Week 7-8 Recommender System
推荐系统是根据用户的一些信息为用户过滤内容的任何系统。 推荐系统有如下的动机:
- 信息过载(choices overload)
- 个性化(personalization)
- 提升决策质量与用户体验
- 增加平台转化率与销售额
RS的成功视角判断
- 多视角/多目标
- 不存在一个通用的、放之四海皆准的评价体系
- 信息检索(Retrieval)视角
- 快速帮用户定位想要的内容。降低搜索成本,提供“正确”候选,用户心里有数。
- 推荐(Recommendation)视角
- 给用户带来“惊喜”,发现长尾中的潜在感兴趣项。
- 长尾指的是那些小众能满足用户需求,但是知道的人少的东西。
- 预测(Prediction)视角
- 精确地预测用户对某个物品的喜好程度(打分)。
- 如 RMSE、MAE 等
- 交互(Interaction)视角
- 在推荐过程中让用户感觉良好,同时帮助他们更深入地了解产品领域。
- 转化(Conversion)视角
- 在商业环境下通过推荐直接提升业务指标。
RS简要定义
RS以用户建模(ratings, preferences, demographics, situational context)以及物品(带有或不带有物品特征描述)作为输入, 输出有:
- Good items:“最合适”的一批候选物品,如 Top-N 推荐列表
- Relevance score:给每个候选物品打一个“相关性分数”或“预测评分”
- Ranking:按照相关性分数对所有物品进行排序,最上面的就是最优推荐
- User interests:从用户历史行为中抽象出的兴趣画像(兴趣主题分布、潜在因子向量等),用于辅助长期建模或解释推荐结果
RS与信息检索有区别
信息检索IR:用户知道需求,目标是快速找到正确的信息 而RS来说,用户不一定明确需求,系统想要推荐一些可能用户感兴趣的午评,通过常委发现意外但相关的东西。
推荐系统类别
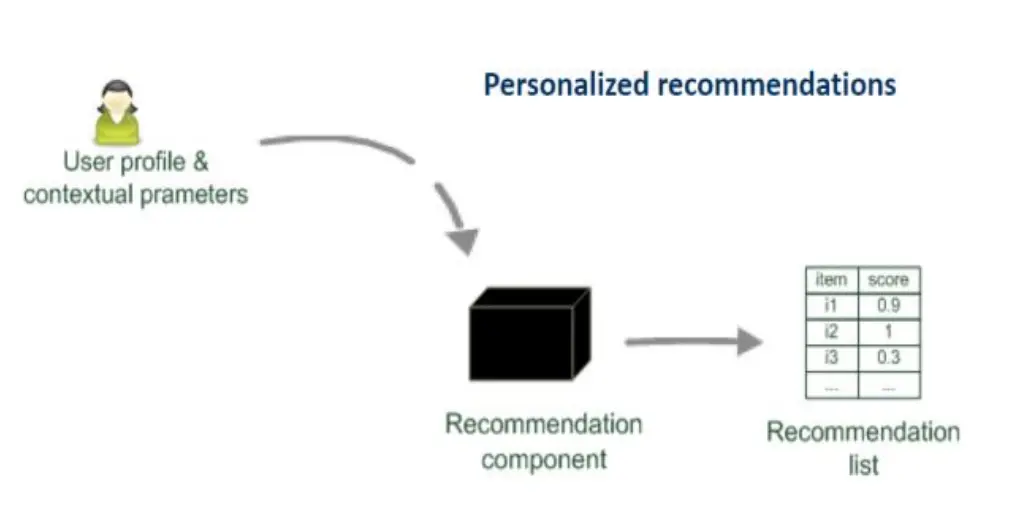
- Personalized recommendations
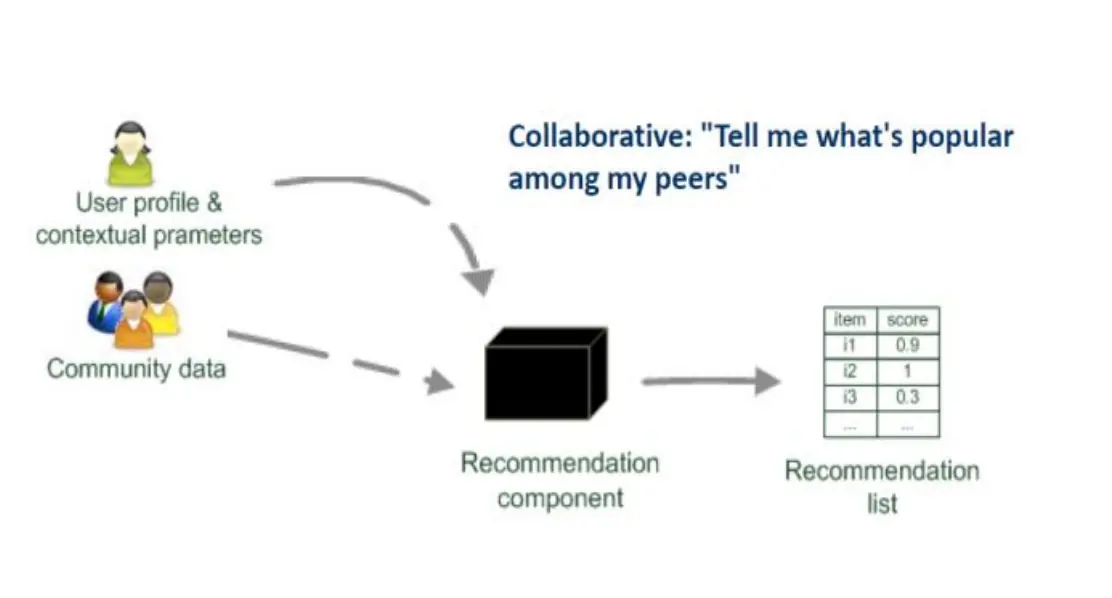
- 协同过滤 (Collaborative): 我的同僚喜欢什么
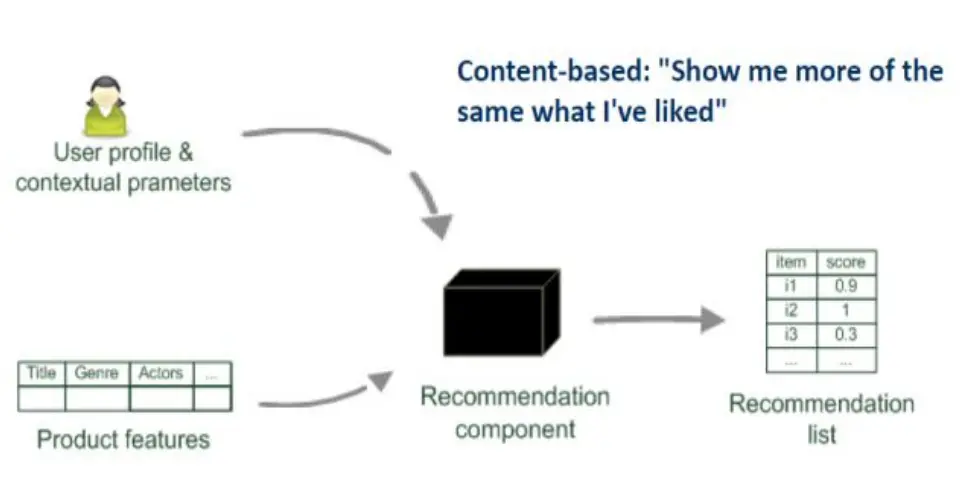
- 基于内容:根据我以前看过的,推荐一些我可能感兴趣的
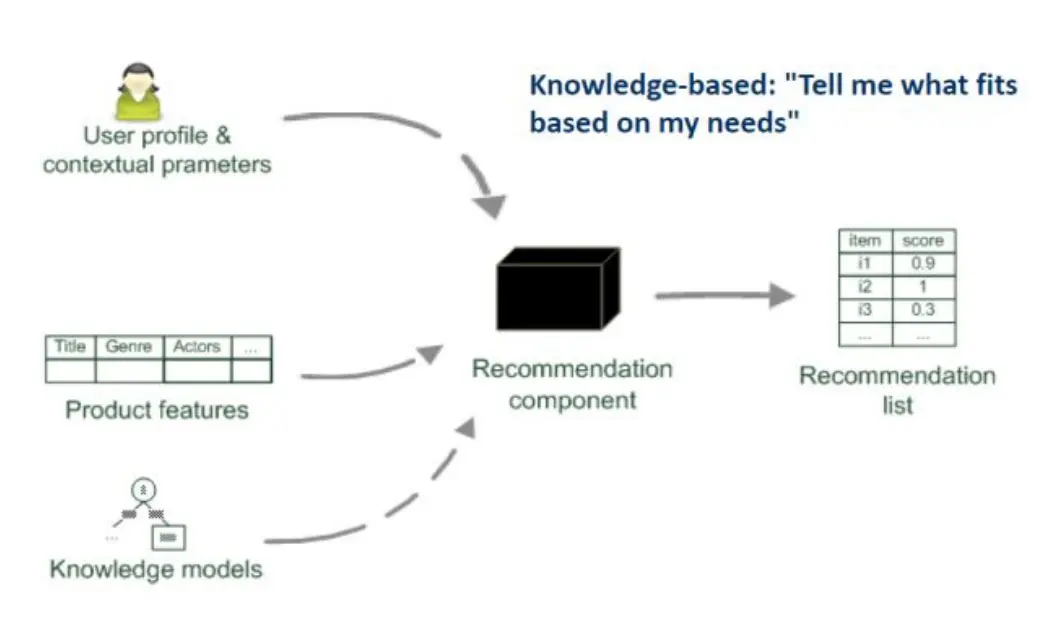
- 知识驱动:根据我的需求,推荐一些内容
- 混合型:上面的都拿过来,都考虑
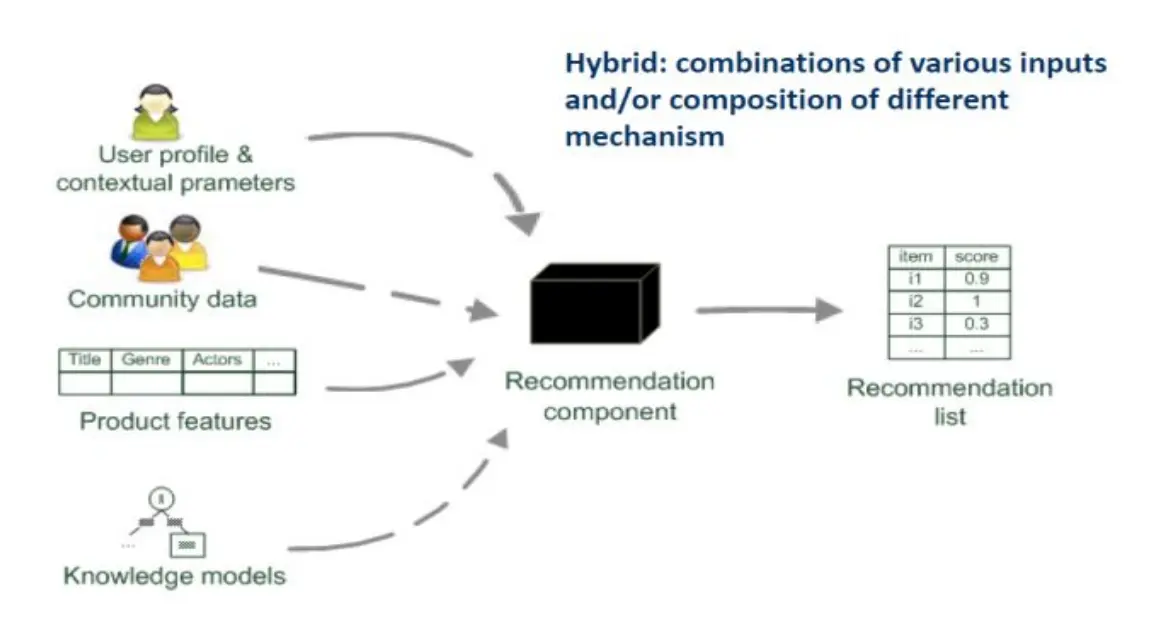
Collaborative Filtering 协同过滤
输入:用户-物品评分矩阵 输出:(数值)预测,指示当前用户对某个特定项目的喜好程度,以及一个Top-N推荐表
一般有两种CF:
- User-based CF
- 计算用户相似度,根据其他用户的评分预测该用户对新物品的评分
- Item-based CF
- 根据用户过往的高分评价物品计算相似度,推荐新物品
User-based CF
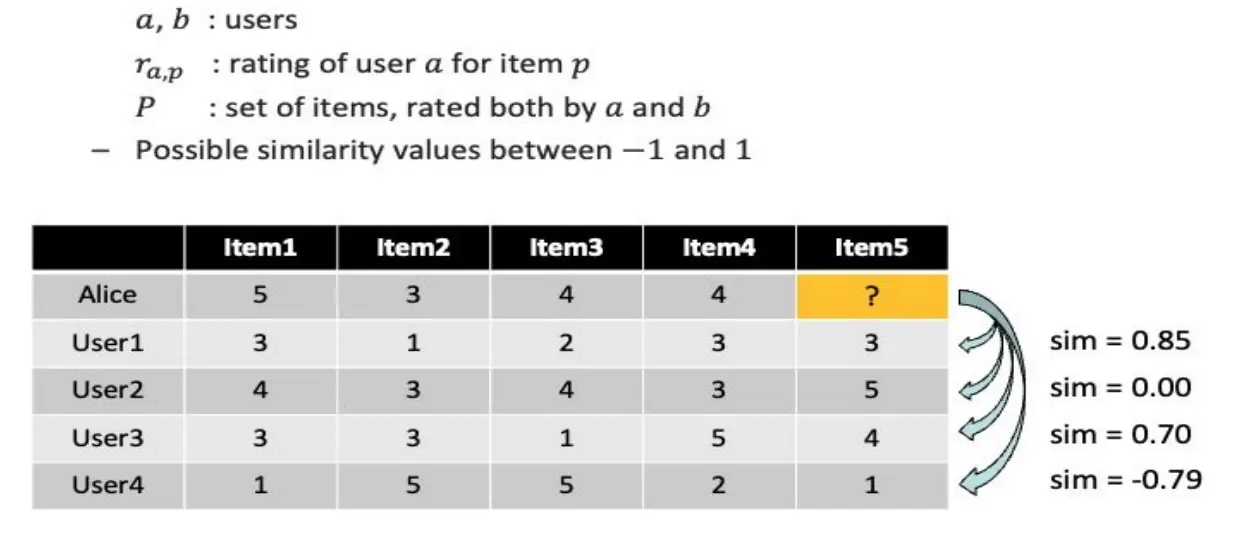
最basic的idea:想要知道A对一个没见过东西的评分,就去找他已经对这个东西打过分的相似的伙伴,然后平均他们的评分。
- 如何计算相似性?
- Pearson correlation
- a,b是用户,r_(a,p)是a对物品p的评分,P是物品集,那么相似度被定义为:
- Pearson correlation
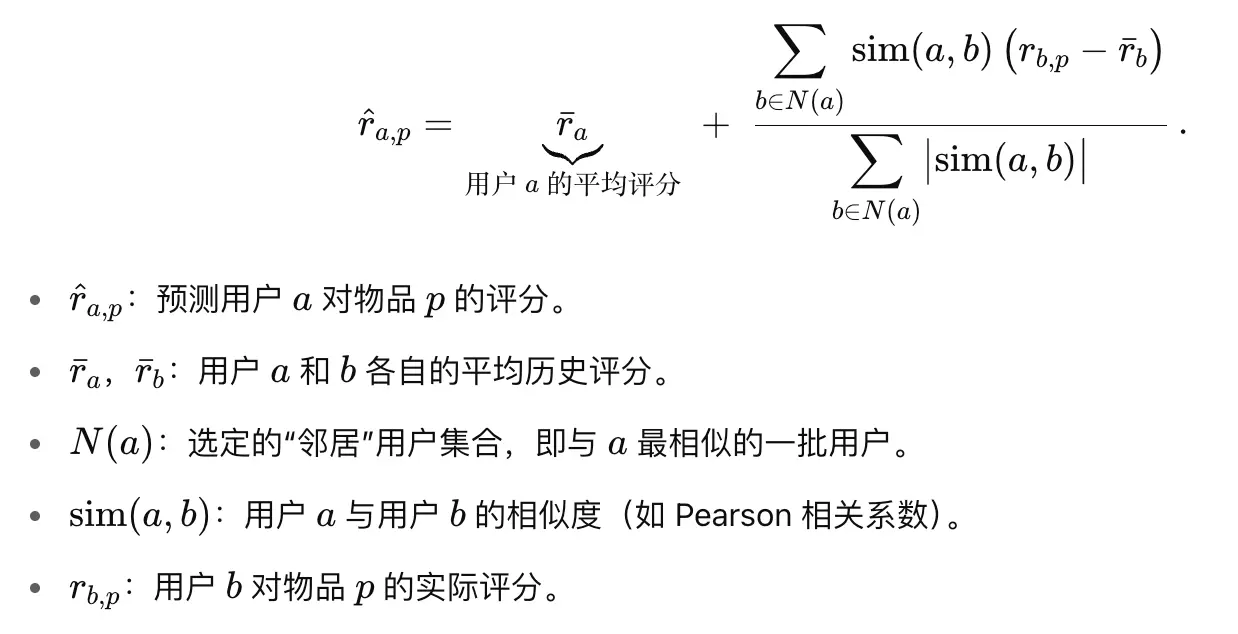
- 如何预测?
- 先做去中心化,只去计算超出平均的部分。相当于是相似度对偏差的加权
Item-based CF
最basic的idea:使用物品的相似度来预测。
- 如何计算相似度?使用Adjusted Cosine Similarity
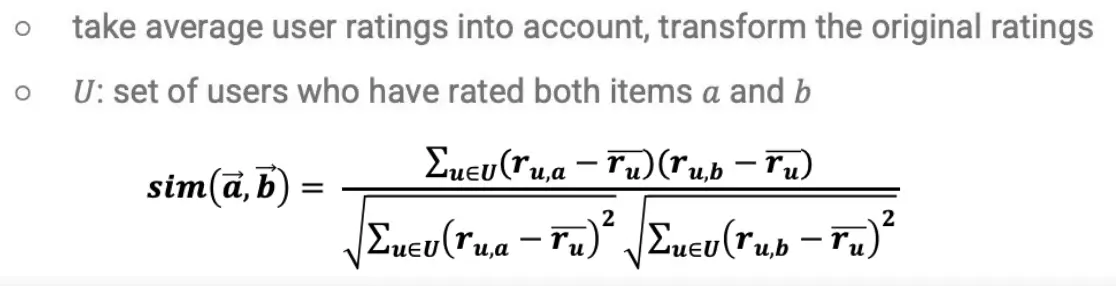
- 如何做预测?

两个的预测方法都是一样的,只不过计算sim的方法不一样。 对于User-based CF,计算人与人之间的相似度,然后以不同人的分数对相似度加权算出新物品的分数。 对于Item-based CF,计算物品之间的相似度,然后以不同物品的相似度对他们自己的分数加权得到新物品的分数。
评分怎么来?
协同过滤依赖于用户的评分。评分可以分为两种: 显式评分:5星评分,喜欢/不喜欢等。 问题:用户懒得评分,如何刺激用户评分等。 隐式评分:点击率,购买率,观看时长等。简单收集,但无法准确解释用户的行为。 还有一些别的问题:
- 冷启动问题
- 数据稀疏性:用户只和项目的一小部分进行了交互
- 可扩展性:item或people数量增加,计算成本昂贵
- 流行度偏差:更频繁地推荐热门项目
- 人口统计偏差:偏向于成年,年轻人。
Content-based recommendation 基于内容推荐
虽然协同过滤这个方法只需要利用物品的评分,而不需要物品本身的属性是一个优点,但其实如果能够将一些物品的特性利用起来,比如说一本书的类型、关键词、作者风格等,那肯定更好。 比如,对之前更喜欢科幻小说的人推荐科幻小说。大多数的基于内容推荐技术都被用于推荐文本文档。任何需要被推荐的物品都可以表示为某种文本:
- 可以是结构化的描述,比如说(genre、keywords、actors、product features…)
- 可以是没有结构化的描述,比如一段评论。
所以,我们需要干两件事:
- 物品“内容”信息:每个物品的一组属性(genre、keywords、actors、product features…),通常抽象成特征向量。
- 用户“偏好”模型:根据用户历史看过或打高分的物品,构造一个用户偏好向量(可以是这些物品特征的加权平均)。
对于结构化描述
如果物品和用户已经被结构化描述了: 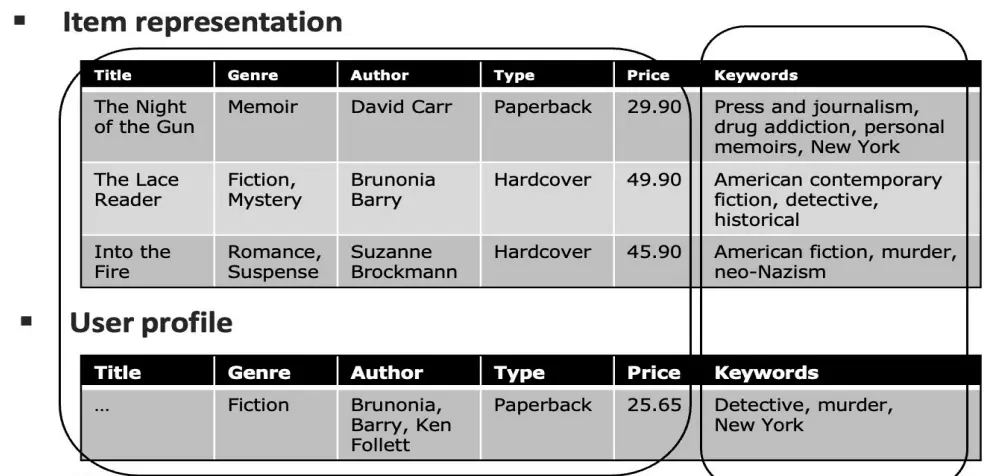 那么计算相似度的方法就是Dice 系数
那么计算相似度的方法就是Dice 系数
然后呈现Top-N就行了。
对于非结构化描述
简单的结构化表达有一些问题:
- 不是每个词都有着相同的重要性
- 更长的文本其实有着更大的可能与用户profile进行重合
所以,我们用TF-IDF方法。它把每个词在文档中的重要程度建模为一个实数权重,从而解决上述问题 首先计算TF(Term Frequency):
然后计算IDF(Inverse Document Frequency): 其中 𝑁 是所有文档总数, 𝑛 ( 𝑖 ) 是包含词 𝑖 的文档数。
IDF衡量了词的稀有度。
最终TF-IDF定义为:
用这个东西再和用户画像再去计算sim。用户画像怎么算?一个可能的做法是把用户看过的内容的TF-IDF进行加权平均。另一个可能的做法是用户自己写一段内容,然后进行TF-IDF表达。
TF: 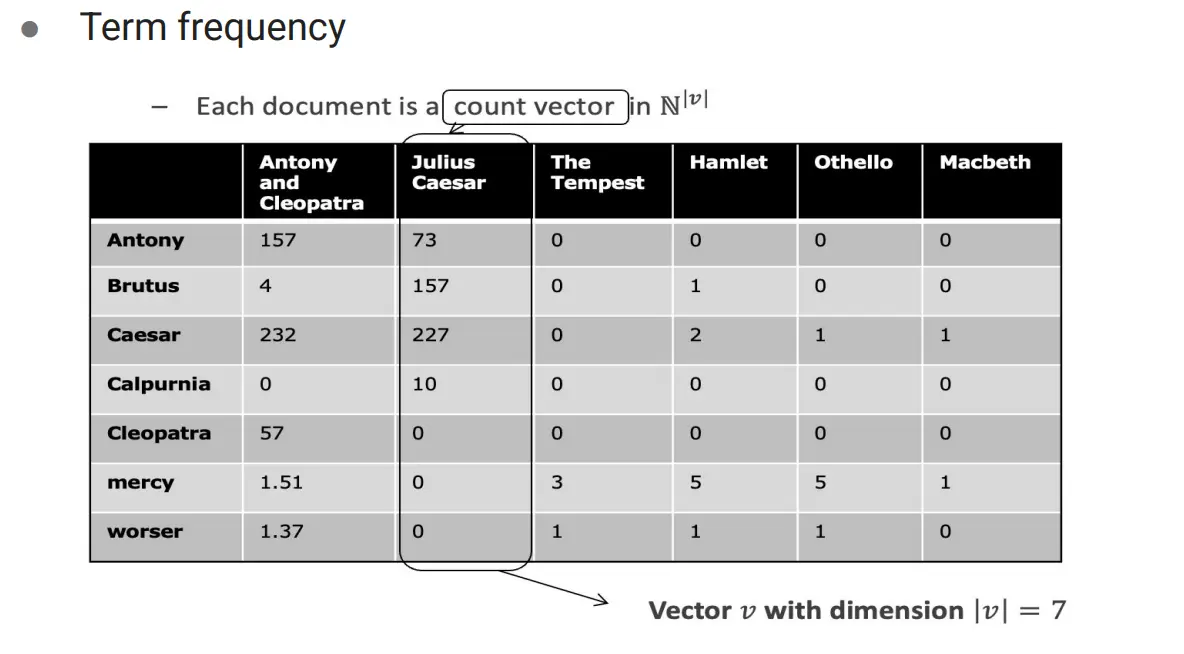 TF-IDF:
TF-IDF: 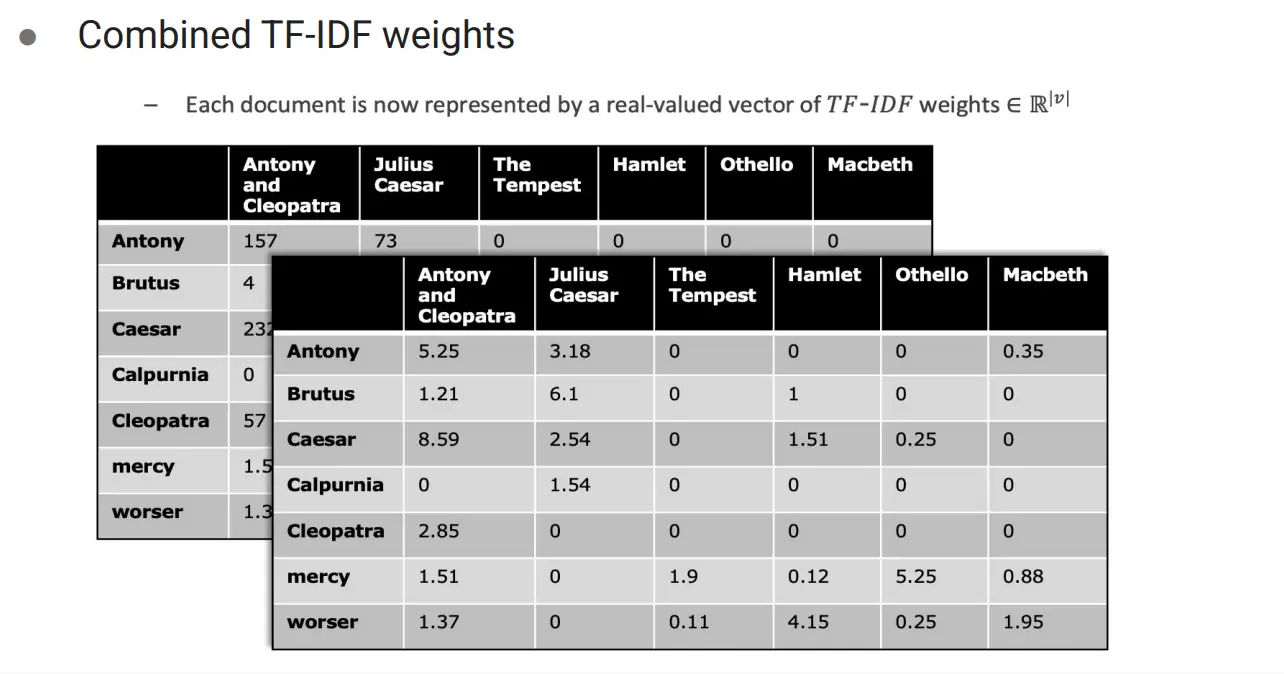
改善TF-IDF的向量空间
可以看到,TF-IDF的向量一般都很长,而且比较稀疏。我们要采取一些手段:
- Stemming(词干提取):把同根但形态不同的词(going、goes、gone)都归到它们的词干(go)上
- Size cut-offs(特征截断):只保留最具代表性的前 N 个高权重词(比如 top-100),把低频或与主题无关的“长尾”词丢掉
- 利用词汇知识:借助领域词典或人工规则,剔除在当前任务/领域中无关紧要的词,比如金融文本里删掉 “movie” 之类无意义项。
- 短语检测:自动把“United Nations”、“New York”当作一个整体特征
另外,目前是有一些局限性的,无法利用语义。 比如,如果一个肉食餐厅的评论中大量出现:没有vegetarian喜欢的菜,那么不断出现的vegetarian可能会导致这个餐厅被推荐给素食主义者。
- 我们可能需要引入BERT或者规则系统来补足
轻量级方法-基于最近邻的CB RS
把用户看过并已经标记喜欢/不喜欢的那一小批文档D当作已知兴趣集。 对于一个还未见过且待推荐的文档i:
- 计算它与D中每个文档的内容相似度(cos相似,TF-IDF距离等)
- 找出与i最相近的k个邻居文档
- 算喜欢占比
优点:简单直观,非常适合短期兴趣捕捉。 缺点:k太小容易过拟合。太大容易混入冷门噪音
轻量级方法-基于概率分类的方法
将每个候选文档视为一个待分类对象,根据它的内容特征判断它是“hot”(用户会喜欢)还是“cold”(用户不会喜欢)。 使用二分表示: 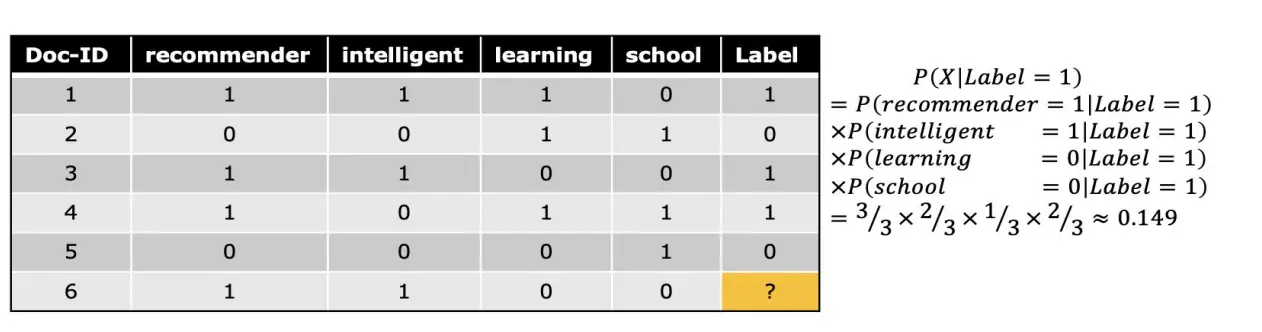 优点是简单,缺点是朴素独立性假设往往不成立(关键词之间高度相关)。
优点是简单,缺点是朴素独立性假设往往不成立(关键词之间高度相关)。
轻量级方法-基于线性分类器
就是还是用TF-IDF对内容建模,然后使用线性分类器或者别的分类器去分类。
轻量级方法-基于决策树
使用规则归纳和决策树来判断用户是否喜欢。 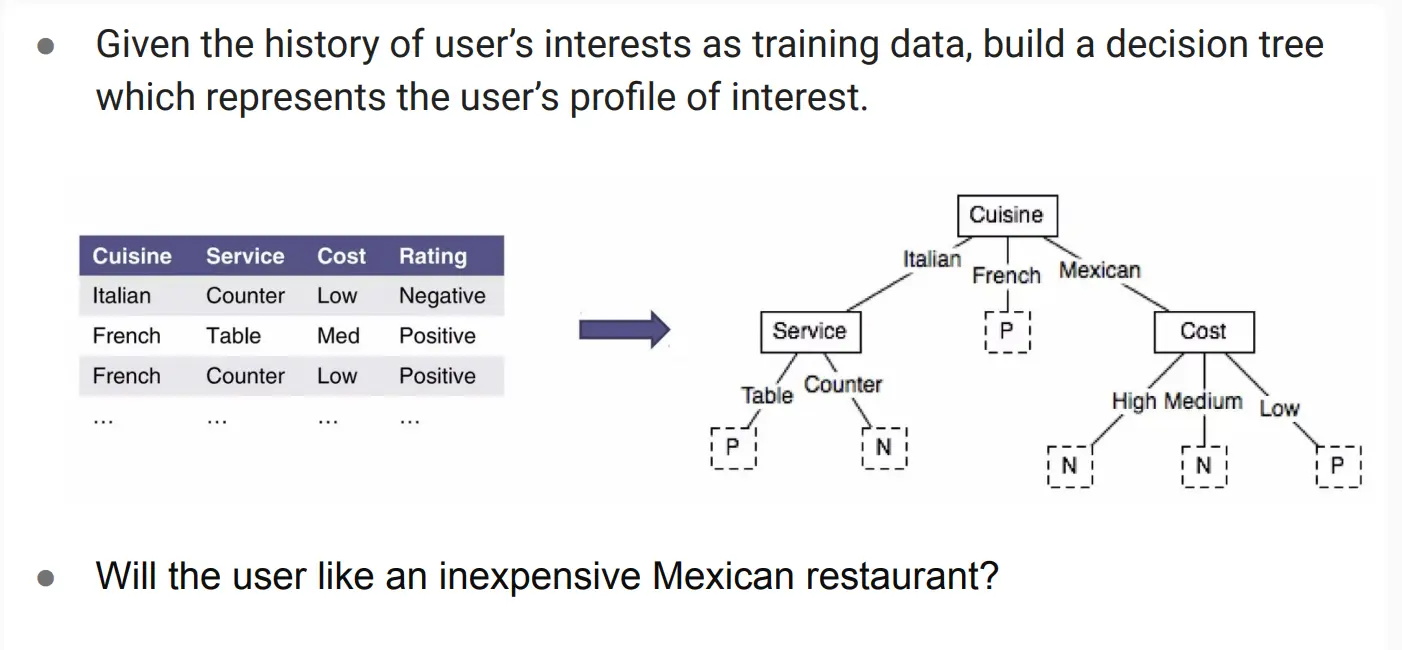 优点:可解释性强,可以融合专家知识,然而,如果面对非结构化数据,比如面对TF–IDF 的上万维词向量,可能就会导致树的深度爆炸。 我们一般用用元特征替代原始文本,在文本场景下,先抽取“meta features”——比如作者(Author)、流派(Genre)、出版年份等,再做规则归纳,如用RIPPER算法。
优点:可解释性强,可以融合专家知识,然而,如果面对非结构化数据,比如面对TF–IDF 的上万维词向量,可能就会导致树的深度爆炸。 我们一般用用元特征替代原始文本,在文本场景下,先抽取“meta features”——比如作者(Author)、流派(Genre)、出版年份等,再做规则归纳,如用RIPPER算法。
Content-based 推荐系统劣势
- 仅靠关键词不够全面,质量 ,很多页面只有几句话,关键词极少,难以准确刻画主题;多媒体(图片、视频、音频)中的信息无法自动提取到关键词向量里。 相关性难以度量,
- 冷启动问题
- 过度专一(Overspecialization)算法倾向不断推荐与用户已喜欢内容高度相似的项目,缺少惊喜;难以引入跨领域或长尾内容。
目前推荐系统的趋势
- 个性化,结合用户的实时偏好、长期画像,提供高度定制化的推荐。
- 可解释 AI
- 上下文感知推荐(Context-Aware Recommendations):将 时间(早中晚)、地点(室内/室外、城市/乡村)、社交环境(与你好友的互动)等上下文信息纳入模型,使推荐在不同场景下更贴切。
- 多方利益相关者推荐:除了关注用户,还要兼顾内容创作者和平台方的需求——平衡用户满意度、作者曝光度与平台盈利。
- 伦理与隐私
研究方向:
- 强化学习在推荐中的应用
- 长期用户建模
- 混合推荐系统
- 新型推荐范式
- 公平性与偏见
 Larry Shi
Larry Shi