Week 1 - Intro & MLE
暴论
Bham的这门AI 2,除了中间的两节CV intro,借鉴了CS231n的课件,其他的可谓都是垃圾。我对这门课十分不满。
首先,我对于前5周的slides感到十分无语,甚至感到愤怒,因为其超级晦涩难懂,太数学了。这门课的内容明明就不需要讲的这么数学。教授明明知道台下的学生没学过概率论,没学过线代,可他一定要整一个Beamer,上面放一堆纯数公式,用精准无比但又难以令人理解的逻辑化语言进行旁批,这很酷吗?
其次,CV intro虽然讲的不错,但是课程安排问题很大。这两节课我听的很开心,因为我有基础,也听过一遍CS231n。这两节课基本就是把CS231n的课件拿过来,快速过了一遍。台下的学生基本上既没有数学功底,又没接触过AI,一上来就介绍框架,通用算法之类的。当我刚接触AI的时候,我完全不理解什么是框架,也认为算法和我这个新手没有关系。
最后是两节搜索。在我看来在2024年,AI里面讲搜索,我建议讲到A*就成了。一定要在AI课里面讲n皇后,回溯,剪枝,这是在干什么?莫名其妙的。我清楚地记得,在描述n皇后的问题约束时,x1,x2不能相等,下面都有学生问个不停,整堂课听下来就是进度慢,无语,不知所言。
我建议,这个课要是想偏数学,那就直接前三节课讲概率论和线代,后面直接Machine Learning就行了,讲到什么多重感知机就完事了;要么这课就纯导论,CV两节,NLP两节,AI4Sci两节,遗传进化算法等东西上几节就行了;要么就讲传统算法在AI中的运用。现在这种课程拼接方式,不伦不类,我认为大多数同学都会觉得很无语。
Maximum Likelihood
思想:我们进行一次采样,得出一个结果。我们认为,由于我们一次采样就采样到了这个结果,所以我们认为代表这个结果的概率密度就应当是最大的,所以我们求导=0就可以得到限制条件,从而得到想要的参数。
二项分布又称Bernoulli distribution
似然函数如下:
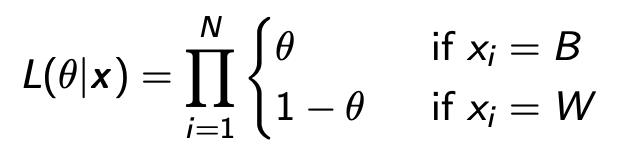
在一般情况下
- 如果X是离散的,那么就是所有情况f(x)的乘积
- 如果X是连续的,那么就是求f(x;θ)对x的边缘
根据极大似然的思想,可以得到估计结果:
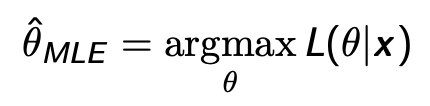
这个函数怎么求最大值?先对齐log再求导,因为不改变其单调性。求导后这个玩意叫cost function
Optimisation
优化流程:
- 建立模型
- 定下来问题类型
- 选择优化算法
Machine Learning就是一种优化问题
- 监督学习就是给定结果的标签
- 无监督学习就是不给y的标签
Gradient descent
懒得写了
\
 Larry Shi
Larry Shi