Attention
Evaluate Machine Translation
接着我们上次的多层 Seq2Seq 5 - Sequence to Sequence Models and Machine Translation说: 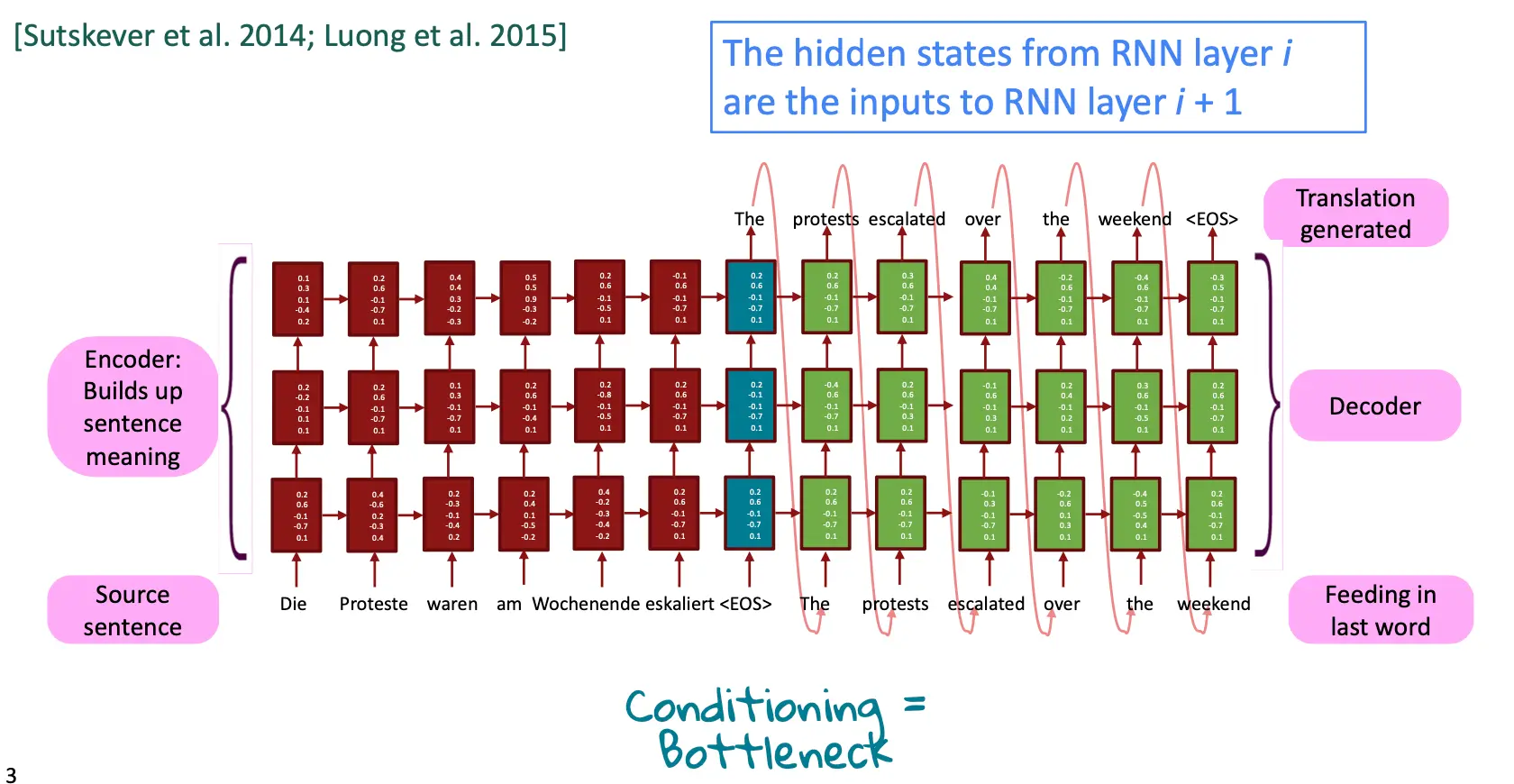 如何评价一个MT的质量呢? 最常用的方式是BLEU (Bilingual Evaluation Understudy)。这个方法比较机翻结果以及多个真人翻译的相似度,based on 几何平均 of n-gram 精度。 对于系统翻译过短的情况加penalty. BLEU挺有用的,但是不完美。实际情况下,一个句子有多种好翻译结果,但是BLEU只能衡量和他自己数据库里最像的一种,因为用的是n-gram 精度。 可以看到,Neural MT方法的BLEU上升很快。
如何评价一个MT的质量呢? 最常用的方式是BLEU (Bilingual Evaluation Understudy)。这个方法比较机翻结果以及多个真人翻译的相似度,based on 几何平均 of n-gram 精度。 对于系统翻译过短的情况加penalty. BLEU挺有用的,但是不完美。实际情况下,一个句子有多种好翻译结果,但是BLEU只能衡量和他自己数据库里最像的一种,因为用的是n-gram 精度。 可以看到,Neural MT方法的BLEU上升很快。 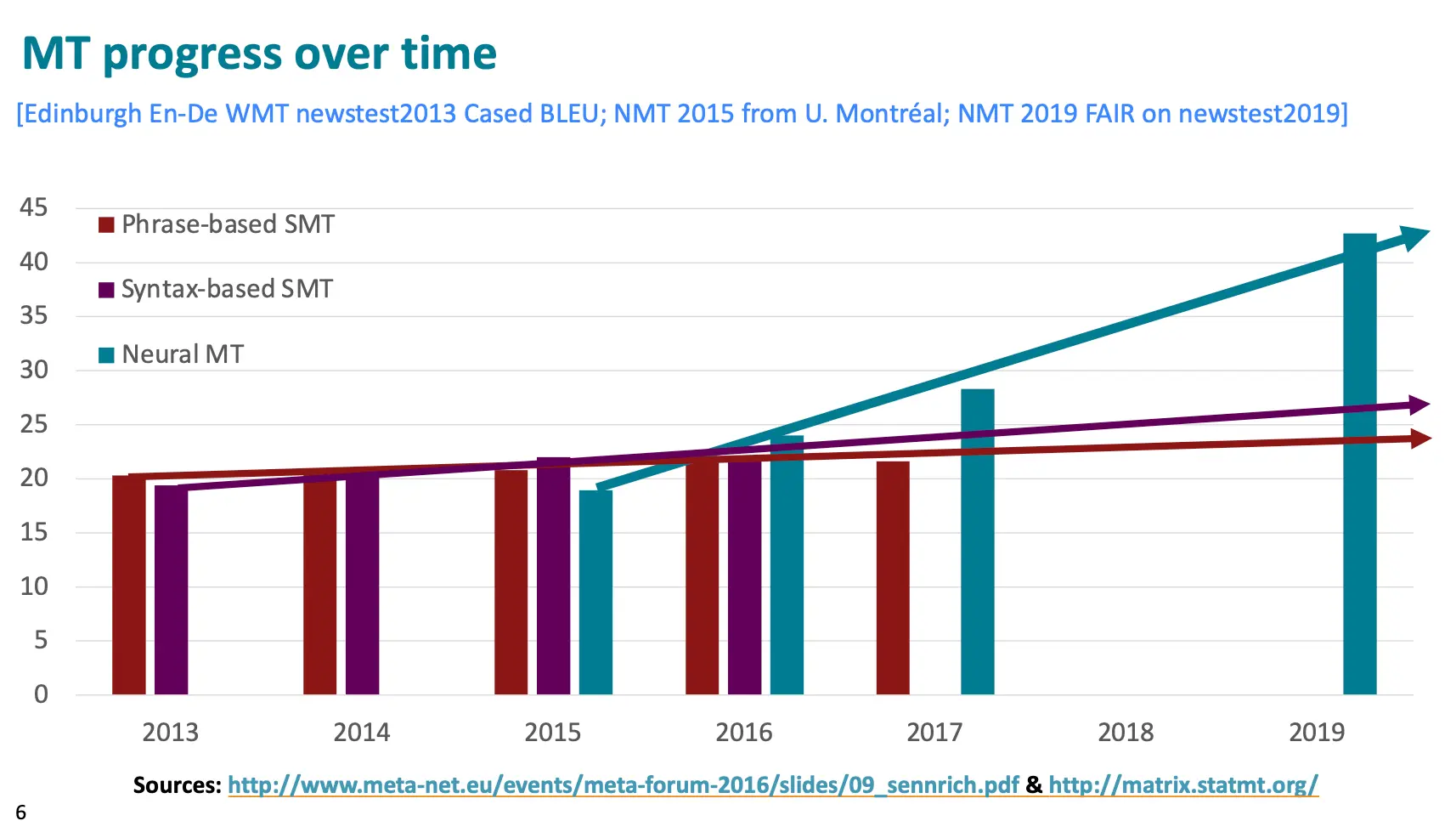
Attention 引子
我们说,Seq2Seq 是存在瓶颈的,因为原文不管多长都被encoding成了一个固定长度的隐藏状态,这必然导致失真。 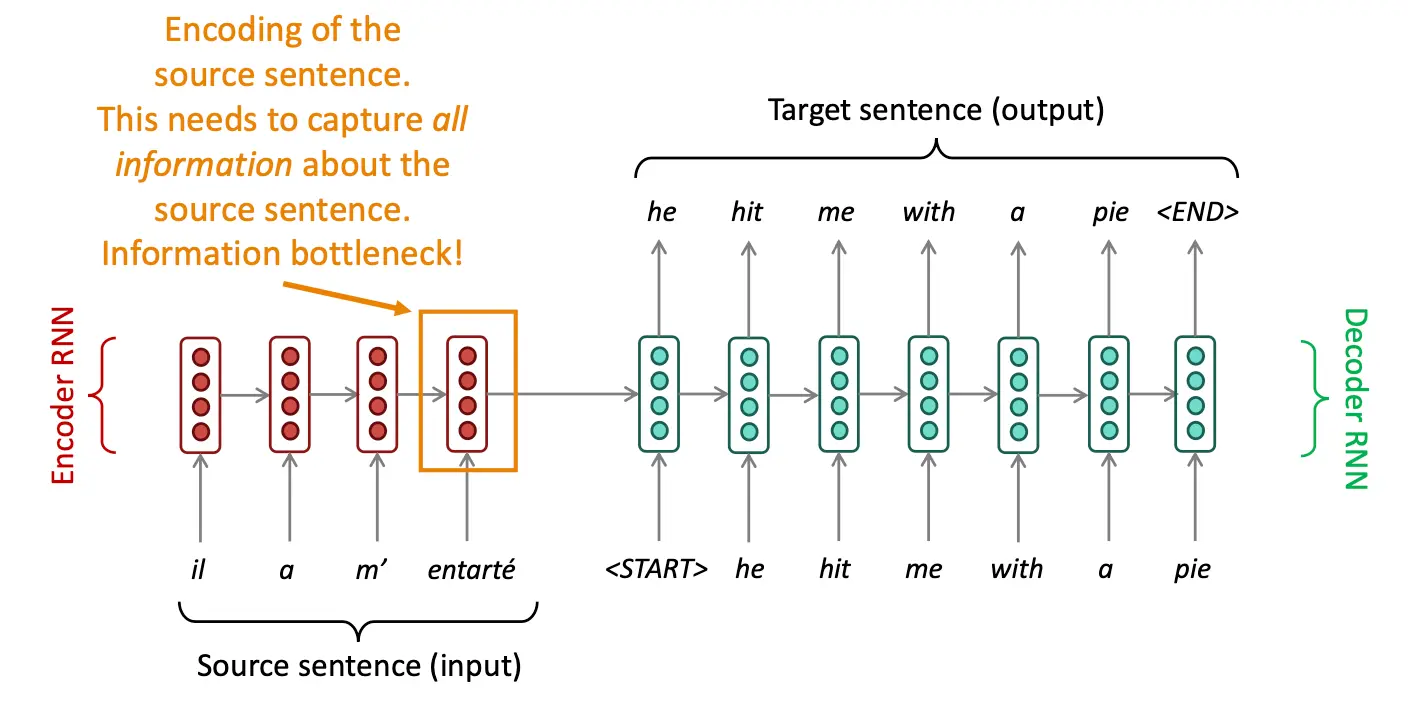 而Attention就提供了一个解决bottleneck的方案。核心idea是,对于decoder的每一步,直接连接到encoder的某一部分,直接获取源头消息。接下来展示一个大概的概念:
而Attention就提供了一个解决bottleneck的方案。核心idea是,对于decoder的每一步,直接连接到encoder的某一部分,直接获取源头消息。接下来展示一个大概的概念: 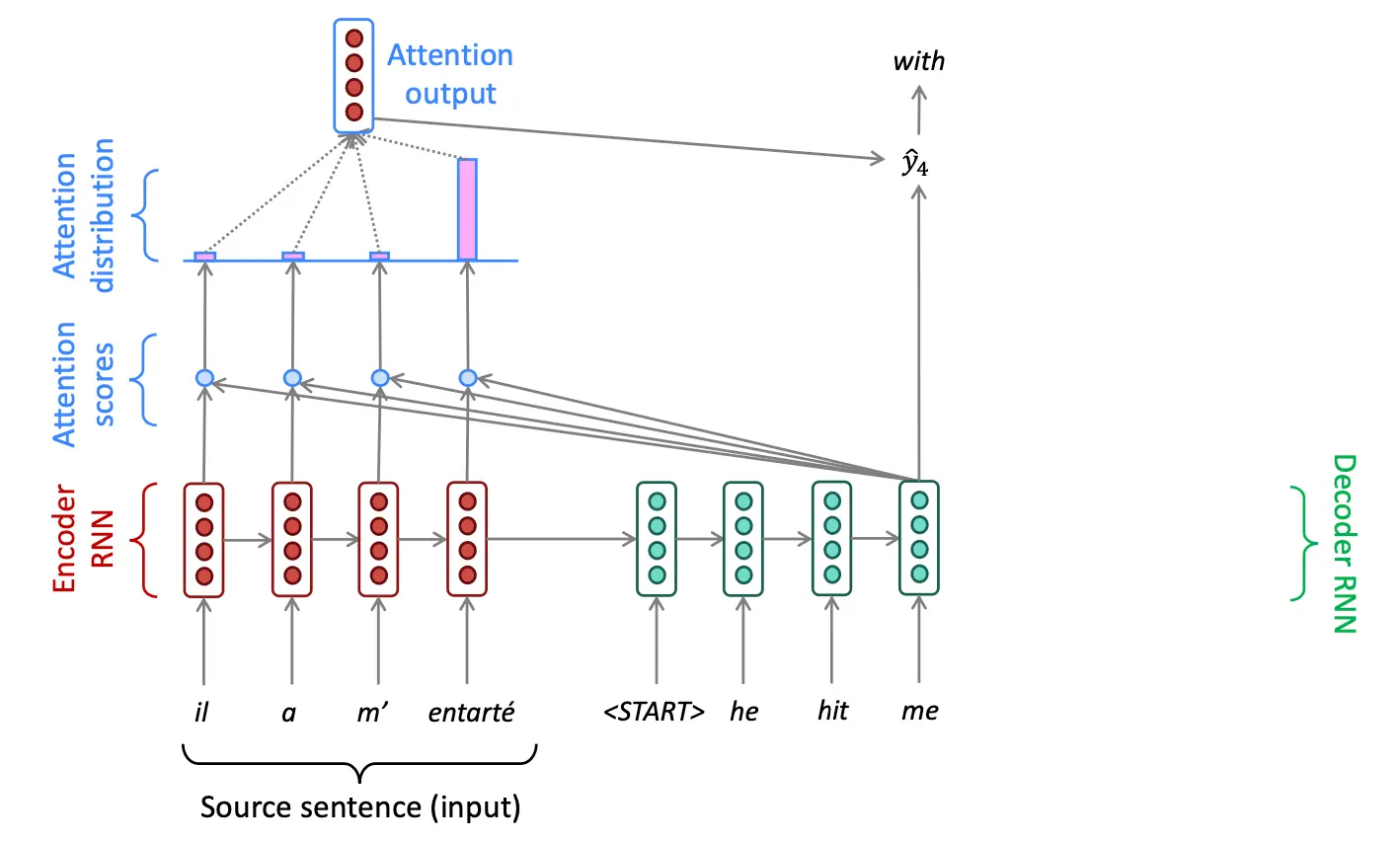
接下来展示Attention的等式形式: 对于encoder的每一个hidden state为
我们把每个时间步中,前面计算的e求softmax,得到百分比,也就是attention分布:
得到attention分布之后,进行加权和得到Attention output:
最后我们连接a和s传给seq2seq
实验证明,Attention很大的改善了NMT的性能,它提供了一种human like的模型,你可以随时溯源原文,而不是一次性全部记住。它很好解决了bottleneck的问题,也改善了梯度消失的问题,还提供了一些可解释性。 另外,attention可以让我们得到一个软的对齐系统,也就是你在目标语言选定一个词之后,可以看看attention分数的分布,也就大概获得了一个alignment。
Attention 变体
在Attention任务中,我们总有一些待被查询相关度的value h, 以及要被查询的关键字query s。
- 我们总是要计算attention分数 e,有很多方法可以做到,不一定是矩阵相乘。
- 我们总是要对e求softmax,得到attention分布a
- 我们总是要用attention分布对h进行加权和,得到一个attention output,或者context vector 而这些变体的区别,大多都在计算e上。
dot-product attention

Multiplicative attention
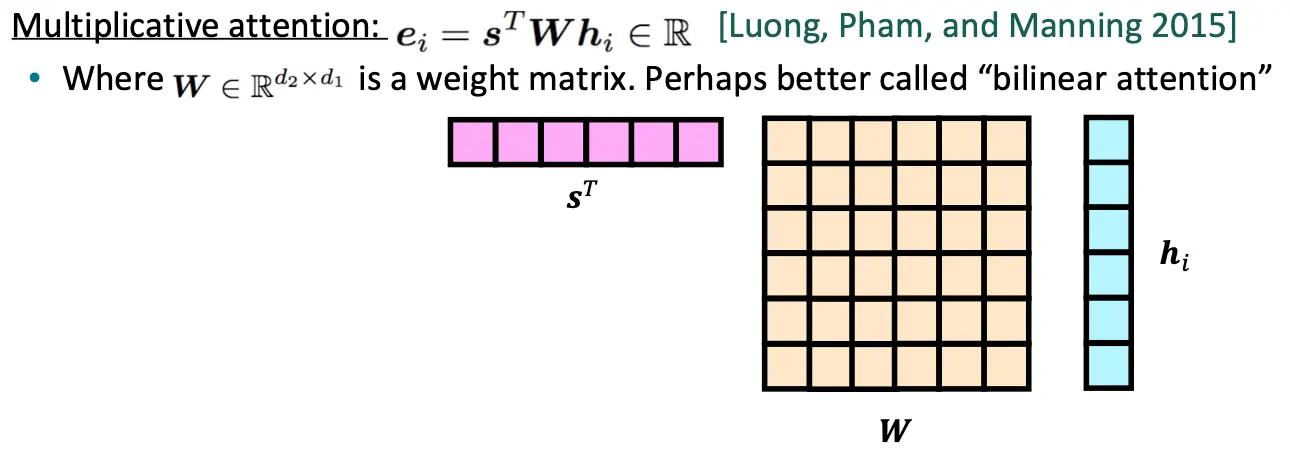
W是一个可学习的权重矩阵,首先将源向量 hi 通过权重矩阵 W 进行线性变换,使其与目标向量 s 的维度匹配。权重矩阵 W 提供了额外的灵活性,可以学习到更复杂的映射关系。 这种方法有时也被称为“双线性注意力(bilinear attention)”,因为它在 s 和 hi 之间引入了一个双线性变换。
Reduced-rank multiplicative attention 以及 Additive attention
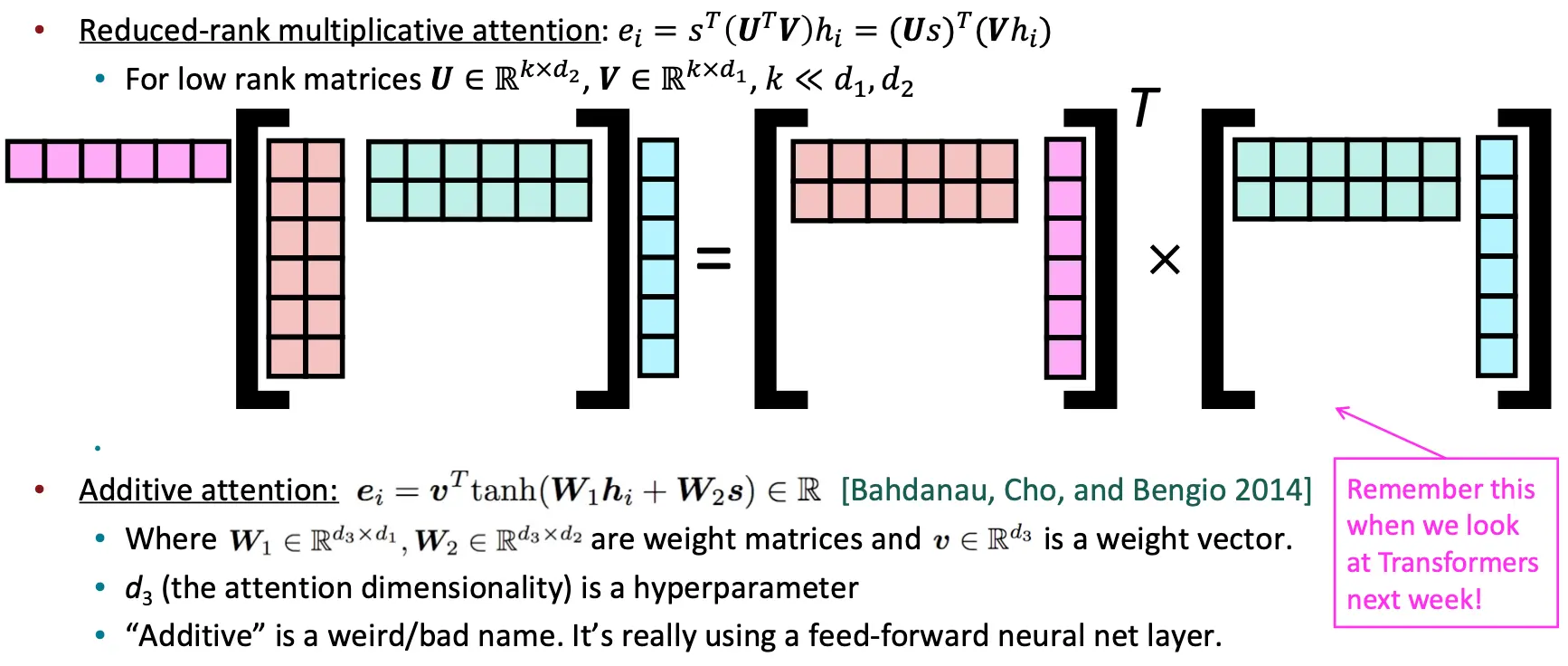
Attention是一个通用的DL技术,Given a set of vector values, and a vector query, attention is a technique to compute a weighted sum of the values, dependent on the query. 我们也把这个叫做query attends to the values. 在seq2seq中,decoder的hidden state attends to all the encoder hidden states. 加权和是对值中包含的信息的选择性摘要,其中查询确定要关注哪些值。 关注是一种获取任意一组表示value的固定大小表示的方式,这取决于query。
 Larry Shi
Larry Shi