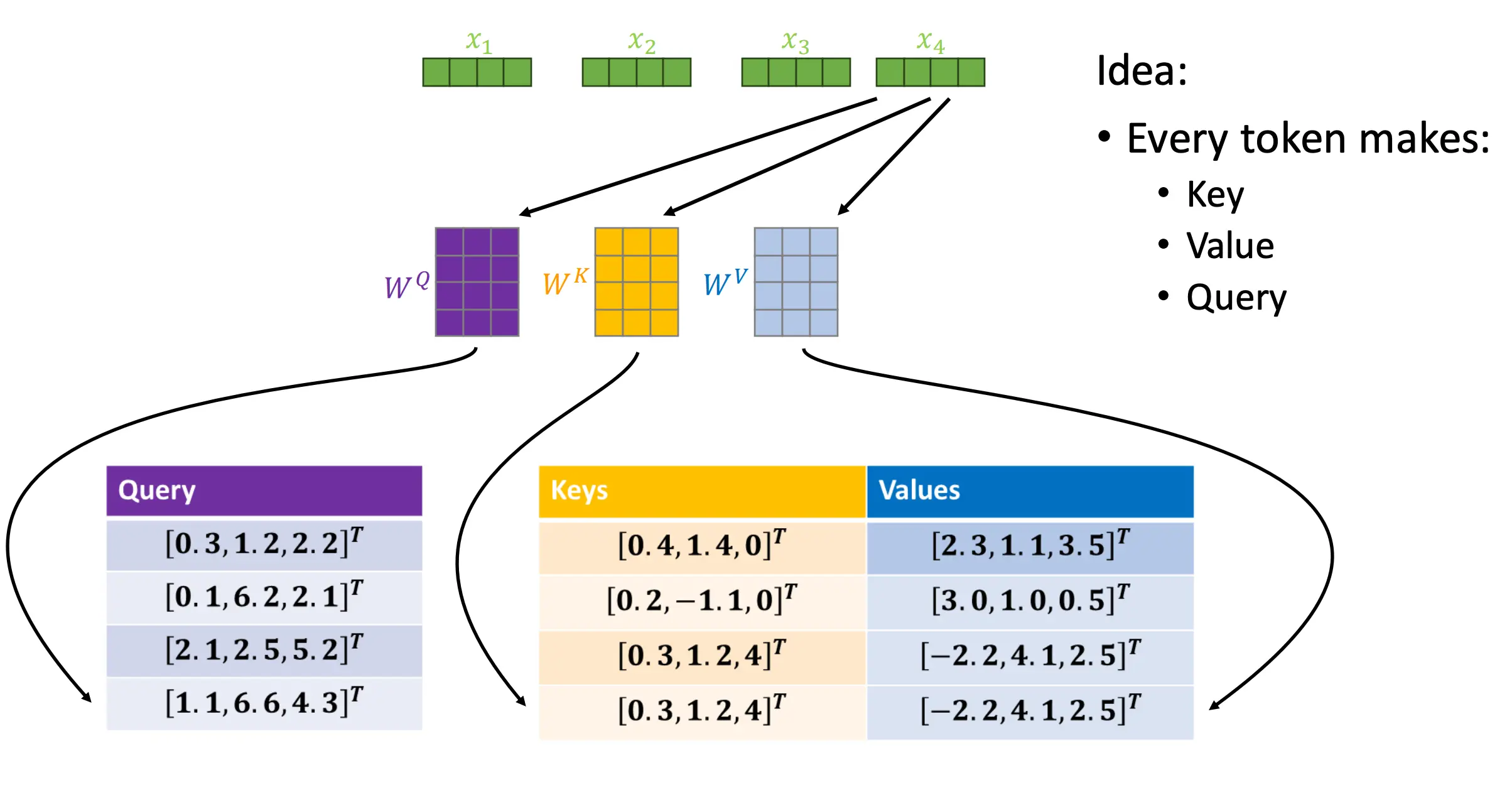
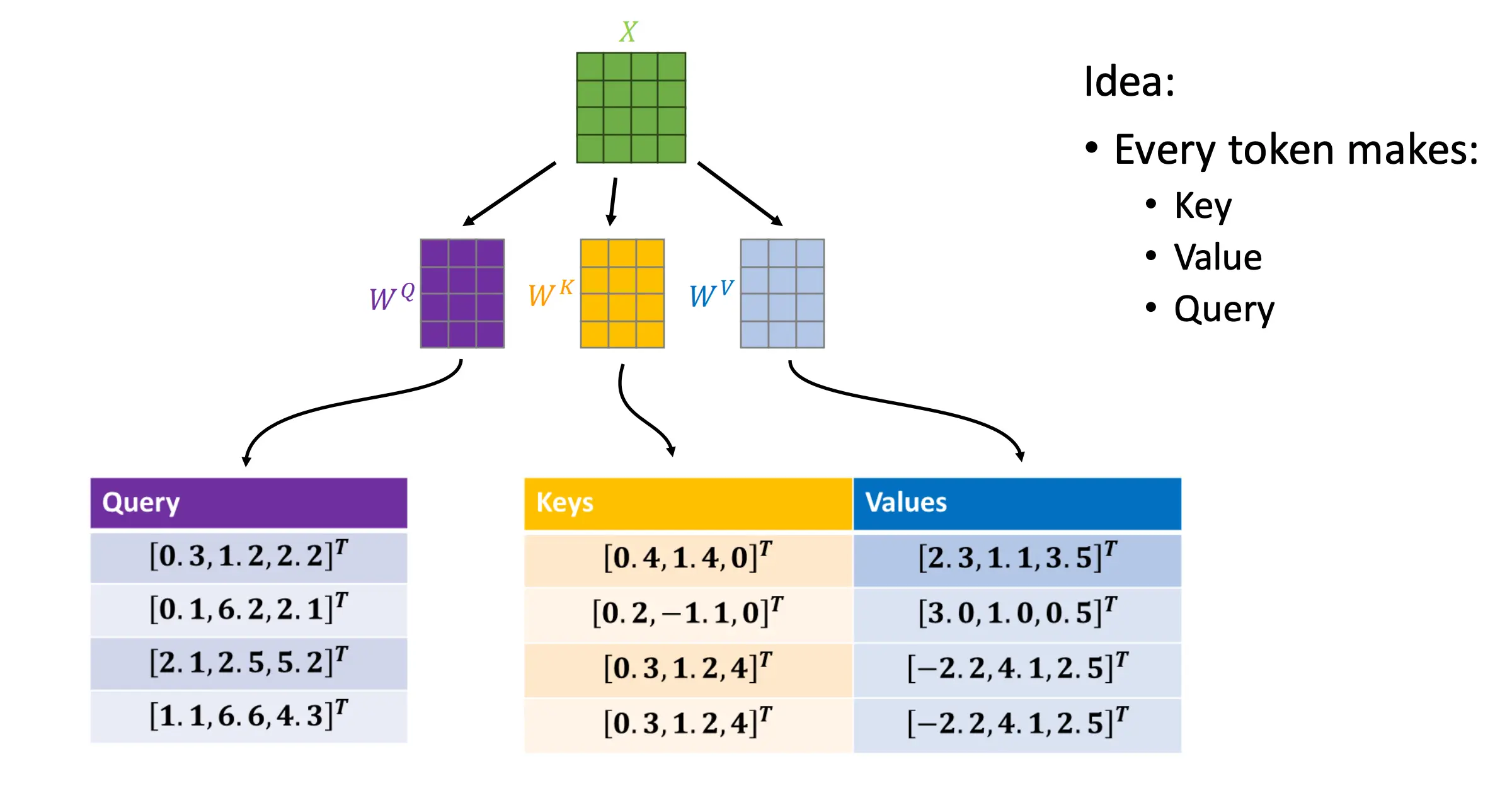
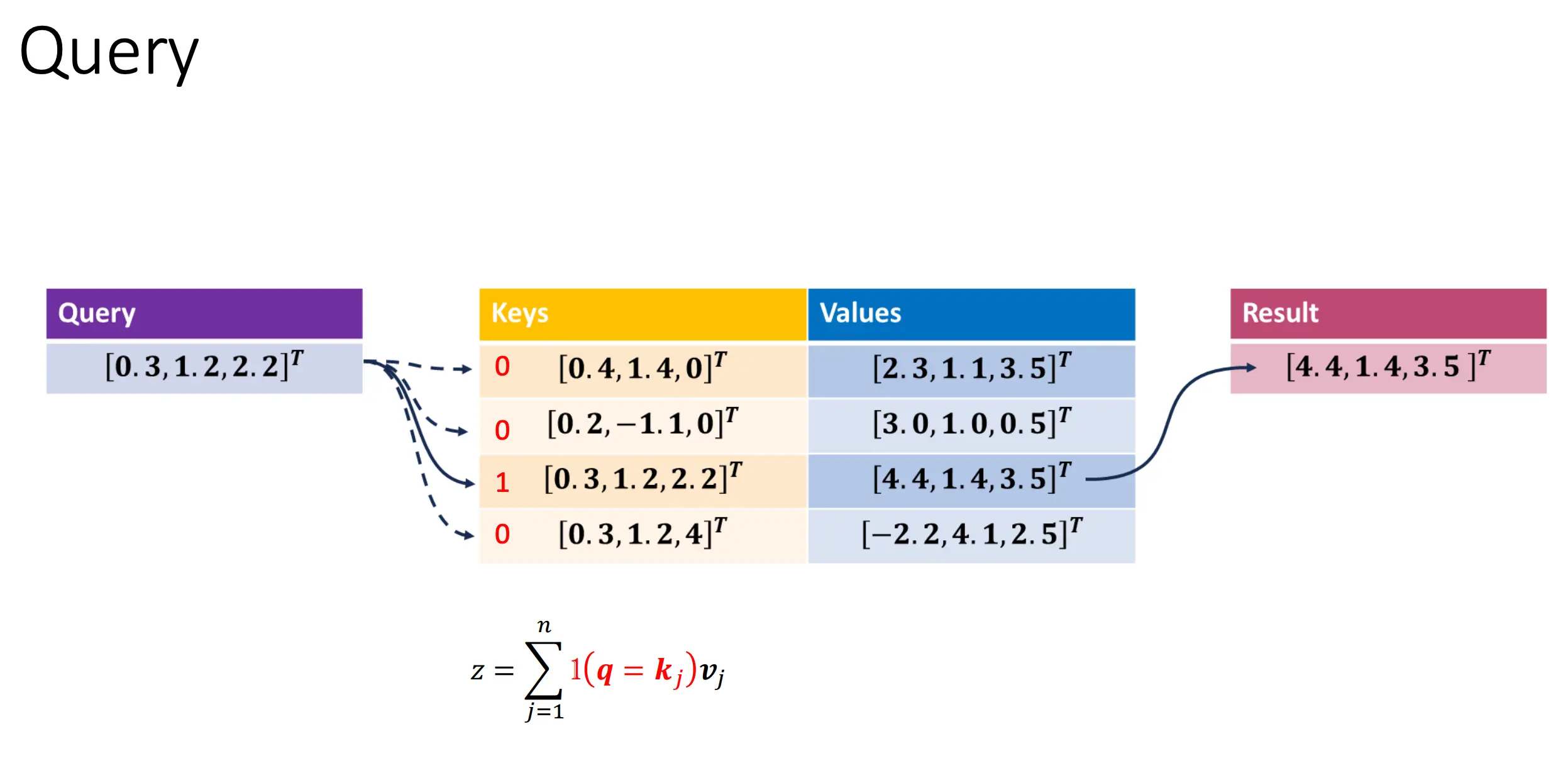
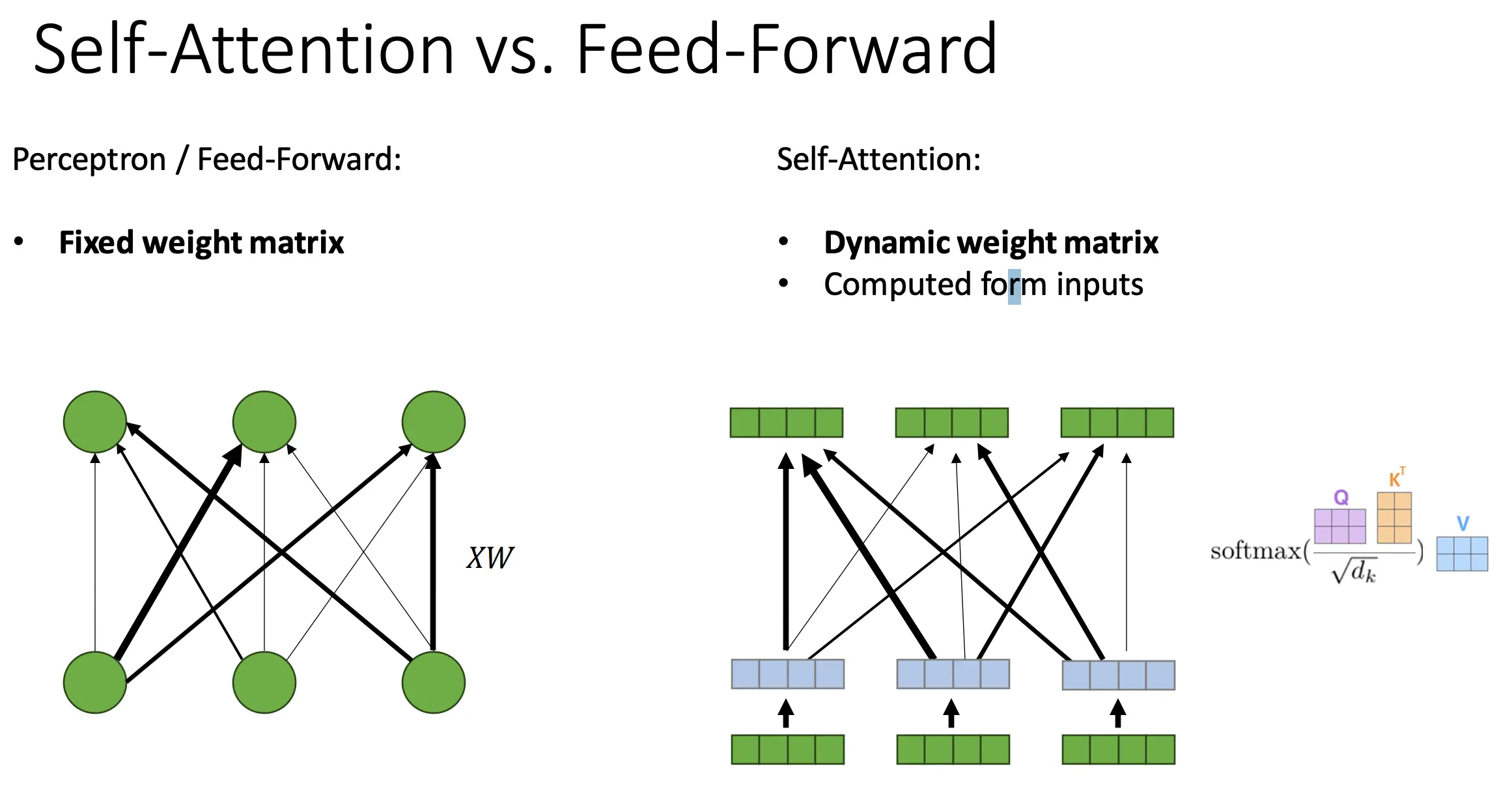
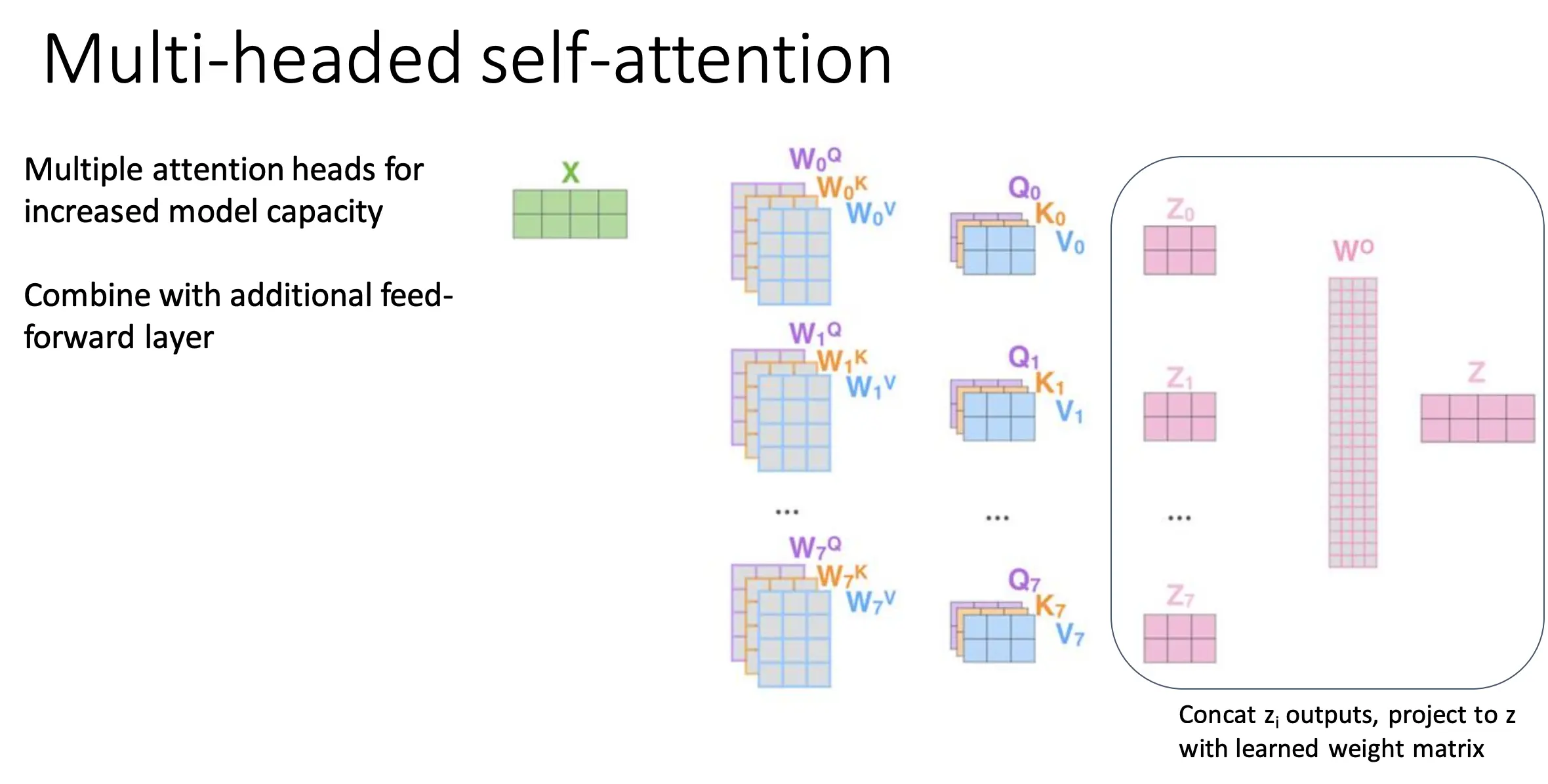
Self-Attention
序列中的每个元素都可以影响其他每个元素。 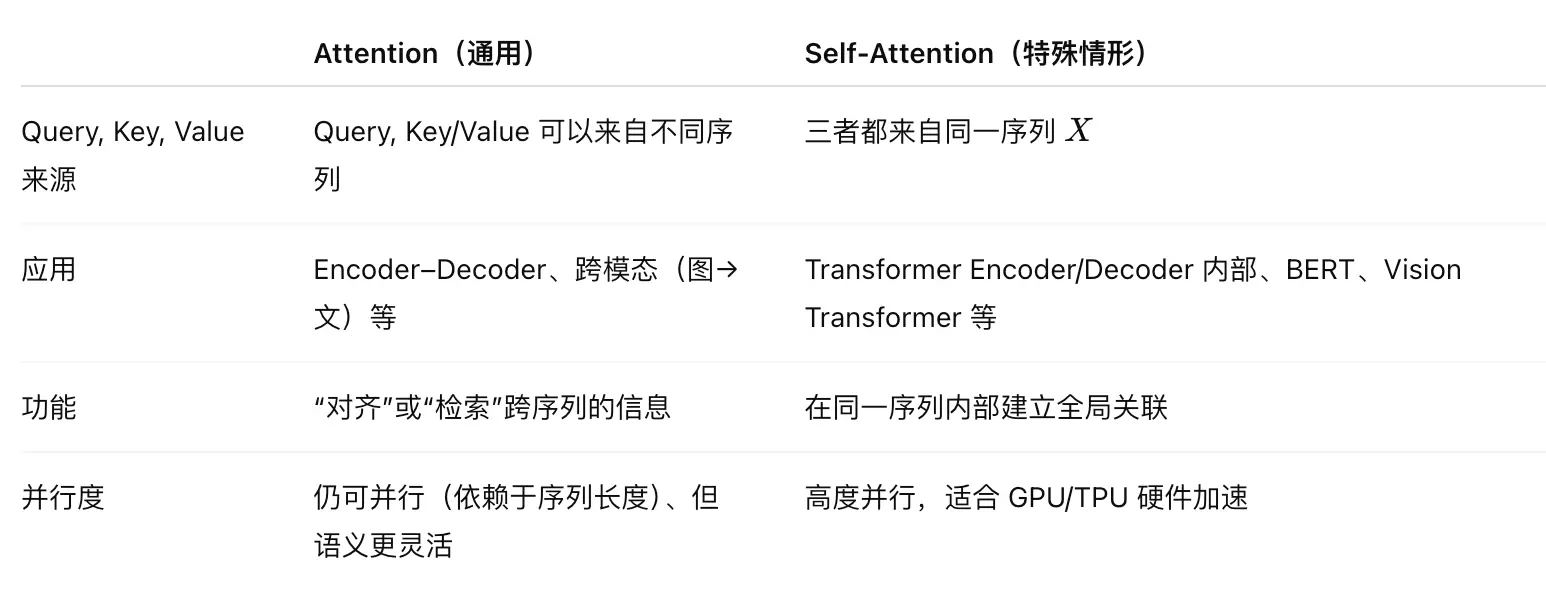
Encoder




Decoder
Decoder实际上就是一个自回归的过程: 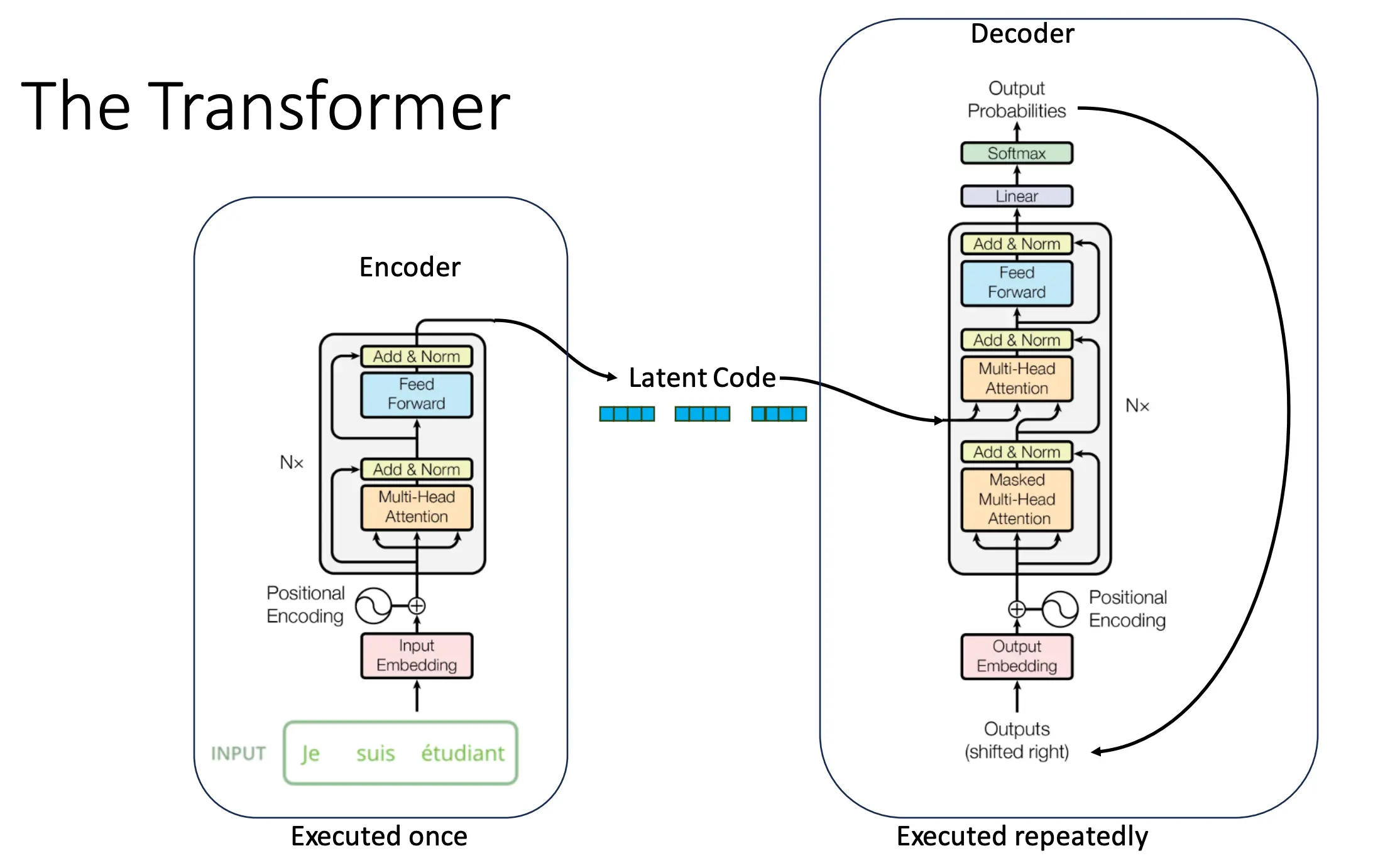 也是一个Cross Attention的过程:
也是一个Cross Attention的过程: 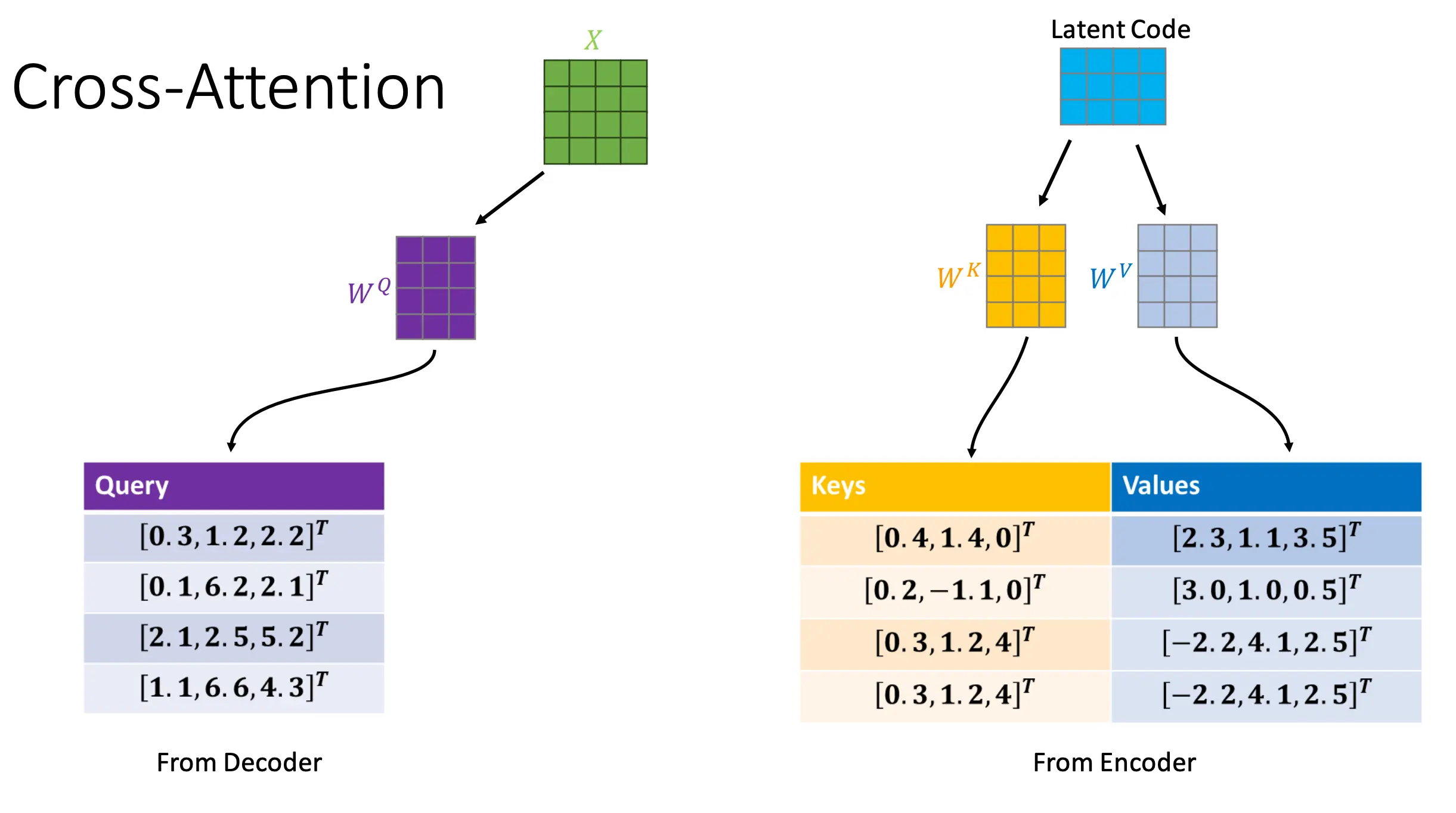
![]()
![]()
Training
首先,我们采用对decoder采用musked attention: 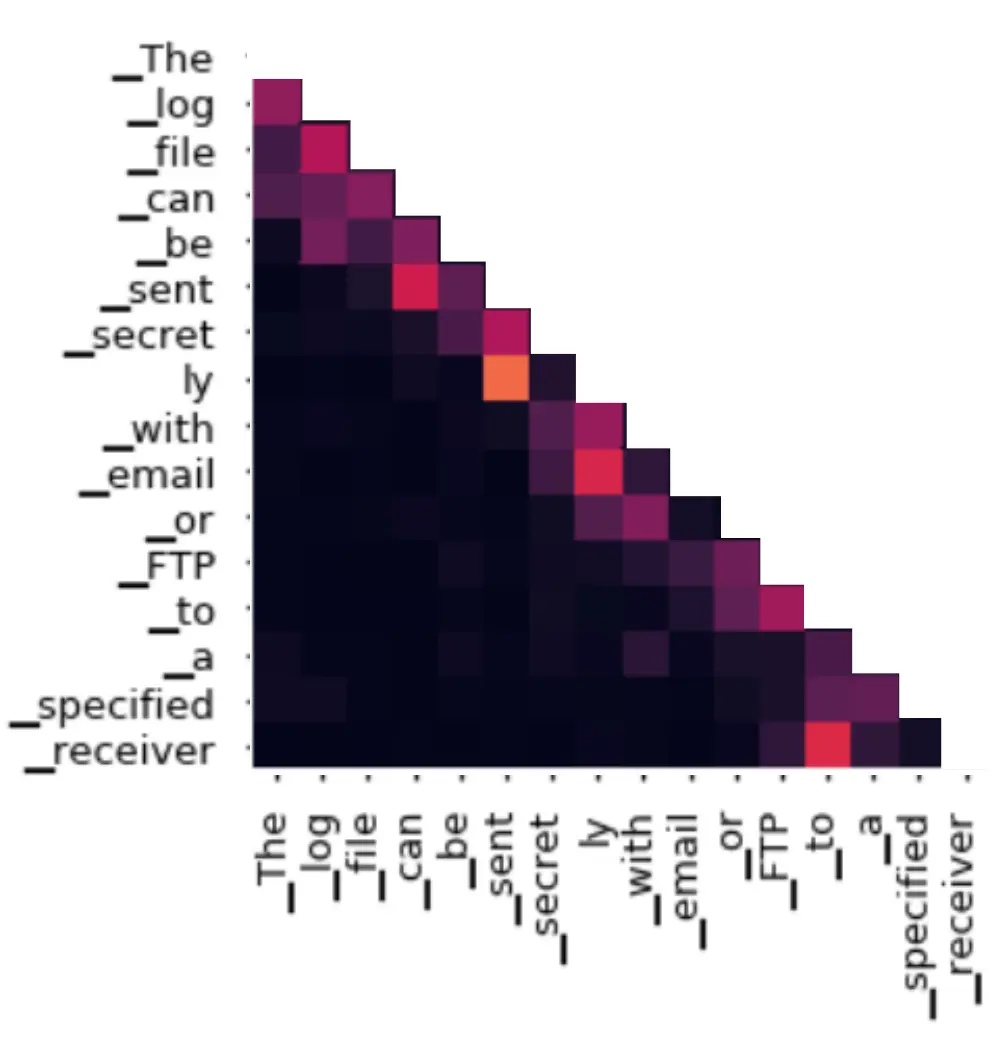 在计算注意力矩阵之前,把所有“未来”位置(即 ≥当前位置)的权重置为 −∞,经过 Softmax 后变成 0。 保证在训练时,用 teacher-forcing 把正确的前缀(“I am a”)喂给 Decoder,网络绝对不会看到后续词(“student”)的信息,从而满足自回归生成的因果性。
在计算注意力矩阵之前,把所有“未来”位置(即 ≥当前位置)的权重置为 −∞,经过 Softmax 后变成 0。 保证在训练时,用 teacher-forcing 把正确的前缀(“I am a”)喂给 Decoder,网络绝对不会看到后续词(“student”)的信息,从而满足自回归生成的因果性。
然后,decoders进行cross attention,以及feed forward,norm。 最后,与真实的下一个词(紫色“I”, “am”, “a”, “student”)做交叉熵损失,所有位置的损失加总(或平均)后,反向传播更新整个模型参数。 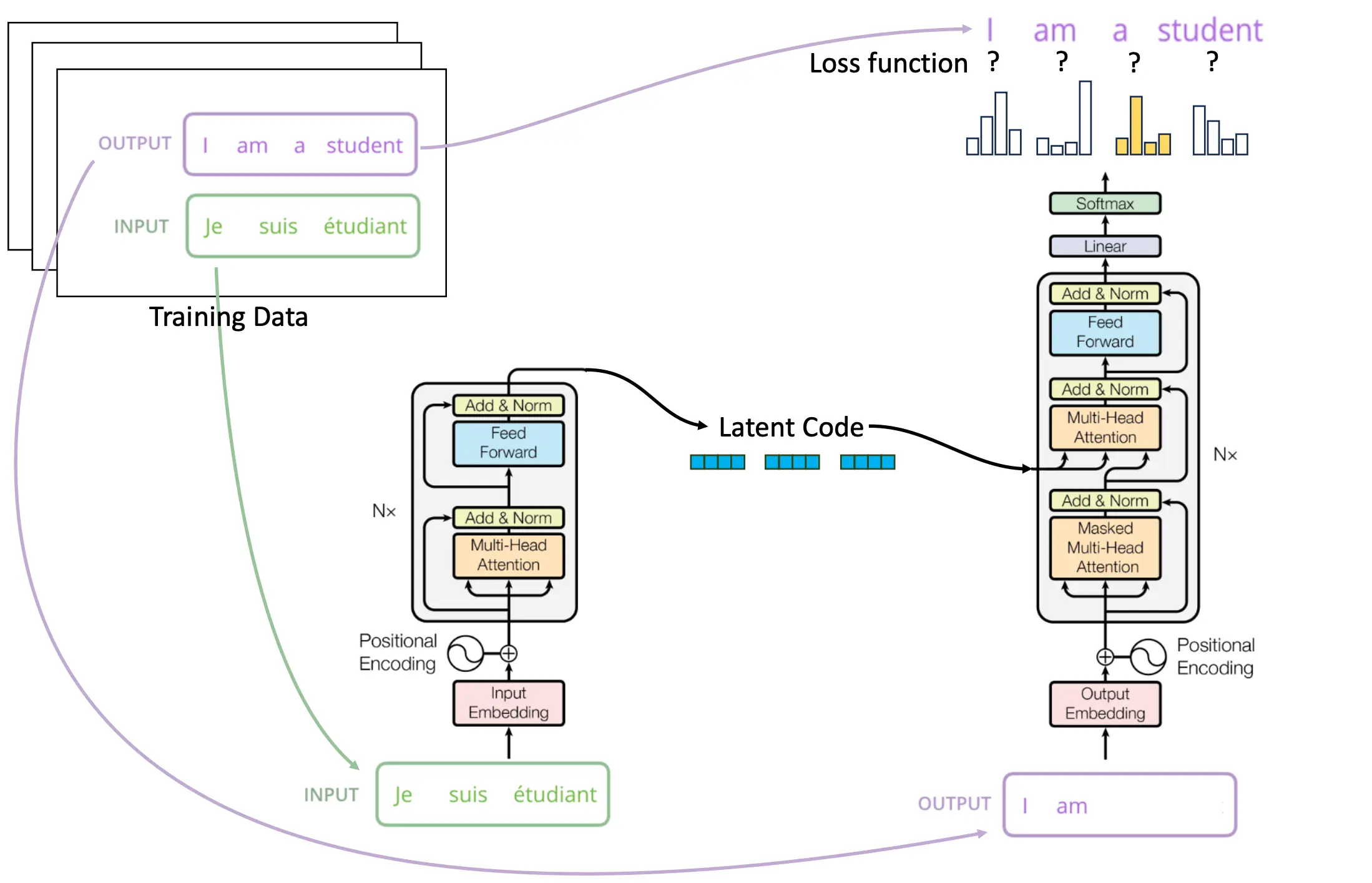
Generation
![]()
 Larry Shi
Larry Shi