复习课
线性回归
Linear regression (or least square regression)
- 如何对输入与输出之间的线性关系建模?
- 如何将均方误差(MSE)用作损失函数或评估指标?
- 作为损失函数时,它被最小化来训练模型;作为评估指标时,用于衡量模型预测的平均误差大小。
- 如何确定闭式解(或精确解)
- 求导

多项式回归
通过将原始特征映射到更高次幂的特征空间来拟合非线性关系的回归方法。
- 如何对输入与输出之间的非线性关系建模?
- 通过构造非线性特征,再在线性模型上进行拟合。
- 如何拟合多项式回归函数?
- 如何使用多项式函数映射特征?
- 如何处理回归中的欠拟合或过拟合?
- 欠拟合:模型过于简单,无法捕捉数据规律。可增加特征、提高多项式阶数、使用更复杂的模型。
- 过拟合:模型太复杂,拟合了噪声。可减少特征、降低多项式阶数、增大数据量或引入正则化。
- 如何在回归中利用正则化以避免过拟合?
- 岭回归(L2 正则化)Ridge Regression
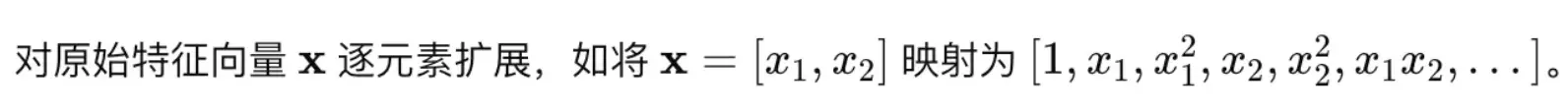
机器学习
- 如何描述/比较欠拟合与过拟合?
- 欠拟合:模型简单,训练误差高、测试误差高。
- 过拟合:模型复杂,训练误差低但测试误差高。
- 如何避免欠拟合过拟合?
- 避免欠拟合:使用更复杂模型、添加特征、减少正则化强度。
- 避免过拟合:收集更多数据、使用正则化、交叉验证选择超参数、简化模型。
- 如何描述“模型复杂度”/“模型选择”?
- 模型复杂度:模型能够拟合数据的灵活程度,参数越多或特征映射越高,复杂度越高。
- 模型选择:通过交叉验证或信息准则(如 AIC、BIC)在多个候选模型间选取最优者,即在偏差与方差之间取得平衡。
GD和线性分类
用的loss叫Surrogate loss
这样会促使ywx越来越大,那么margin就越大。
- 如何计算给定函数的梯度?不说了
- 如何描述步长(学习率)取不同值的影响?
- 步长过大:每次更新跨步过远,可能跳过最优点或导致发散。
- 步长过小:收敛速度非常慢,迭代次数增多。
- 合理步长:在稳定收敛与速度之间取得平衡,常用学习率衰减或自适应方法(如Adam、AdaGrad)。
- 如何使用梯度下降进行最小化?
- 如何用梯度下降做最小二乘回归?
- 如何比较或关联 GD、SGD、Mini-batch SGD?
- GD(批量梯度下降):每次迭代使用所有样本计算梯度,收敛稳定但计算量大。
- SGD(随机梯度下降):每次迭代只用一个样本估计梯度,更新频繁、计算快,但噪声大、震荡明显。
- Mini-batch SGD:每次迭代使用一小批样本,兼具稳定性和效率,是最常用的折中方案。
- 如何使用 SGD(或其变体)进行线性分类?
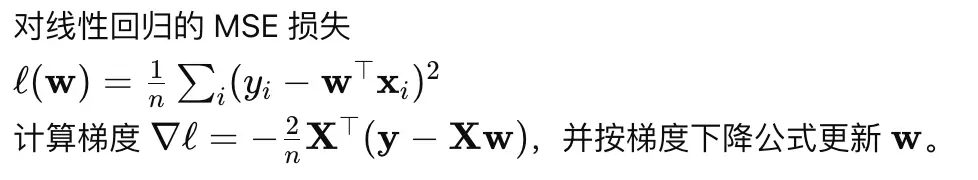
感知机和反向传播
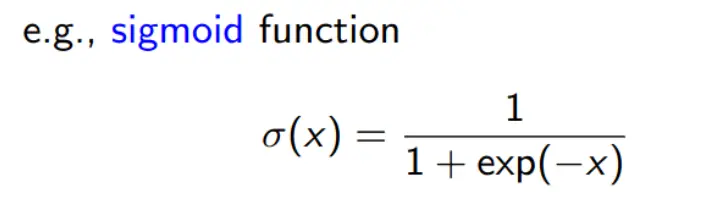
- 如何描述MLP网络的工作原理?
- 输入层:接受原始特征向量。
- 隐藏层:每个隐藏层节点计算前一层输出的线性变换并通过激活函数(如ReLU、sigmoid)得到非线性映射。
- 输出层:对最后一个隐藏层输出再做线性变换并(根据任务)通过激活函数(如softmax)得到预测结果。
- 如何描述或利用网络与梯度下降的关系?
- 网络参数(所有层的权重和偏置)共同决定损失函数值。利用梯度下降,在参数空间中沿损失函数的负梯度方向迭代更新所有参数,从而逐步降低训练误差。
卷积神经网络
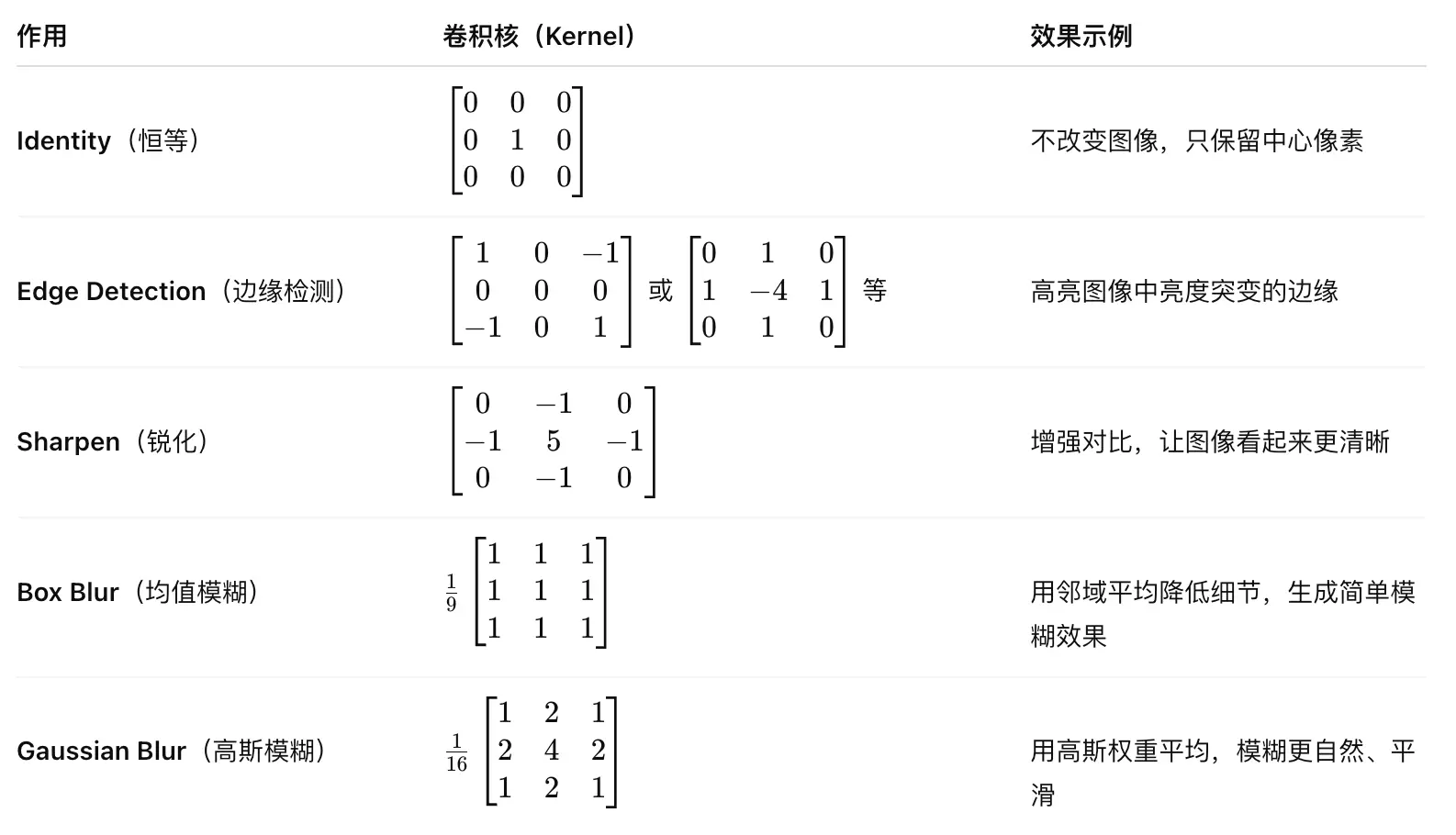
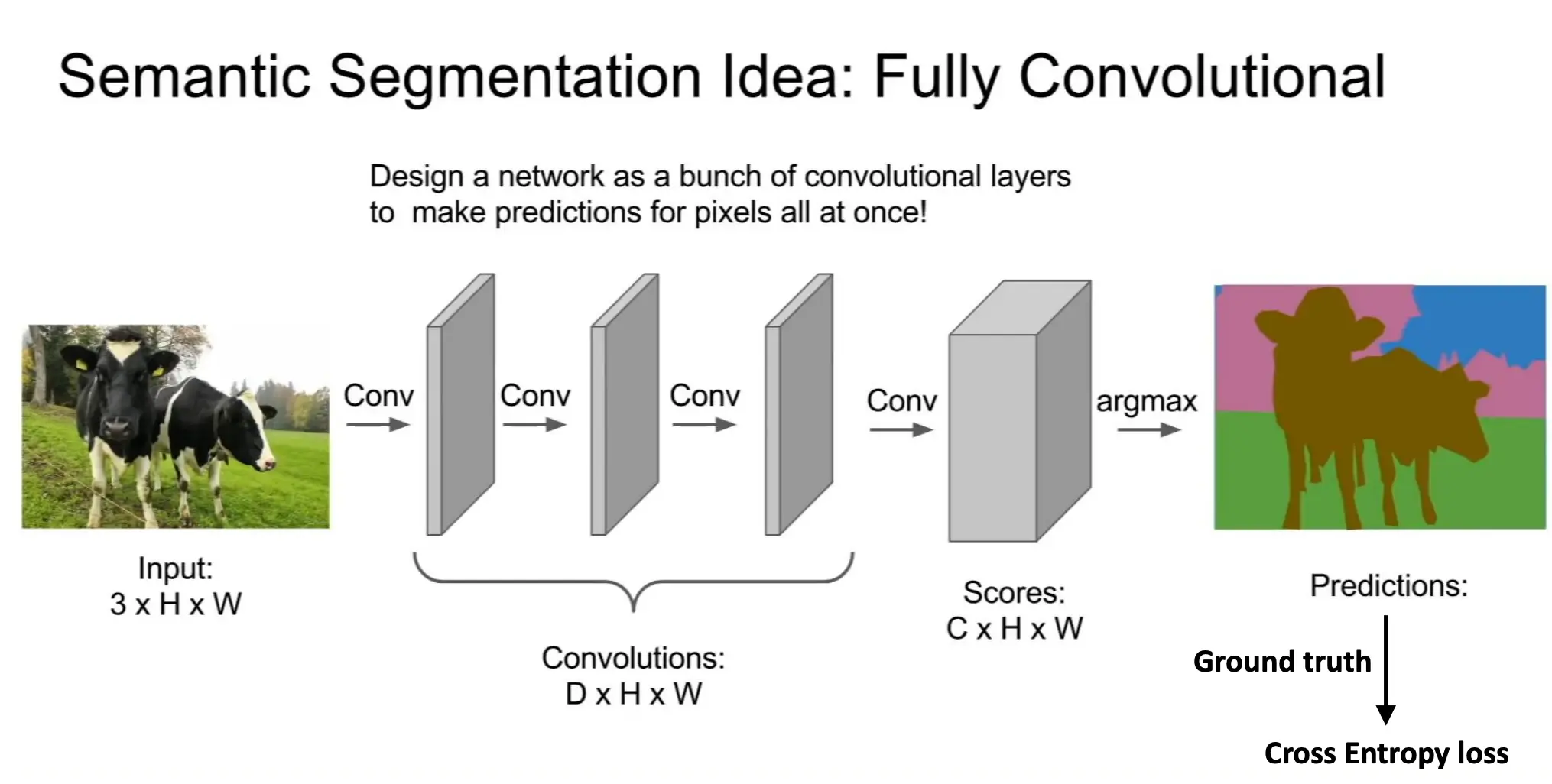
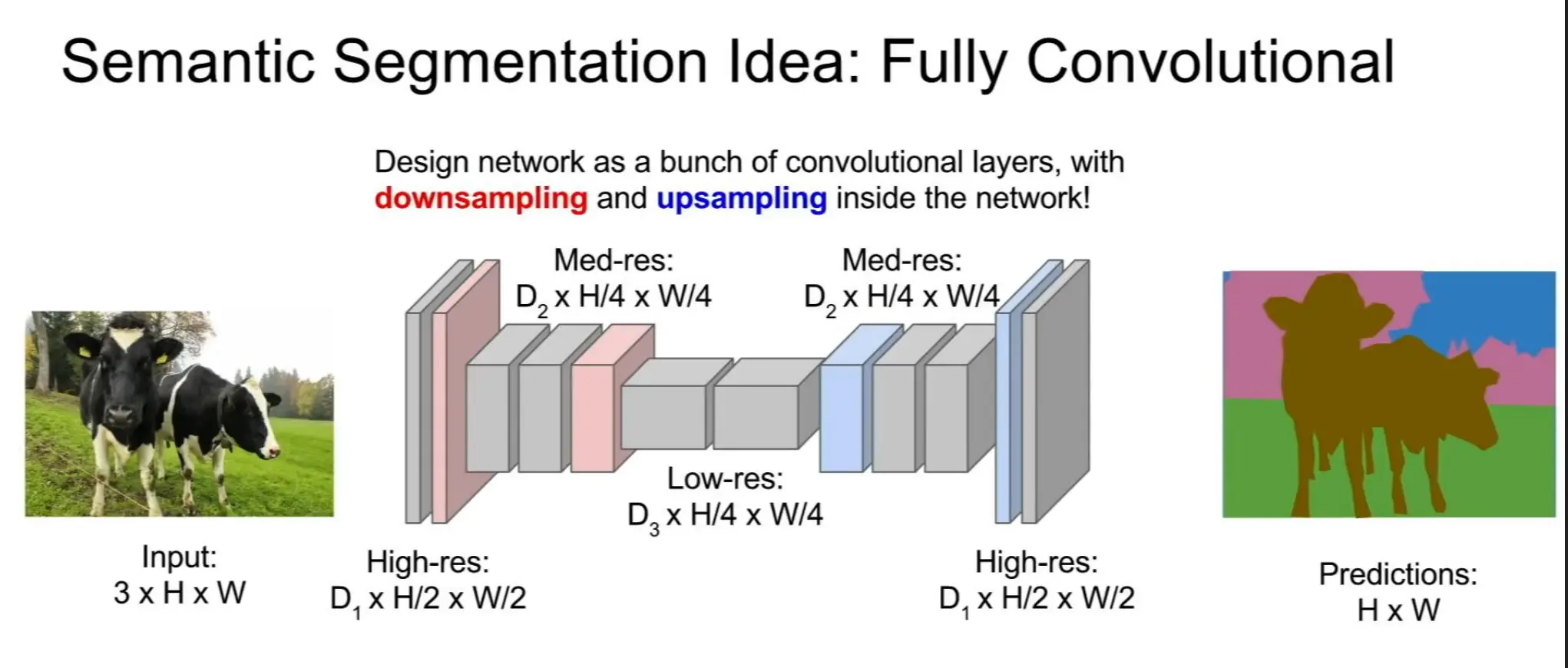 公式:
公式: 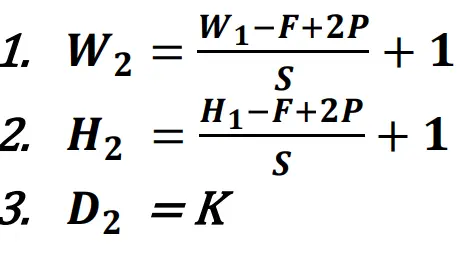
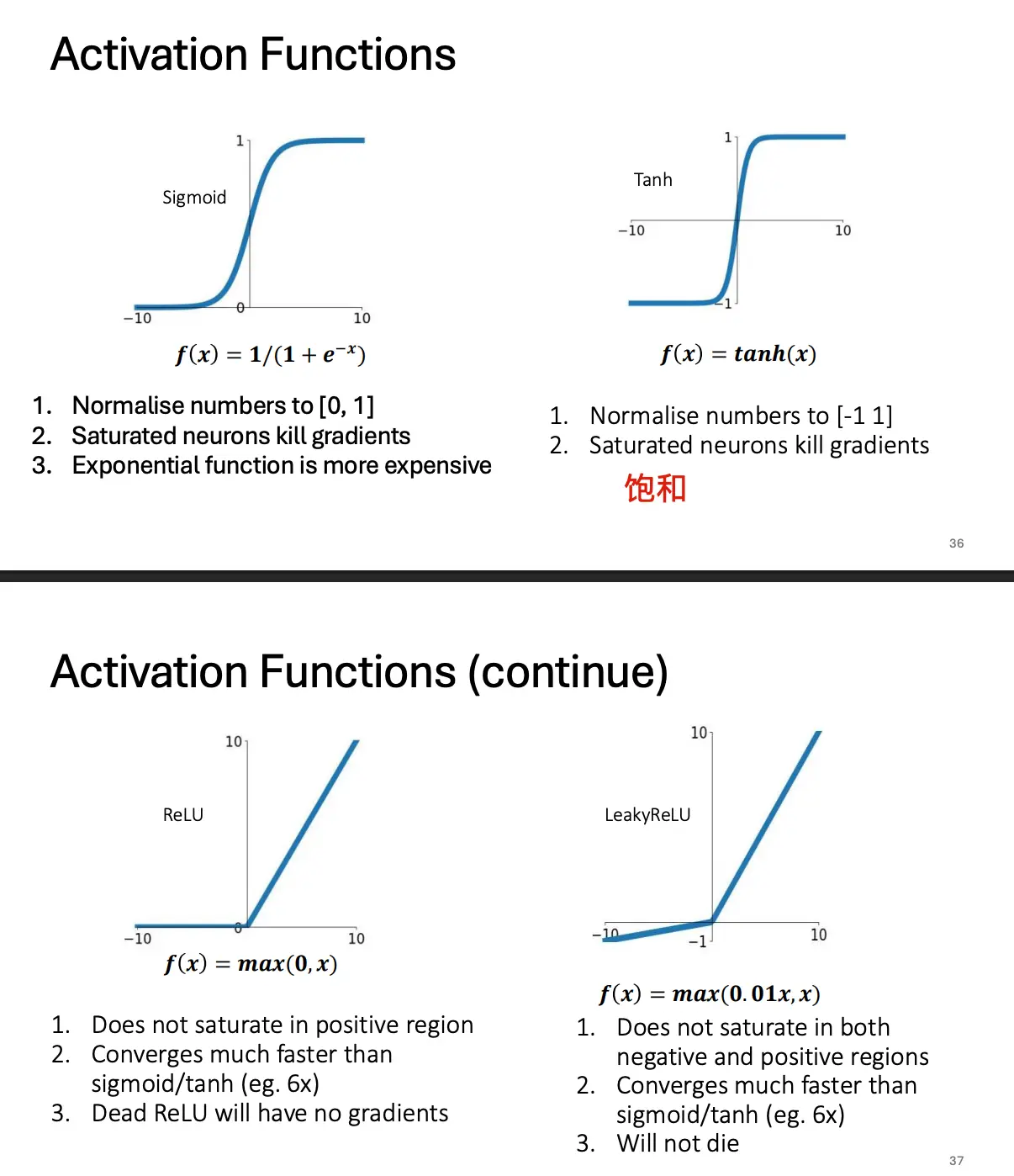
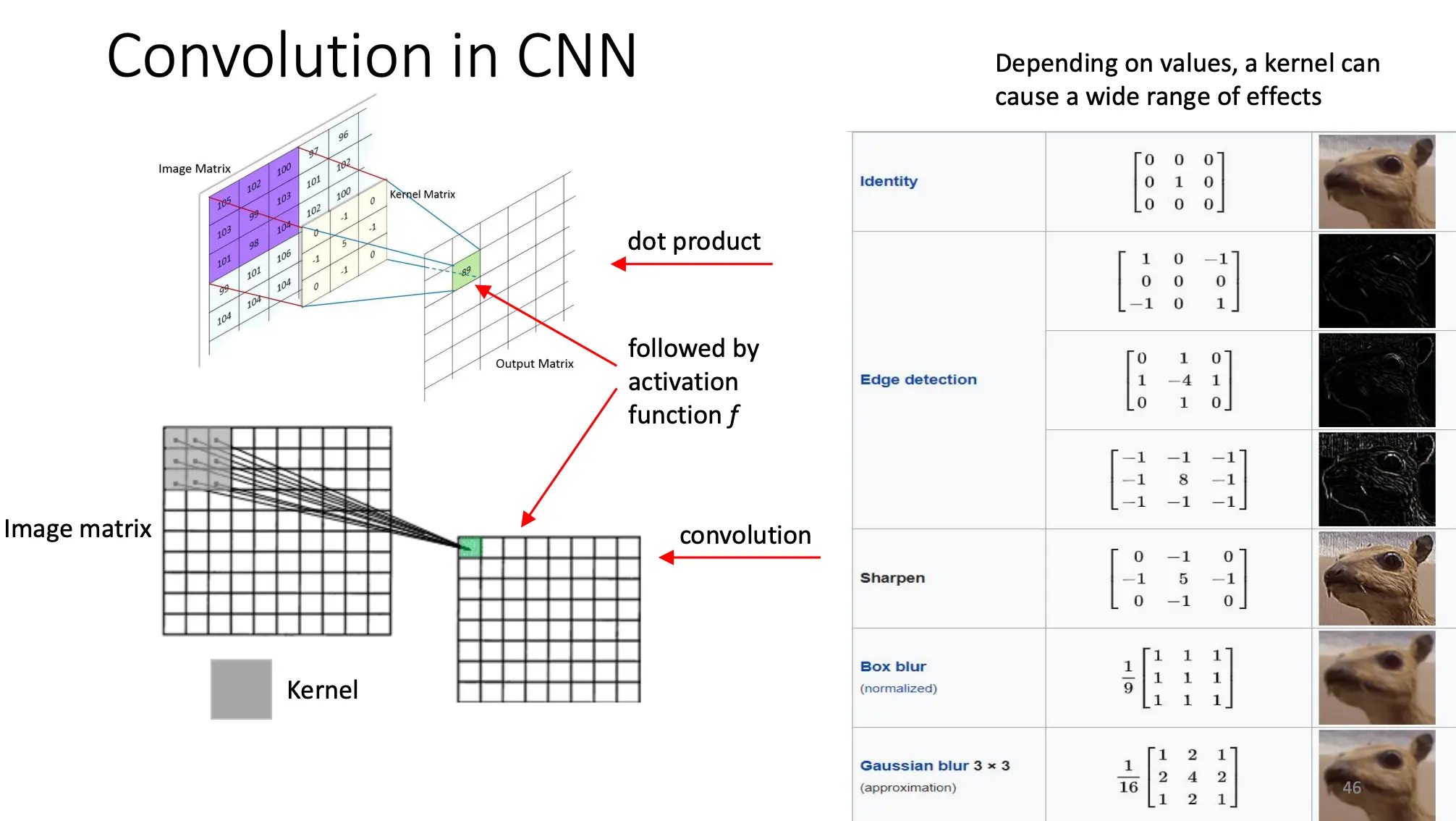
- 如何计算输入与卷积核的卷积?
- 做点积,不是矩阵乘法
- 如何计算池化操作的输出?(如最大池化、平均池化)
- 不重叠或有重叠的 p×p 小块(由池化窗口大小和步长决定)。
- CNN 的重要性质?
- 局部连接(local connectivity):每个卷积核只看小范围,捕捉局部特征。
- 参数共享(weight sharing):同一核在所有空间位置复用,显著减小参数量。
- 平移不变性(translation equivariance):同样的特征无论在图像何处都能被检测到。
- 层次化表达:低层学边缘、纹理,高层学语义、对象。
- 如何根据图像与卷积核预测响应?
- 按上述卷积公式,在图像上滑动核,对每个局部窗口做加权求和,得到响应特征图的每个像素值。
- 如何根据图像与响应反推卷积核?
- 视作线性方程组 Y=X∗KY = X * KY=X∗K,可用反卷积(deconvolution)、最小二乘法或频域除法(Fourier 变换下除以输入频谱)来估计 KKK。
- 尺寸?
- 可学习参数总数?

- 卷积相当于是 hwc 是卷积核的权重数,还有每个权重的偏执+1,然后乘以卷积核数
- 训练步骤?
- 明确任务(分类、检测、分割、生成等)。
- 数据准备:收集标注、划分训练/验证/测试集、做增强(augmentation)。
- 网络架构:选用或改造经典模型(如 LeNet、AlexNet、VGG、ResNet、U-Net 等),设定层数、通道数、核大小等。
- 训练细节:选择损失函数、优化器(SGD/Adam)、学习率策略、正则化(权重衰减、Dropout)。
- 超参搜索:调步长、批大小、网络深度等;用交叉验证或验证集评估。
- 上线与部署:模型压缩、加速推理(剪枝、量化),并根据实际需求做监控与迭代。
循环神经网络
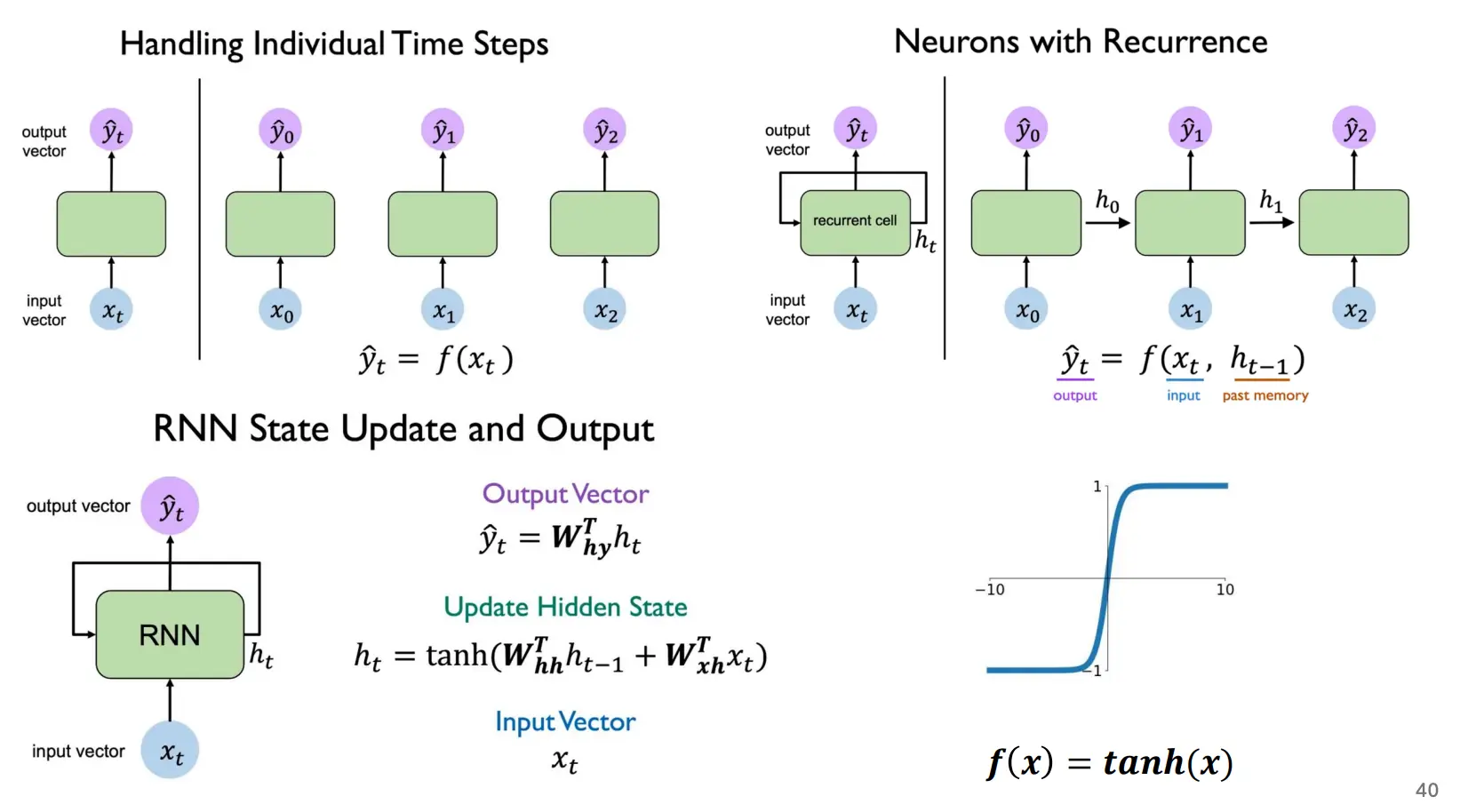

- RNN 如何处理可变长度输入?
- 将序列输入分解为若干时间步,将同一套参数在各时刻循环使用,每个时间步读入一个元素,直到序列末尾,自然支持可变长度。
- 隐藏状态在每个时间步如何更新?
- 图里有
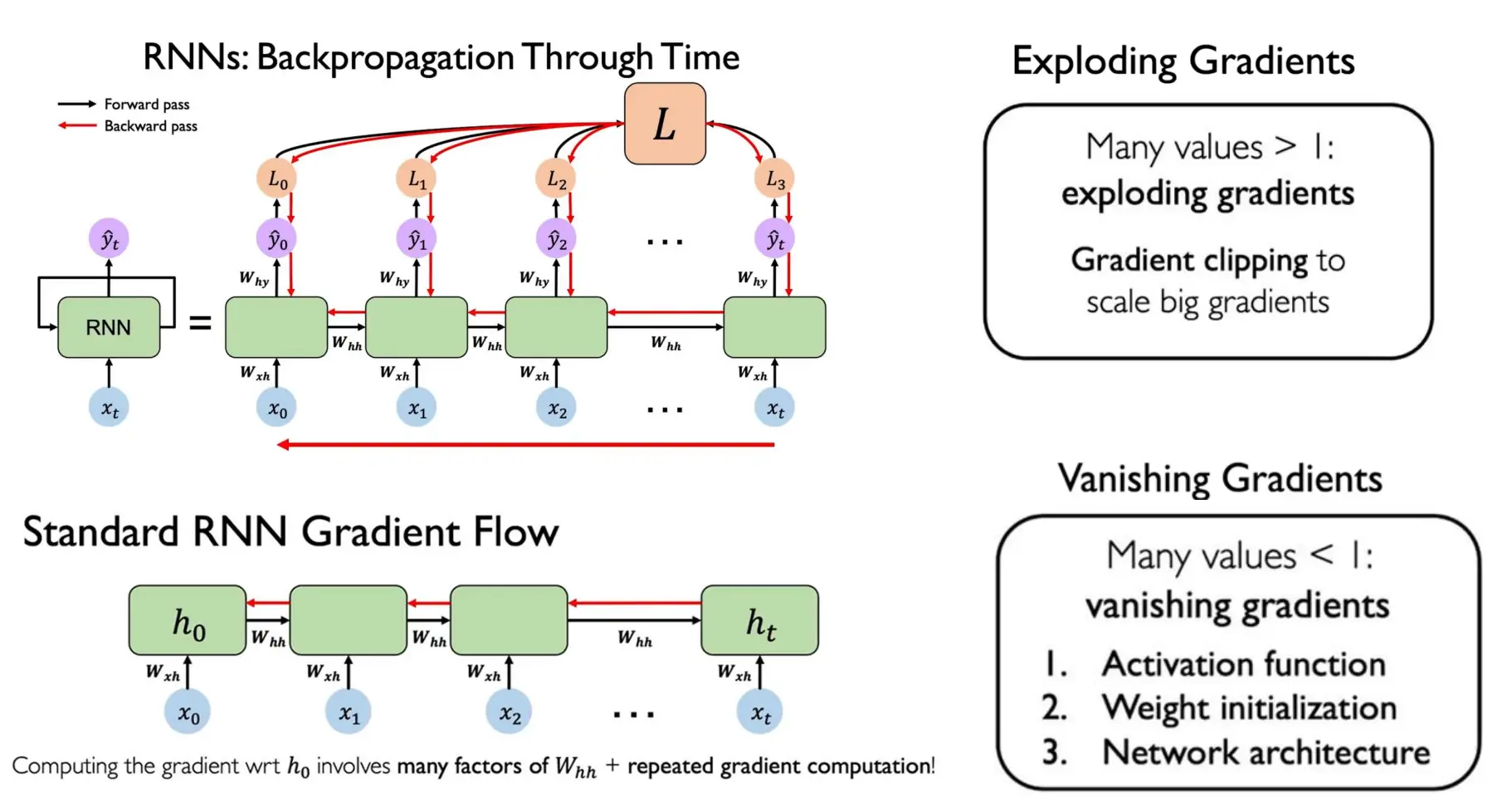
- 如何解决长期依赖问题?
- Vanilla RNN 本身难以捕捉长期依赖,会出现梯度消失或爆炸。通常通过梯度裁剪(gradient clipping)缓解爆炸,但消失问题需改用更复杂单元(如 LSTM、GRU)。
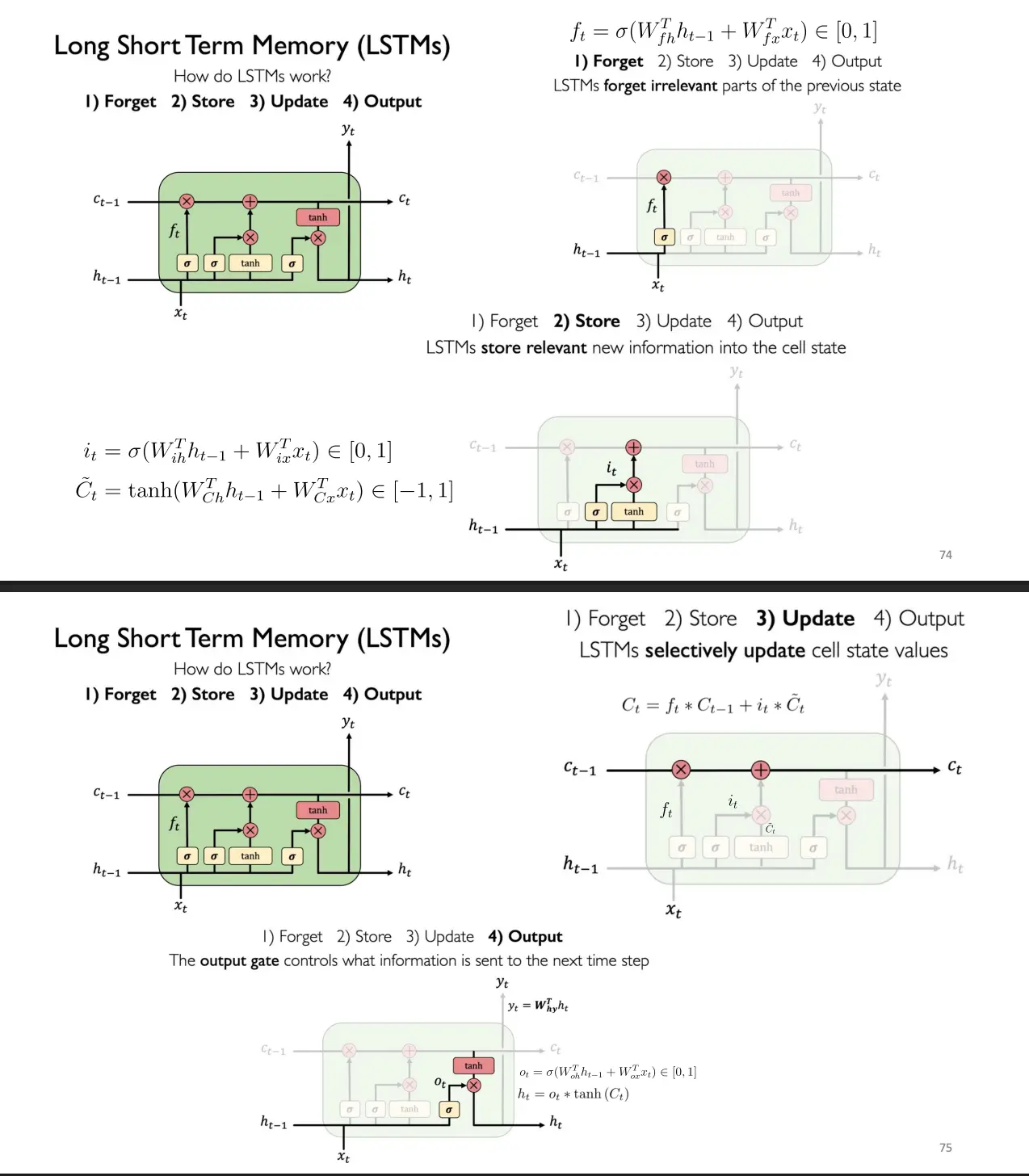
- LSTM 的工作原理?
- 为什么 LSTM 优于 Vanilla RNN?
- LSTM 的 细胞状态 通过加法更新,缓解了梯度消失,使网络能更好地保留长期信息。
- LSTM 如何处理长期依赖?
- 遗忘门决定保留多少过去记忆,输入门决定写入多少新信息,确保梯度沿加法路径稳定传递,实现对远期信息的有效记忆与利用。
- 各门(忘记门、存储门/输入门、更新、输出门)的角色?

AE和VAE
AE的Loss  加Bottleneck
加Bottleneck
VAE的Loss 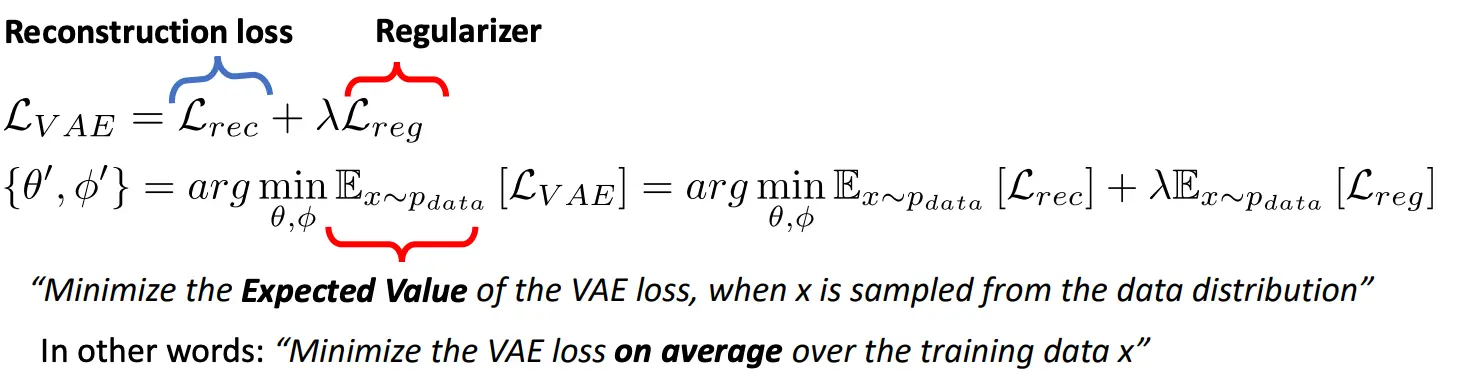 其中正则项是KL散度
其中正则项是KL散度
用重参数化采样从而可以训练 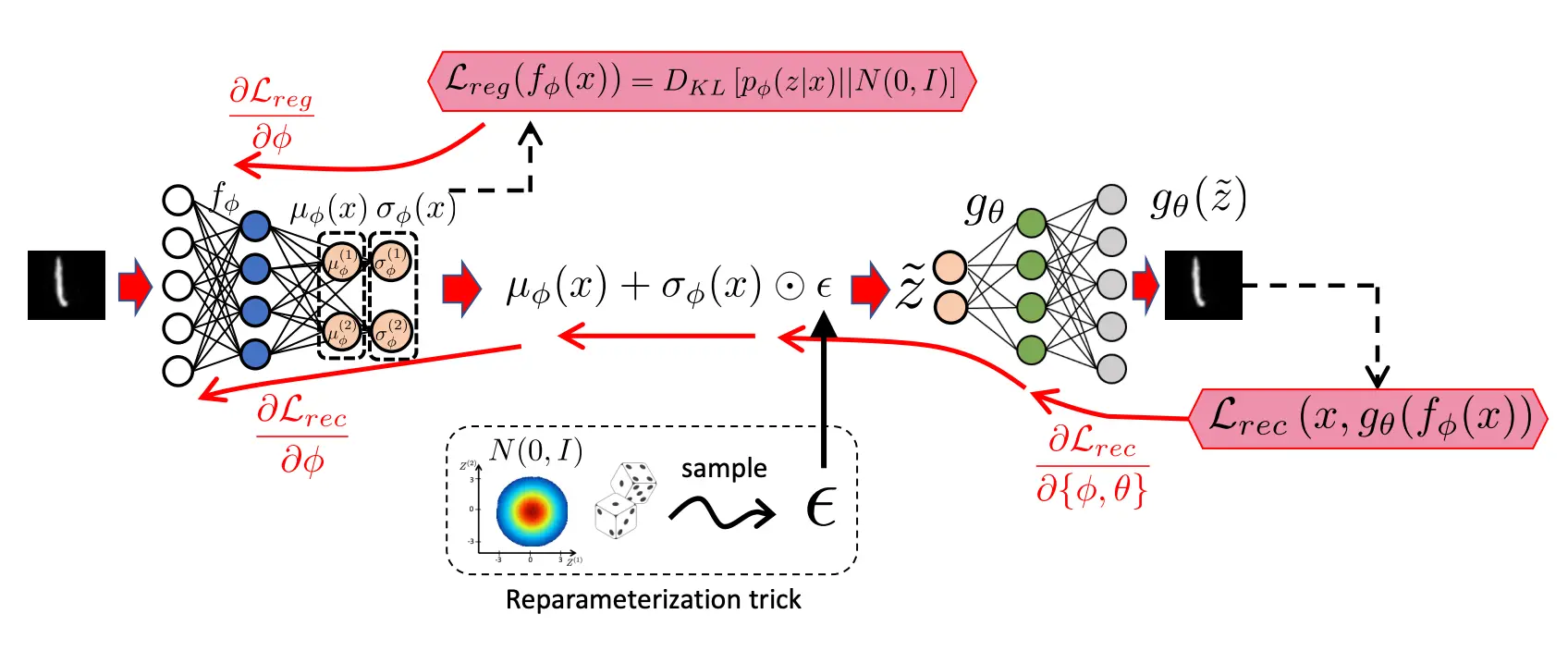
- 编码器(Encoder)、解码器(Decoder)和瓶颈层(Bottleneck Layer)的作用是什么?
- 编码器:把输入 xxx 映射到低维表示
- 瓶颈层:即 zzz,是网络中最窄的那层,限制信息流通,用来学习压缩后的特征。
- 解码器:把低维表示 zzz 重构回原始空间
- 如何训练自编码器?
- 最小化重构误差,常用损失
- 自编码器学习到了什么特征表示?
- 在瓶颈空间里,学习到能保留输入主要信息且尽量压缩冗余的低维稠密表示,往往捕获数据的主成分或潜在因子。
- 自编码器可以用于什么场景?
- 降维,聚类,预训练,去噪,生成,
- 自编码器的不足及原因?
- 缺乏生成能力:学到的瓶颈表示无法保证有良好的分布结构,随机采样往往生成无意义样本。
- 过于注重重构:可能只是“记住”训练样本而非提炼通用特征。
- 如何训练 VAE?
- 采用重参数化技巧使得梯度可传。
- 训练损失的各项如何影响 VAE 学习?
- 重构误差:鼓励解码器能准确还原输入。
- KL 散度:鼓励后验靠近先验高斯分布
- VAE 和基本 AE 有何关系?
- 二者结构类似,都是 encoder→bottleneck→decoder。
- VAE 在瓶颈层学习分布参数,并对潜变量作采样;AE 则直接学习一个点表示。
- VAE 如何生成新数据点?
- 在N(0,1)力采样z,然后给decoder
GAN
对于判别器D,1是真的,0是假的,这是定的。
理论中的D损失: 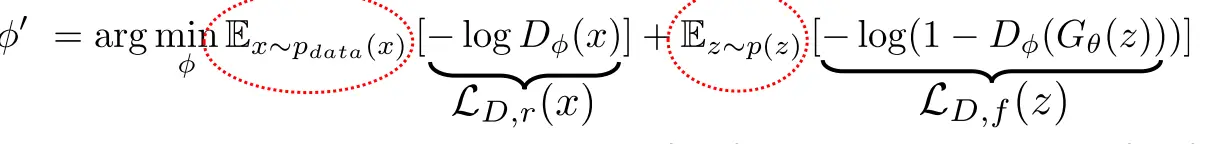 理论中的G损失:
理论中的G损失: 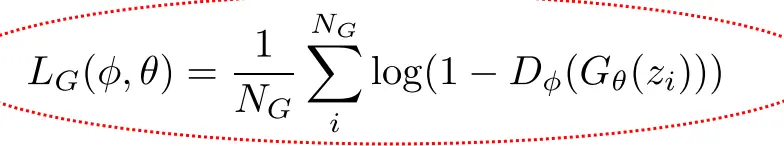 然而,理论损失在生成器表现差时梯度太小,不利于更新。替代损失在判别器确信假样本是假的时候给更大梯度,帮助生成器快速改进,故在实践中广泛采用。所以用这个损失:
然而,理论损失在生成器表现差时梯度太小,不利于更新。替代损失在判别器确信假样本是假的时候给更大梯度,帮助生成器快速改进,故在实践中广泛采用。所以用这个损失: 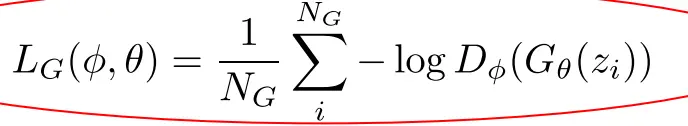
- GAN 模型在图像生成中起什么作用?
- 通过“博弈”方式学习从随机噪声到真实图像分布的映射,能够生成与训练数据在统计特性上相近但全新、未见过的图像样本。
- 生成器(Generator)和判别器(Discriminator)的作用是什么?
- 生成器 G:接收随机向量(噪声)输出伪造图像,目标是“骗过”判别器,使其认为生成图像是真实的。
- 判别器 D:接收真图像或生成图像,输出一个概率表示“该图像来自真实分布”的置信度,目标是正确区分真/假样本。
- 为什么称为“对抗”模型?
- G 和 D 的目标互为对立,生成器不断优化以“骗”判别器,判别器不断优化以“识破”生成器,二者在训练中相互博弈。
- 如何训练 GAN?

- 一般D训练2,G训练1
- 如何使用训练好的 GAN 生成新数据点?
- 从事先选定的先验分布(通常是标准正态)采一个随机向量,将 zzz 输入生成器,直接前向传播得到新图像
Diffusion Models
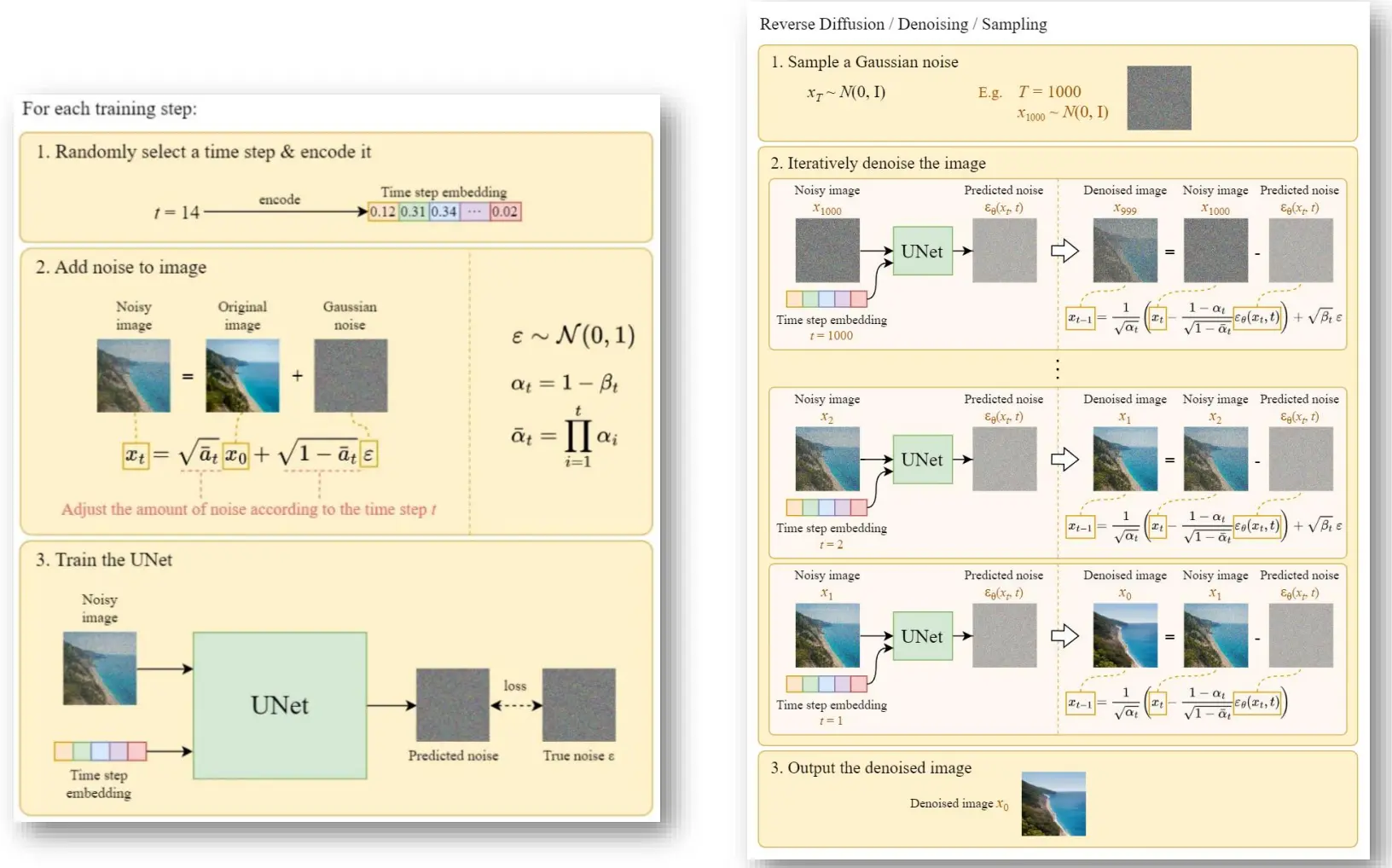
- 前向扩散过程(Forward Diffusion Process)如何工作?
- 为什么需要beta?
- 控制方差
- 控制噪声强度,少加一点噪音。beta应该远小于1.

- 为什么需要beta?
- 反向扩散过程(Reverse Diffusion Process)如何工作?
- DM 中的“去噪(Denoising)”部分是什么?
- 网络通常直接预测噪声
- 条件扩散模型(Conditional DM)如何工作?
- 在预测噪声或重构均值时,将条件信息 yyy(文本、类别标签、低分辨率图像等)一并输入网络:
- 文本,类别信息直接cross attention
- 图像可以拼接到通道理
- 这样逆扩散过程会生成符合条件 yyy 的样本。
- 在预测噪声或重构均值时,将条件信息 yyy(文本、类别标签、低分辨率图像等)一并输入网络:
- 什么是潜在扩散模型(Latent DM)?
- 在 VAE 或自动编码器的潜在空间中做扩散:首先用编码器把图像 xxx 映射到潜向量 zzz,然后在 zzz 空间做前向/反向扩散,最后解码回图像。
- 潜在 DM 与标准(像素空间)DM 有何关系?
- 标准 DM 在高维像素空间直接加噪、去噪;计算量大、显存需求高。
- 潜在 DM 在低维潜在空间进行噪声过程,效率更高、采样速度更快,且能在潜空间学习更语义化的特征。
- 为什么不能用回归模型代替做超分或者上色?
- 因为有很多可能的结果,diffusion做的是从分布中采样,而不是一个/

Transformer
Transformer 中编码器(Encoder)的作用是什么?
- 接收输入序列(如句子中的词向量),通过多层 自注意力 + 前馈网络 提取上下文依赖信息,输出一组“上下文感知”的隐状态表示
解码器(Decoder)的作用是什么?
- 接收编码器输出的上下文表示 {hi}{h_i}{hi} 及自身先前生成的目标序列(或训练时的真实目标),通过自注意力、交叉注意力和前馈网络迭代生成新 token 的概率分布,最终输出预测序列。
注意力(Attention)的作用是什么?
- 让模型在处理某个位置时,能够“聚焦”输入序列(或已生成序列)中对当前预测最重要的部分,用加权和整合相关信息,解决远距离依赖问题。
什么是自注意力(Self-Attention)?
- 在同一序列内部计算注意力:对每个位置 iii,根据查询 qiq_iqi 与所有键 kjk_jkj 的相似度计算权重,再对所有值 vjv_jvj 做加权和,得到位置 iii 的新的表示。既可捕捉局部也可捕捉全局上下文。
训练时解码器如何使用“已有输出”?
- Teacher Forcing:训练阶段,解码器在时间步 ttt 使用真实的前 t−1t-1t−1 个目标 token 作为输入,计算自注意力和交叉注意力,从而预测第 ttt 个 token,快速收敛。
推理(Inference)时解码器如何使用“已有输出”?
- 自回归生成:推理阶段没有真实目标,解码器每一步使用前一步模型自身生成的 token 作为输入,迭代产生新 token,直到遇到终止符(如 eos)或达到最大长度。
Transformer为什么要Norm?什么Norm?
- 用的Layer Norm。
- 稳定梯度流,如果不做归一化,激活值的分布会在层与层之间产生漂移(drift)
- 加速收敛:归一化可以让每一层的输入保持在相对稳定的分布范围内,使得学习率可设得更大,训练更快。
- 配合残差连接,保证了 x + Sublayer(x) 的输出分布不会随层数积累而失控。
为什么RNN用tanh,CNN用ReLU
- 如果RNN用ReLU,那么如果中间出现0,那么就可能出现死神经元或者梯度爆炸。tanh更平滑(smooth),符合时间上的传递。
- CNN用ReLU因为要缓解梯度消失,不会像tanh一样在大幅度输入的时候接近0.
低分辨率→高分辨率、黑白→彩色、缺损→完整,这些输入往往有 无穷多 合理的重建结果。
- 如果你用常规的回归(最小化 MSE)去预测每个像素的“最好估计值”,网络会学到“所有可能答案的平均”——结果往往 又脏又糊,没有鲜明的纹理细节。
时间的话,就先encode成一个vector embedding,然后在unet的每一层加法注入(也可用FiLM)
图像的话,就与图像做channel-wise concatenation,然后feed into unet
文字的话,先encode成vector embedding,然后给unet添加cross-attention去做融合
Transformer teaching force的作用
- 可以加速收敛,梯度稳定
- 可以并行
Transformer 位置编码作用
- 弄清顺序和相对位置。Order and relative position

- 如何避免梯度爆炸?
- clipping
- 如何避免梯度消失?
- activation function
- weight initilization
- network architecture
 Larry Shi
Larry Shi