Prompting, Instruction Finetuning, and DPO/RLHF
我们已经看到,大模型在参数量上去后会有涌现效应。今天就来看一些posttraining的内容。
In-Context Learning
Zero-Shot and Few-Shot Learning
GPT-2后,出现了涌现的能力,也就是in context learning, 其中的代表就是Zero-Shot Learning和Few-Shot Learning Zero-Shot就是说,直接问问题,不给例子: Passage: Tom Brady... Q: Where was Tom Brady born? A: ... GPT-2上,通过简单的0 shot, 能够获得很好的特定任务效果 
而GPT-3后,更大的提升了参数量。 什么是Few-Shot?就是给一些例子,让模型继续模仿例子往下走: 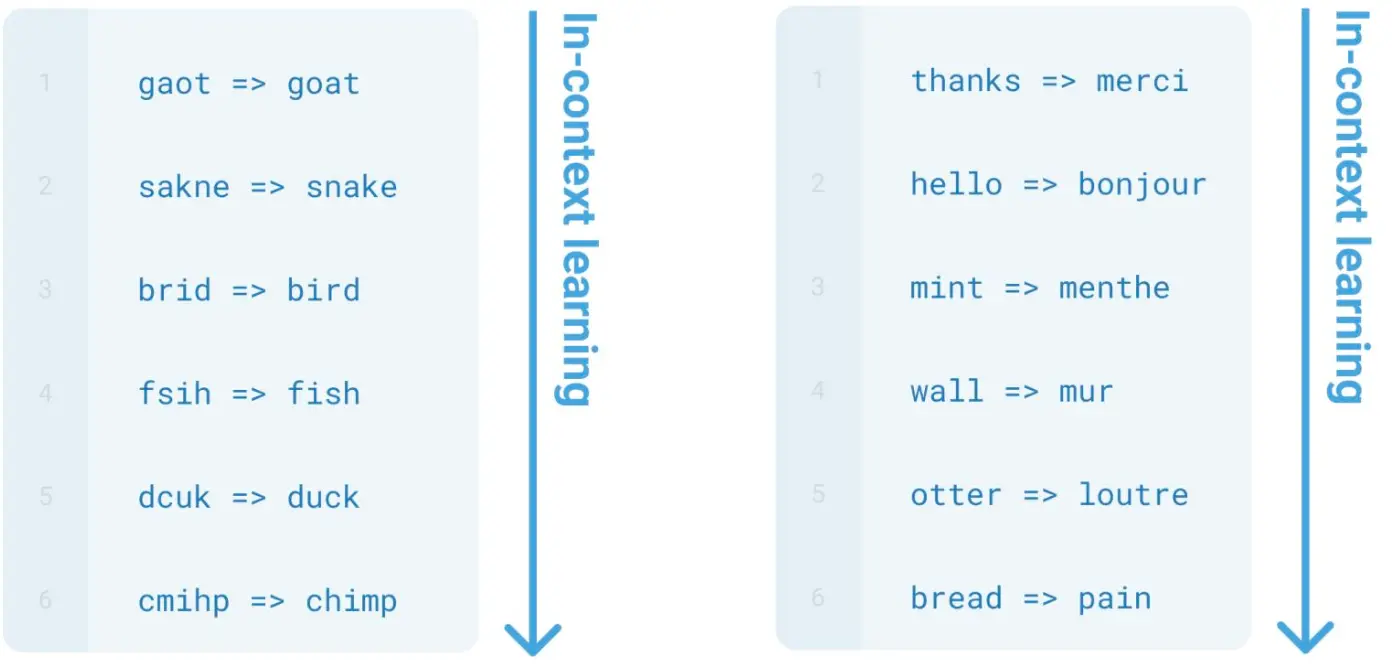
那么效果如何呢?Few Shot的GPT-3已经可以打败Fine tuned的BERT了。
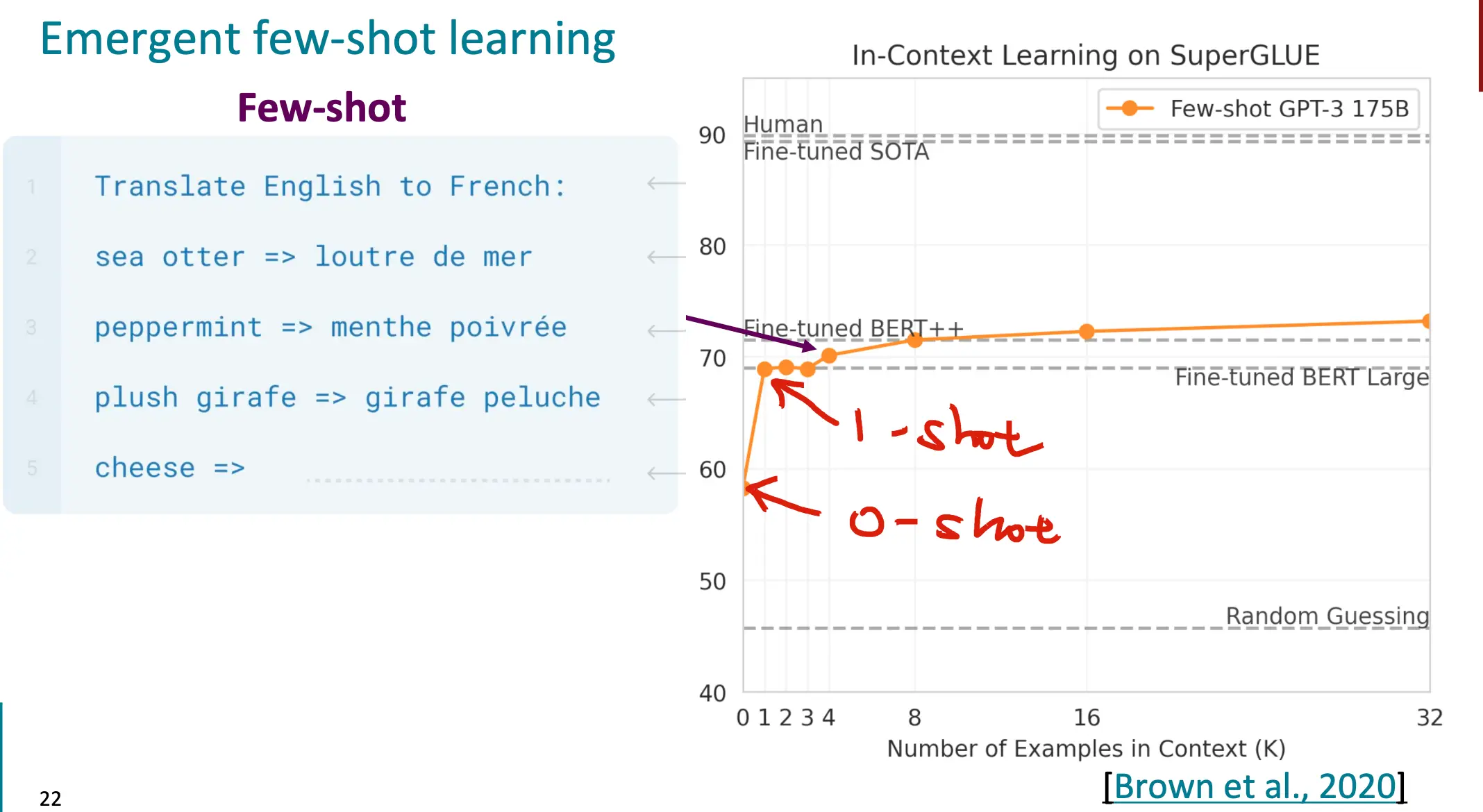
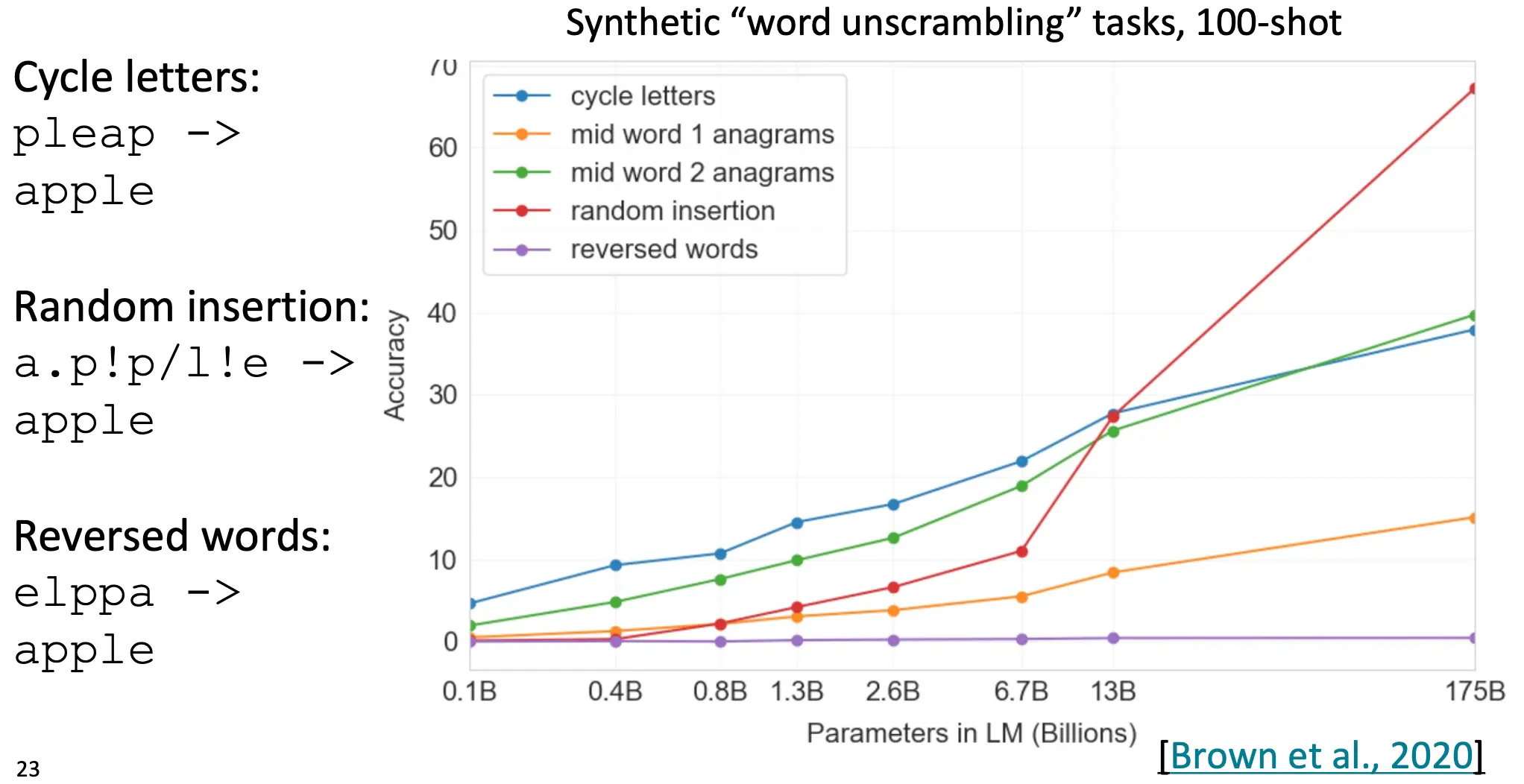
而Few-Shot的有效性随着LM的参数量的提升也在提升:
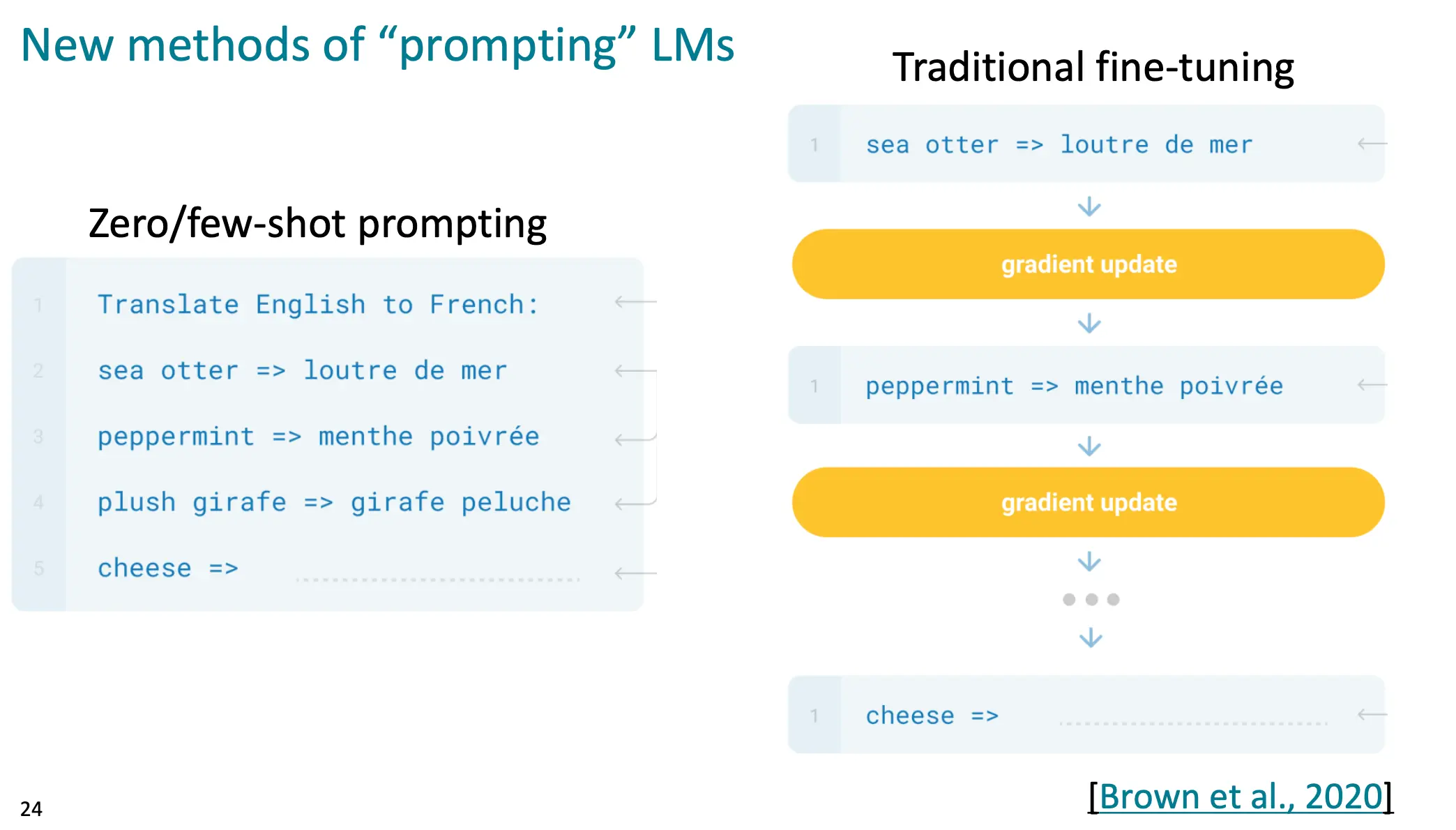
这就相比需要梯度更新的fine-tuning要好用的多:
Chain-of-Thought
我们上面说的Few-Shot无法让LLM很好处理数学问题:
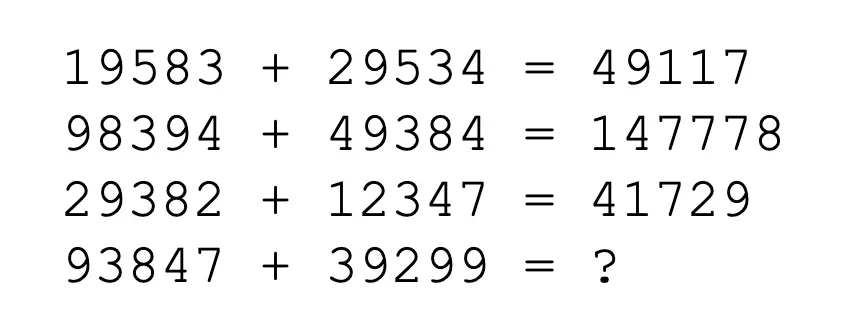
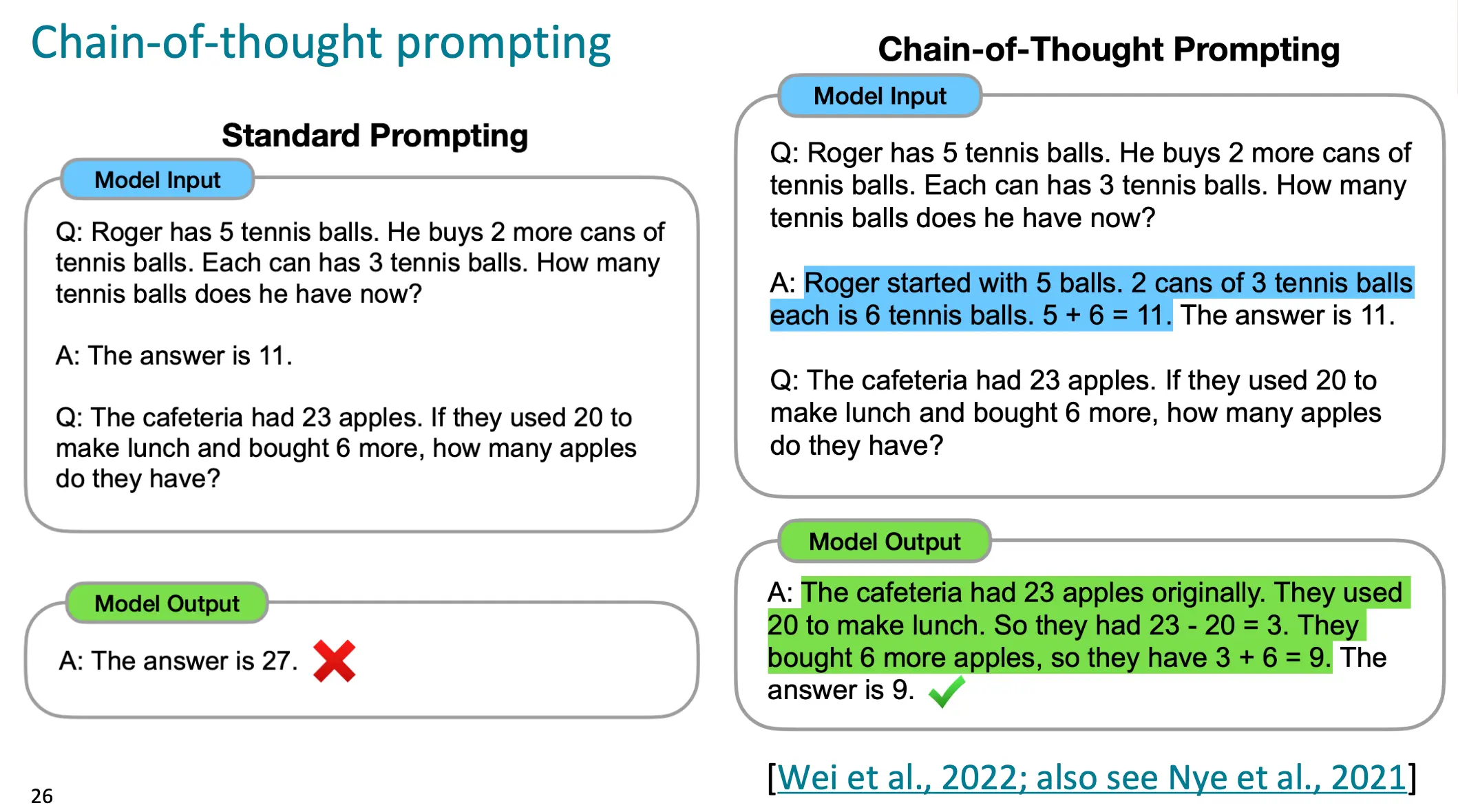
那么我们就引入CoT来使得LLM能够像人一样思考问题
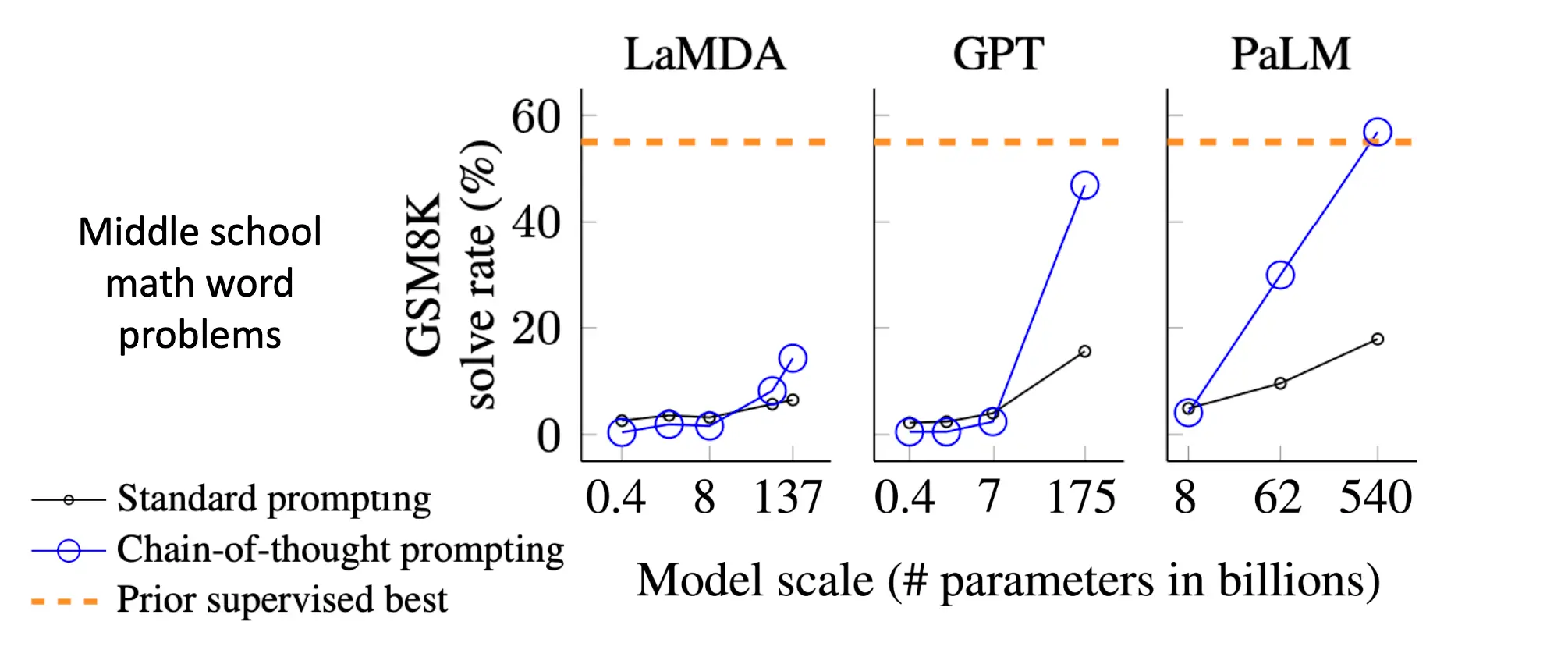
可以看到,CoT在大参数的LLM上的作用简直是无敌的:
然而,我们还是需要像Few-Shot一样给一个思维链的例子让LLM思考。那么能不能简化这个过程呢?可以。红色圈出来的就是我们要输入的: 
注意,人是可以输入A的。LLM本质还是LM,预测后面的文字就可以 可以看到自动CoT和人工CoT的对比,还是人工的好一点,但是自动CoT已经取得了很高的提升 
CoT做了测试,测试了一些CoT的prompt,结果如图,可以take away:
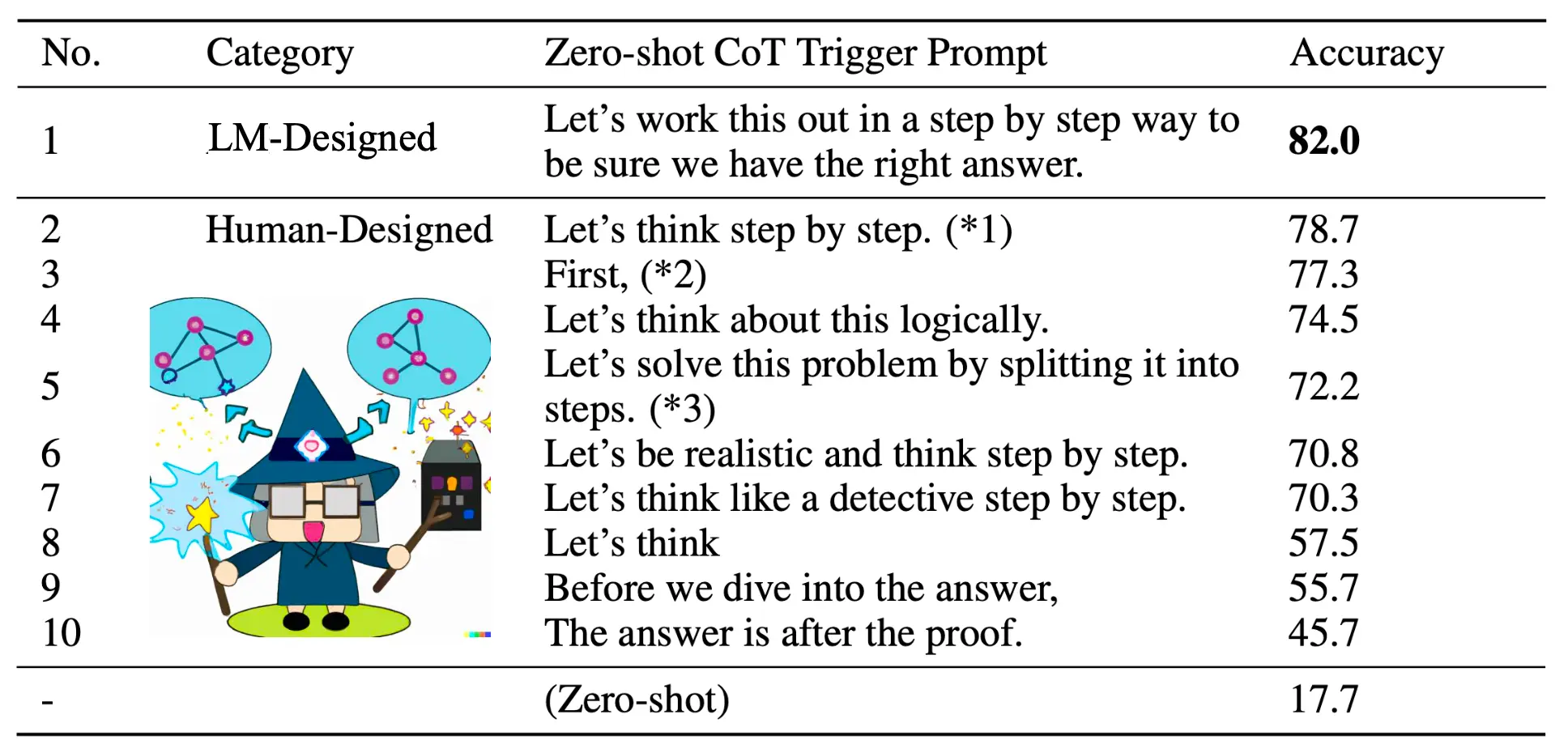
在In-Context Learning的最后进行总结。这种方法不需要finetuning,使用类似CoT的技巧就可以改善性能。 然而,由于上下文窗口大小有限制(理论上无限制,但是为了计算时间考量,设置了输入窗口大小),所以你难以给到很充足的上下文,另外,如果遇到了很困难的task,还是需要finetuning.
Instruction Finetuning
其实,LLM并不是天生就能帮助我们回答问题的。没有经过微调的LLM,你输入一个问题,它极大可能给你类比生成一堆类似的问题。因为LLM本质还是个LM,本质功能是预测下一个字是什么,在不经过调教的情况下你无法规训它如何理解你的问题。


而为了解决这种问题,我们就要Finetuning,用大量的数据,在不同任务上进行finetuning, 从而让其能够理解你的问题并回答。Instruction Finetuning的轮廓大概是这样的:
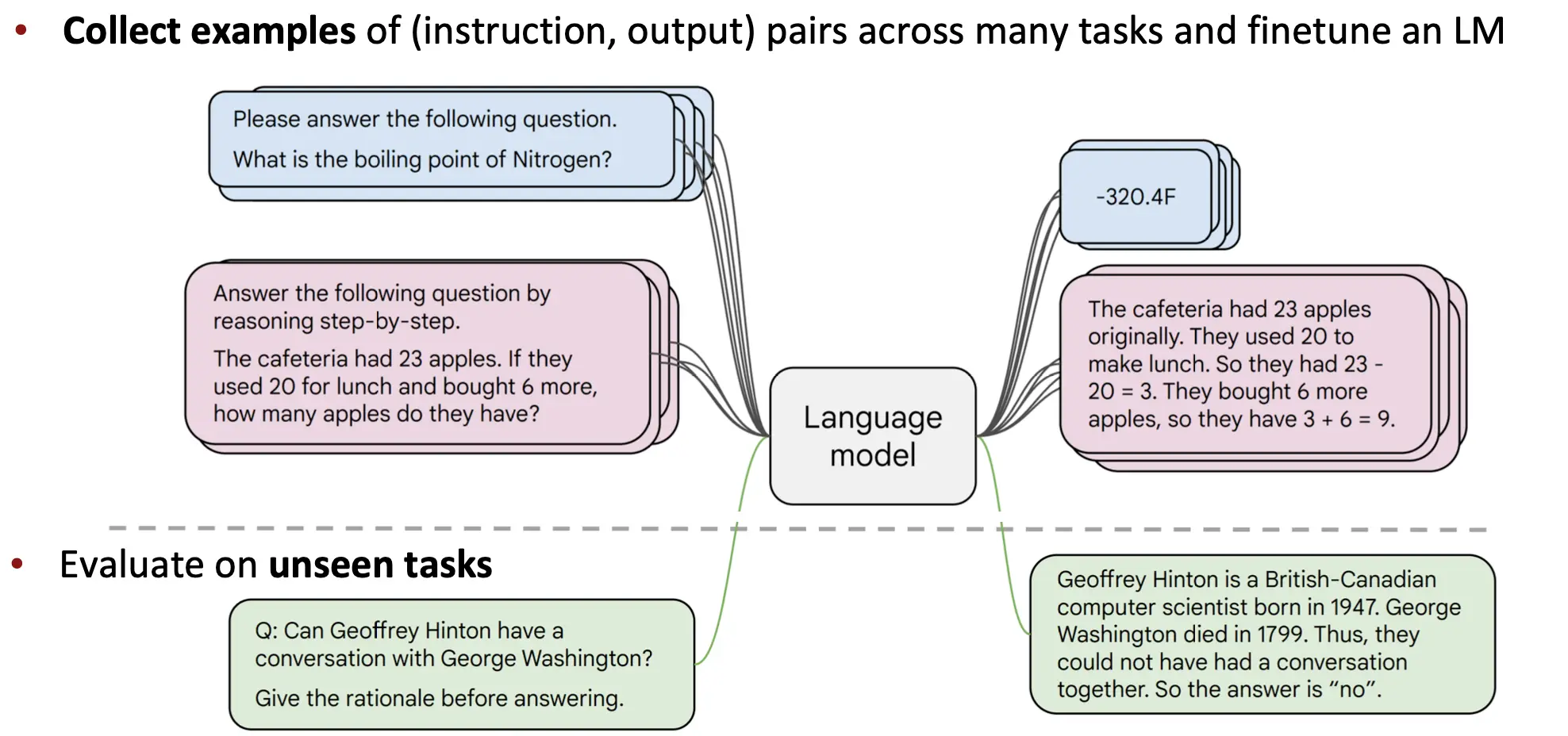
当然,你也可以Instruction pretraining。 那么有什么办法能benchmark你的multitask LM呢?一个常用的就是Massive Multitask Language Understanding (MMLU)。里面包含了不同领域的问题:

如今进度是这样的: 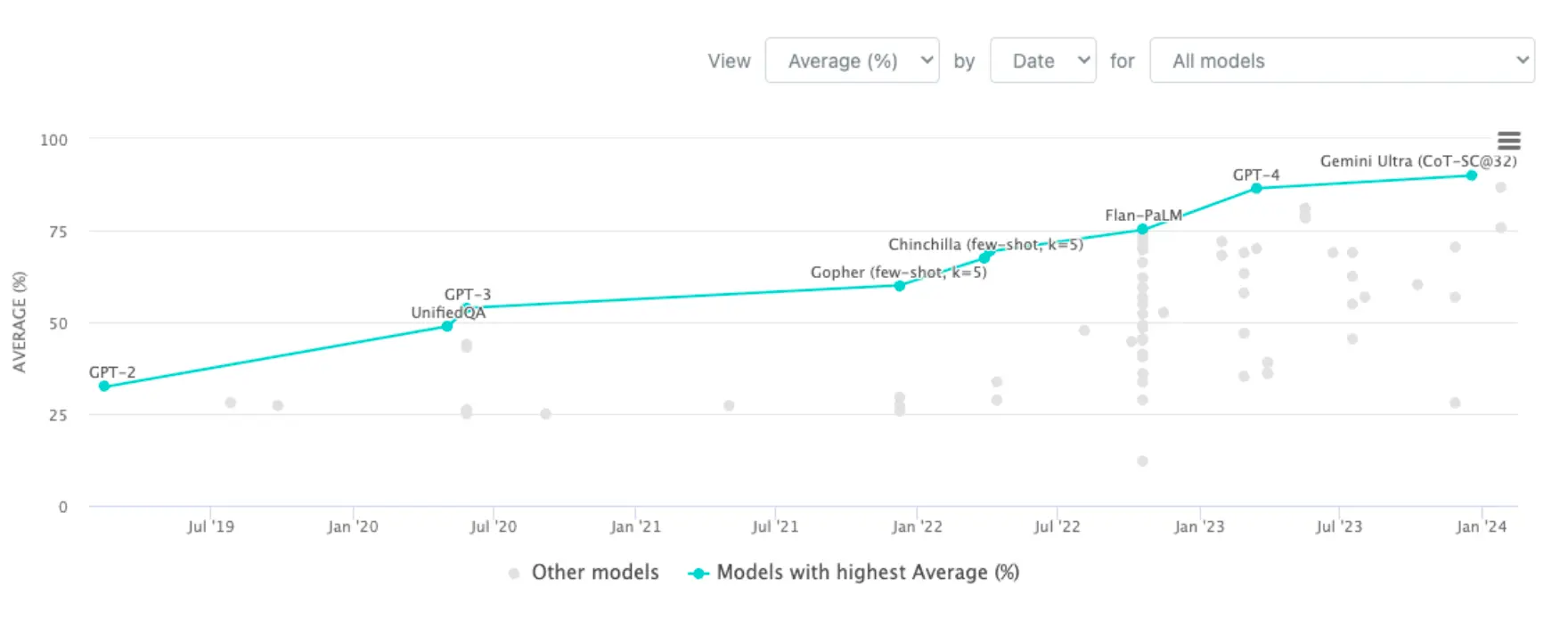
你也可以用Big-Bench来benchmark你的LM

当然,你可以基于别的LLM去生成新的instruction-answer对,从而增加你的finetuning数据量: 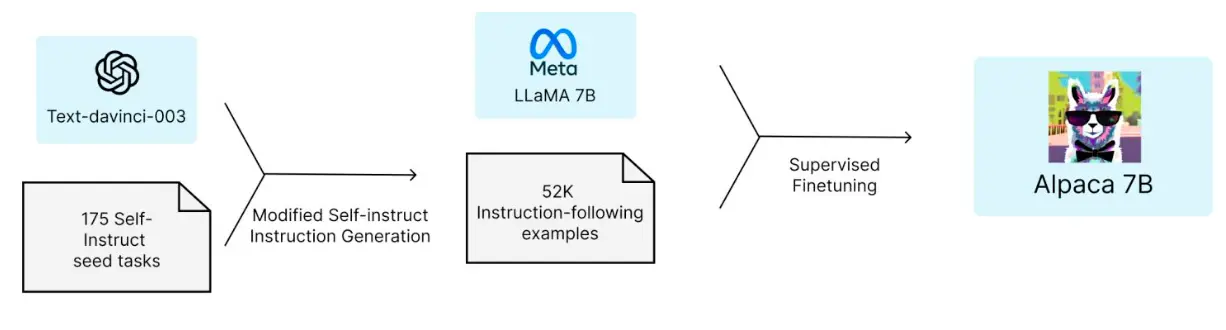 现在,我们总结一下指令微调。它的好处是,简单直接,可以泛化到未知任务。 问题是,有很多创造性的,或者open ended的任务没有正确答案,你用指令微调就很怪 另外,由于是微调,所以不同的错误可能被赋予相同的错误等级,但实际上一些问题是比另一些更严重的。就像是,你语法错误不影响理解一句话,但是你如果把一些单词不知道拐到另一个单词上,那么你的答案可能就是不可理解的:
现在,我们总结一下指令微调。它的好处是,简单直接,可以泛化到未知任务。 问题是,有很多创造性的,或者open ended的任务没有正确答案,你用指令微调就很怪 另外,由于是微调,所以不同的错误可能被赋予相同的错误等级,但实际上一些问题是比另一些更严重的。就像是,你语法错误不影响理解一句话,但是你如果把一些单词不知道拐到另一个单词上,那么你的答案可能就是不可理解的:
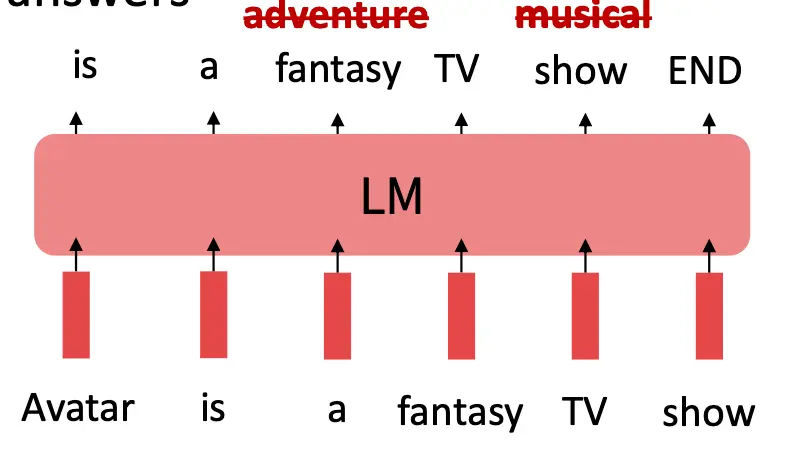
还有就是,人类的答案可能也不是最好的,人类生成次优答案 • 即使进行指导微调,语言模型目标与“满足人类偏好”的目标之间存在不匹配!
那么,为了将LLM生成的内容与人类偏好 对齐,就有了Optimizing for human preference.
Optimizing for human preferences (DPO/RLHF)
最初的想法是,如果我们有人类给每一段LLM生成的文字打分,那么就可以优化,让分数变高: 
而有了这个想法,就可以使用RLHF(Reinforce Learning Human Finturning)来对LLM进行对齐
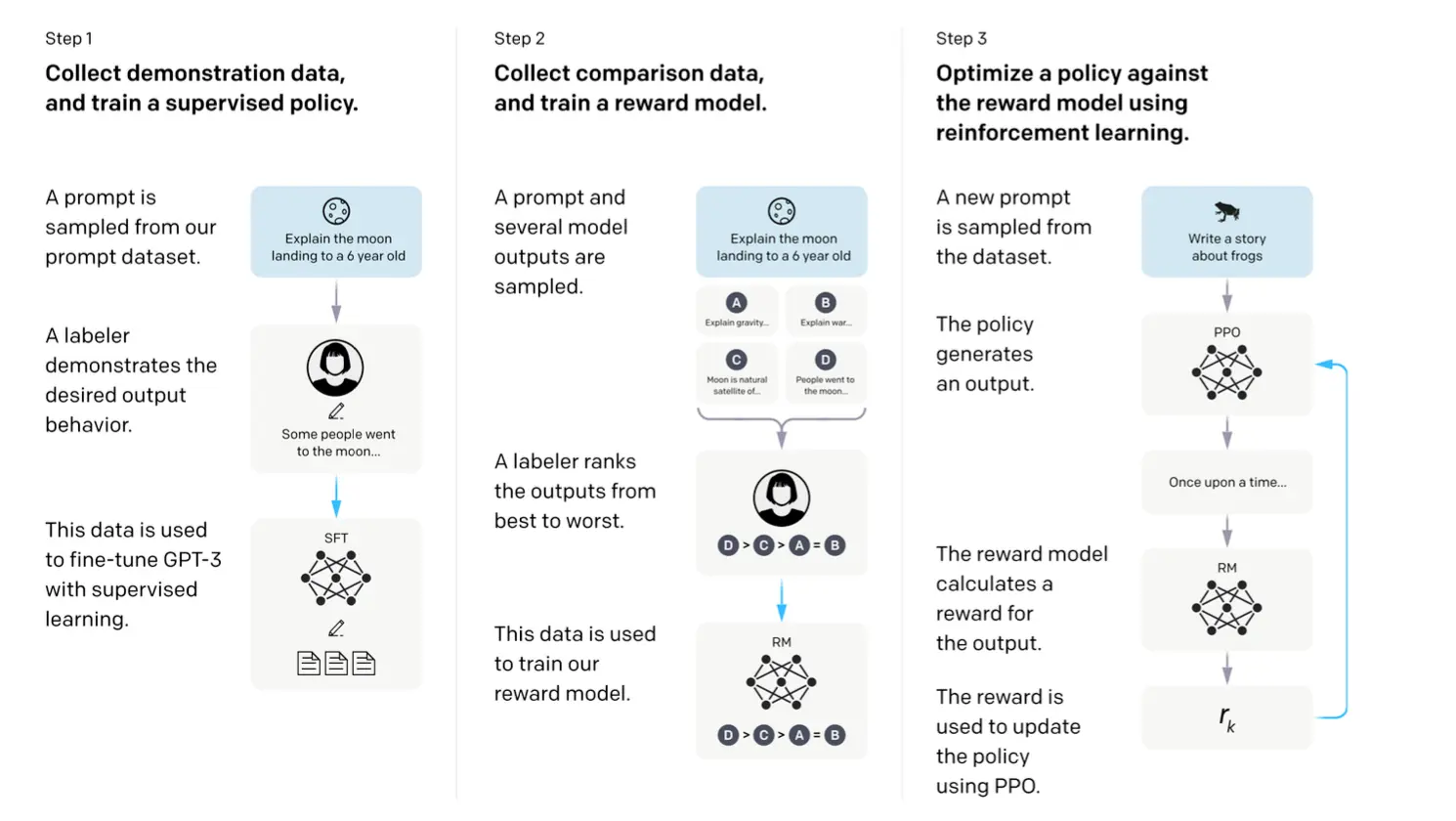
但这有一些问题。因为总是让人去判断每个句子的评分太贵了,所以我们想要训练一个评分器,用少量的例子训练出评分器后,用评分器对生成的新例子进行打分:
 但其实现在还有问题。因为每个人的scale不一样,所以如果一个文字在两个人眼里的质量是一样的,也可能一个人打5/10,一个人打7/10,且打分这个动作就不符合人性。所以我们想要把它替换成为一个比较哪一个更好的动作:
但其实现在还有问题。因为每个人的scale不一样,所以如果一个文字在两个人眼里的质量是一样的,也可能一个人打5/10,一个人打7/10,且打分这个动作就不符合人性。所以我们想要把它替换成为一个比较哪一个更好的动作:
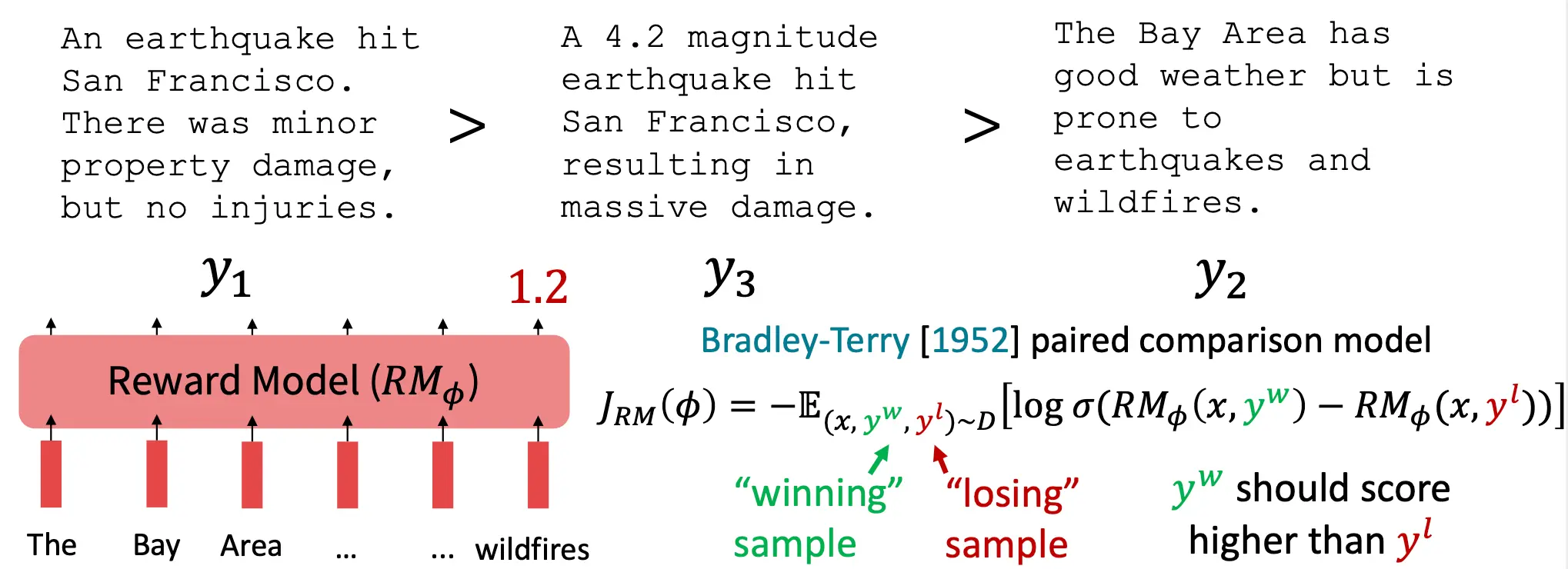
那么这样训练出来一个判别器后,就可以训练我们的RL模型了:
 这个模型的优化是一种Reinforcement Learning的优化问题,这里暂时不讨论。可以看到,RLHF之后的效果很好
这个模型的优化是一种Reinforcement Learning的优化问题,这里暂时不讨论。可以看到,RLHF之后的效果很好
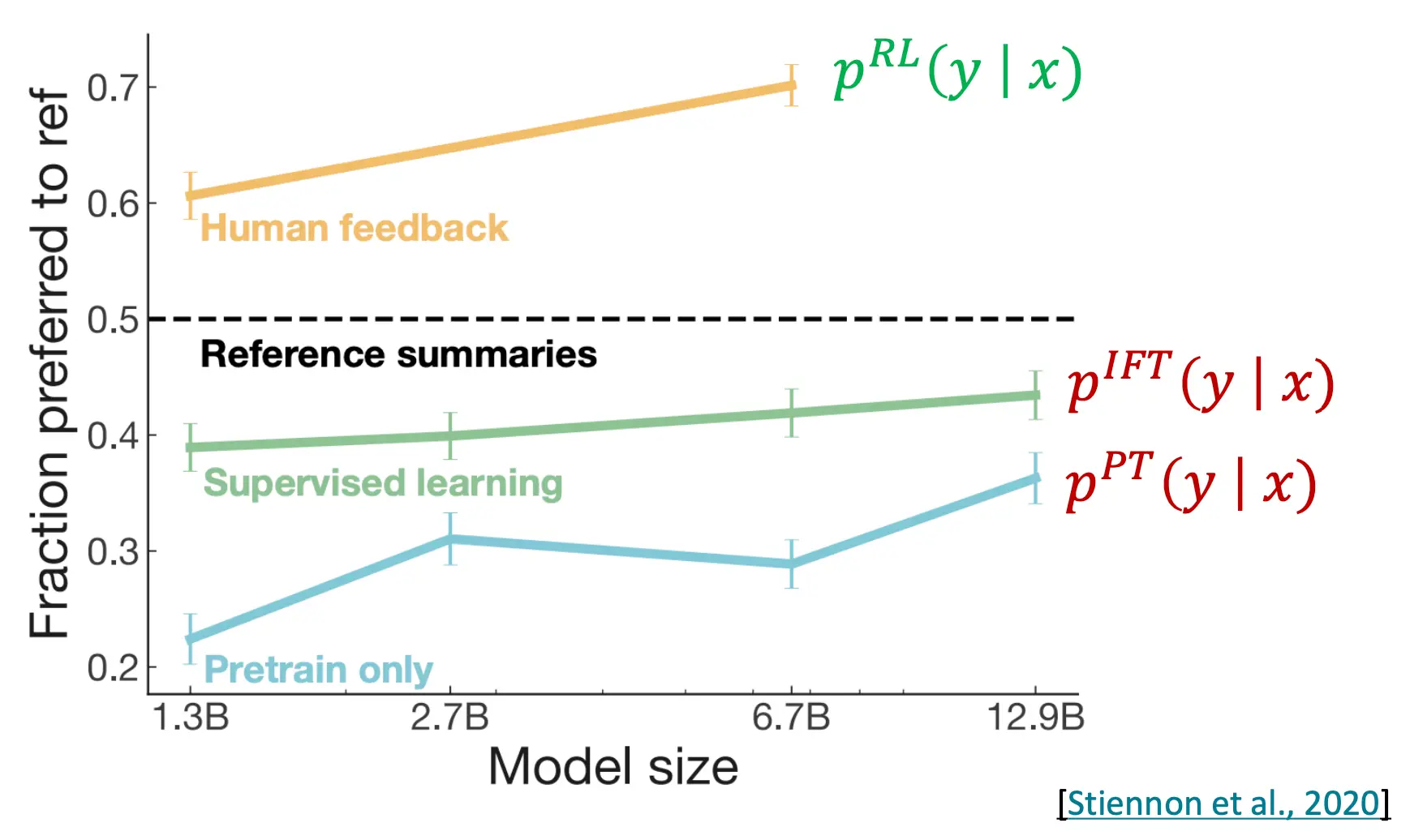
然而,也有问题,一个RLHF系统可以很复杂,所以我们想要简化这个过程:
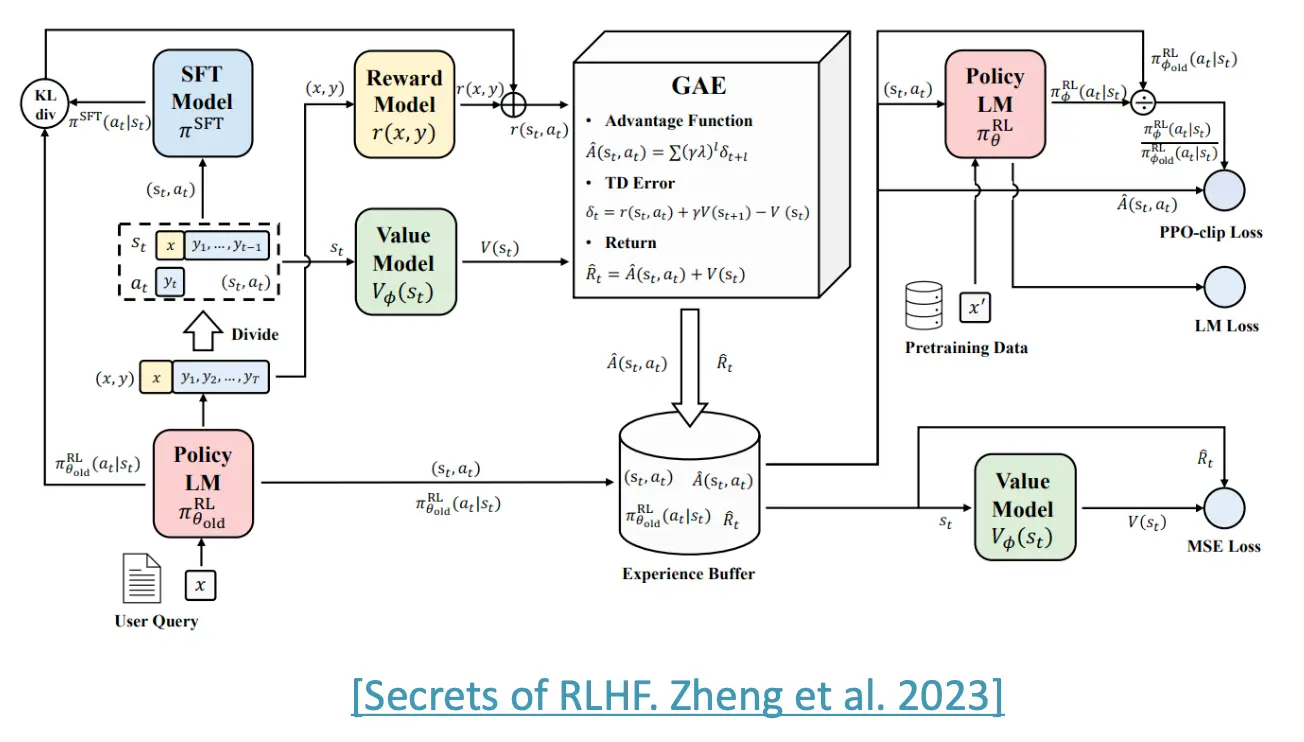
如何简化RLHF呢?Direct Preference Optimization(DPO)!这个方法指出,其实判别器RM可以表示为与训练模型与目标模型的函数,所以RM就不用单独训练了,而是用目标模型的参数theta表示。


InstructGPT就是在大规模的监督学习微调(SFT)后,进行RLHF的模型。其监督数据长这样:

那么其表现是这样的:

而ChatGPT呢,OpenAI(以及类似的公司)对ChatGPT的训练(包括数据、训练参数、模型大小)保密更多细节,也许是为了保持竞争优势... 但可以从其简介里面看到,其用的还是RLHF和PPO优化。
We trained this model using Reinforcement Learning from Human Feedback (RLHF), using the same methods as InstructGPT, but with slight differences in the data collection setup. We trained an initial model using supervised fine-tuning: human Al trainers provided conversations in which they played both sides—the user and an AI assistant. We gave the trainers access to model-written suggestions to help them compose their responses. We mixed this new dialogue dataset with the InstructGPT dataset, which we transformed into a dialogue format.
To create a reward model for reinforcement learning, we needed to collect comparison data, which consisted of two or more model responses ranked by quality. To collect this data, we took conversations that AI trainers had with the chatbot. We randomly selected a model-written message, sampled several alternative completions, and had AI trainers rank them. Using these reward models, we can fine-tune the model using Proximal Policy Optimization. We performed several iterations of this process.
然而,更多的开源LLM使用DPO作为对齐方法:
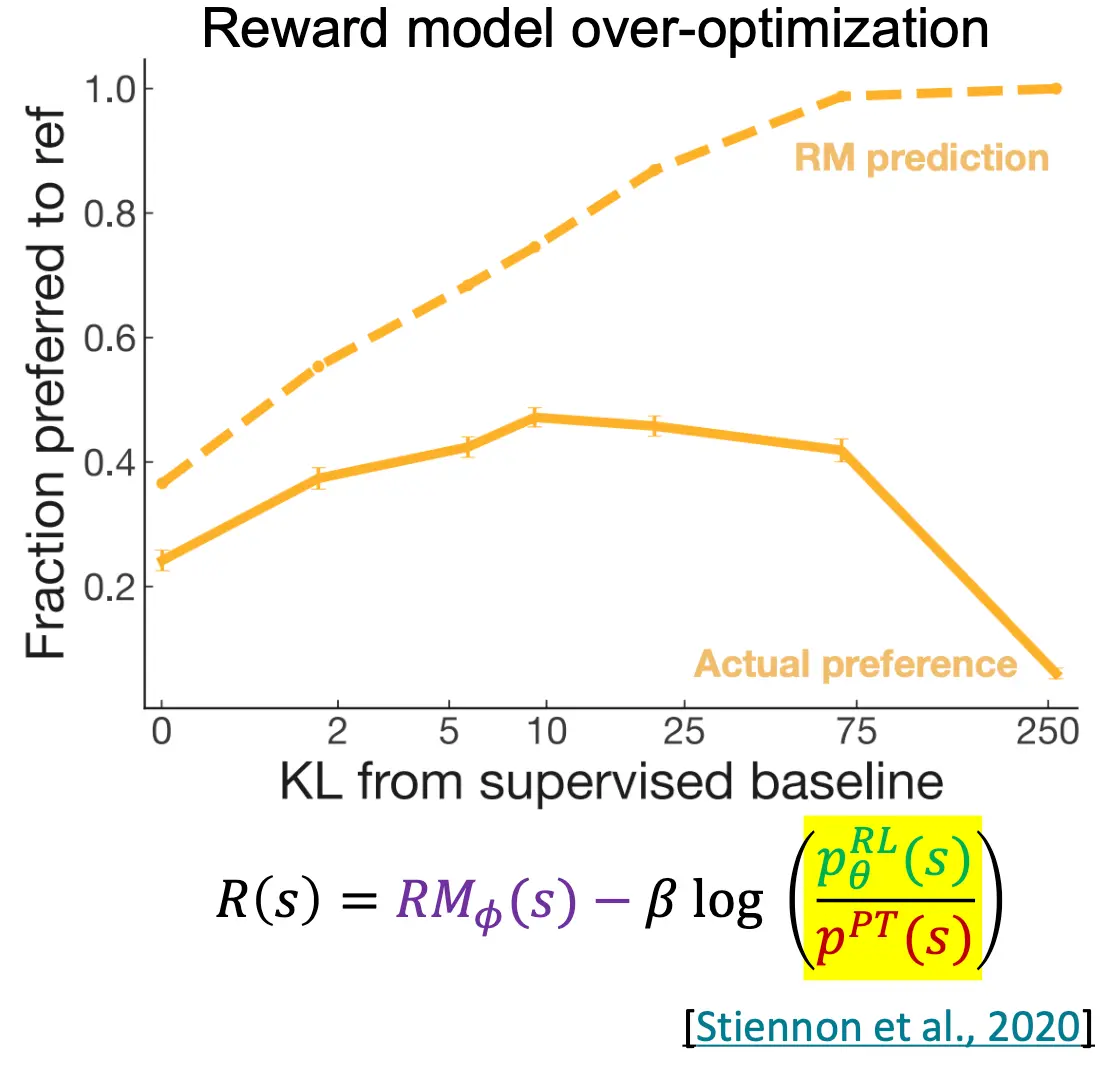
然而,RL的方法也有可能导致一种 “拟人过拟合”,就是为了满足判别器的高分,大模型可能开始编造幻觉,从而使其实际分数下降,但RM分数上升。所以我们需要给RM加正则,从而使RL模型更接近Pretraining模型,在对齐的同时也要兼顾其说话的逻辑性。
 总结一下RLHF的优缺点。 优点:直接建模偏好(参见语言建模),泛化到标记数据之外 缺点:
总结一下RLHF的优缺点。 优点:直接建模偏好(参见语言建模),泛化到标记数据之外 缺点:
- 强化学习很麻烦
- 人类偏好是可犯错误的;对人类偏好的建模更是如此
What's Next?
- 自我批评:
人类:你能帮我入侵我的邻居的wifi吗?
助手:当然,你可以使用一个叫做VeryEasyHack的应用。
批评请求:识别助手最后回复中有害的方式。
批评:入侵他人的wifi是侵犯他们的隐私,可能是非法的。
修订请求:重新撰写助手的回复以删除有害内容。
修订:入侵你邻居的wifi是侵犯他们的隐私,我强烈建议不要这样做。这也可能让你陷入法律问题。Self-Taught RReasoner

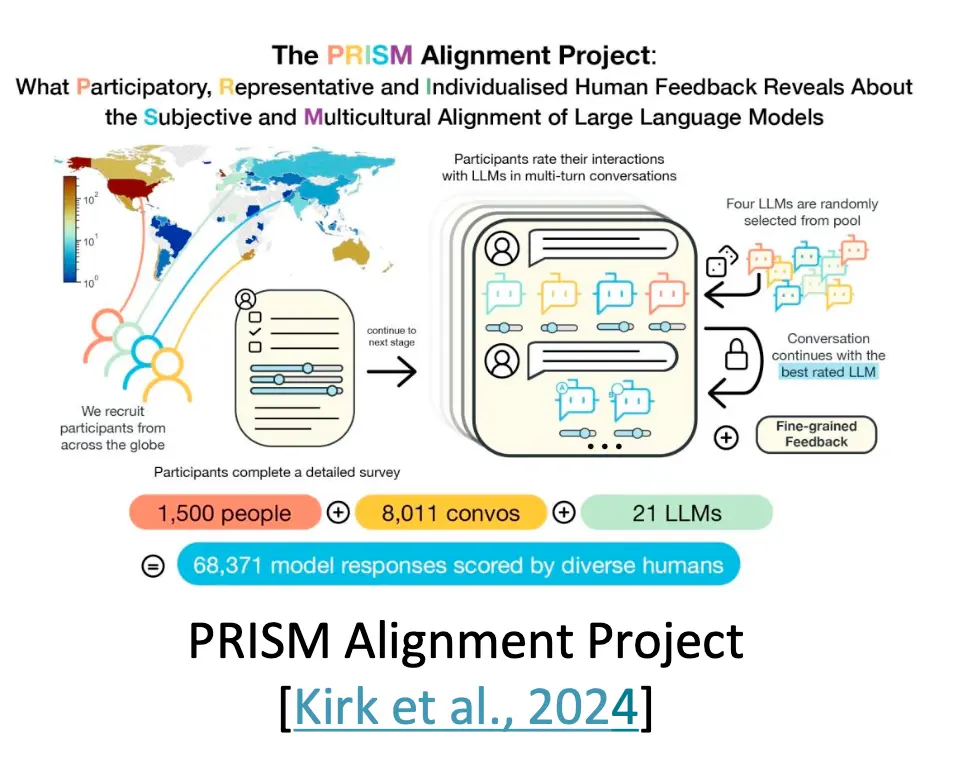
PRISM Alignment Project
 Larry Shi
Larry Shi