Week 3 Cooperation
阿克塞尔罗德的计算机锦标赛
著名的博弈论实验,他邀请来自不同学科的研究者提交计算机程序,以竞争“囚徒困境”博弈的最佳策略。 友好策略(Nice Strategies,粉色区域)
- 这些策略具有 合作性(不主动背叛),并且整体得分很高。
- “以牙还牙”(Tit for Tat)策略 由 Anatol Rapoport 提交,在比赛中表现最佳。
- 这些策略的共同特征:
- 从不先背叛(永远不会主动欺骗对方)
- 回报合作(如果对手合作,它们也会合作)
- 简单而有效(它们并不复杂,但表现优越) 得分情况:
- 这些策略得分都接近600,意味着它们在比赛中表现非常稳定,且能在合作中获得高分。
造王者(Kingmakers,黄色区域)
- 这些策略(Graaskamp 和 Downing)的特点是它们可能不会自己赢得比赛,但它们的策略会影响其他策略的排名。
- 它们的得分变化较大,表明它们可能采取了不稳定或更具攻击性的策略,影响了博弈的平衡。 得分情况:
- 这些策略的得分波动很大,比如 Downing 对不同策略的得分从202到625不等,表明它们对不同对手采取了不同的策略。
随机策略(Random)
- 最后一名(Random) 是完全随机的策略,得分最低(仅442分),因为随机策略不能形成稳定的合作,容易被其他策略剥削。
Axelrod的第二次实验
- 这次实验是对第一次比赛的后续测试,参赛者已经知道第一轮的结果。目标是测试改进的策略能否战胜之前的赢家(如 Tit-for-Tat)。
- 参赛者的程序被随机匹配,相互竞争。
- 比赛的回合次数是随机的,平均大约200轮。
- 原因:
- 这一设计使得策略无法依赖固定轮数(比如如果知道比赛是100轮,就可以在最后几轮背叛)。
- 逼近现实:现实世界中的合作往往没有明确的终点,所以策略应该适用于不确定的环境。 结果是Tit-for-Tat 仍然获胜。
- 原因:
Tit-for-Tat告诉我们什么?
- 要友善!(Be Nice!) - 先从合作开始。
- 要不容忍!(Be intolerant!) - 如果对方无故背叛,立即进行背叛——展现惩罚的意愿。
- 要宽容!(Be forgiving!) - 在对方背叛之后(惩罚一次后)重新合作。
Evolution of Cooperation(合作的演化)
内容解析
- 假设有一组智能体,每个都有3步记忆。
- 囚徒困境有4种可能的结果,因此有 4×4×4=64 4×4=64 种不同的历史状态。
- 一个策略可以被表示为64维向量,其中每个元素对应一个动作(合作或背叛)。
- 进化过程:
- 初始时,有20个个体,每个采用随机策略。
- 这些策略相互博弈多轮,计算平均得分。
- 淘汰最差的10个策略。
- 从前10个策略中交叉“繁殖”,生成新的策略。
- 重复该过程,模拟策略的进化。
结论
- 通过不断淘汰低效策略并让高得分策略“繁殖”,可以观察到合作策略的演化。
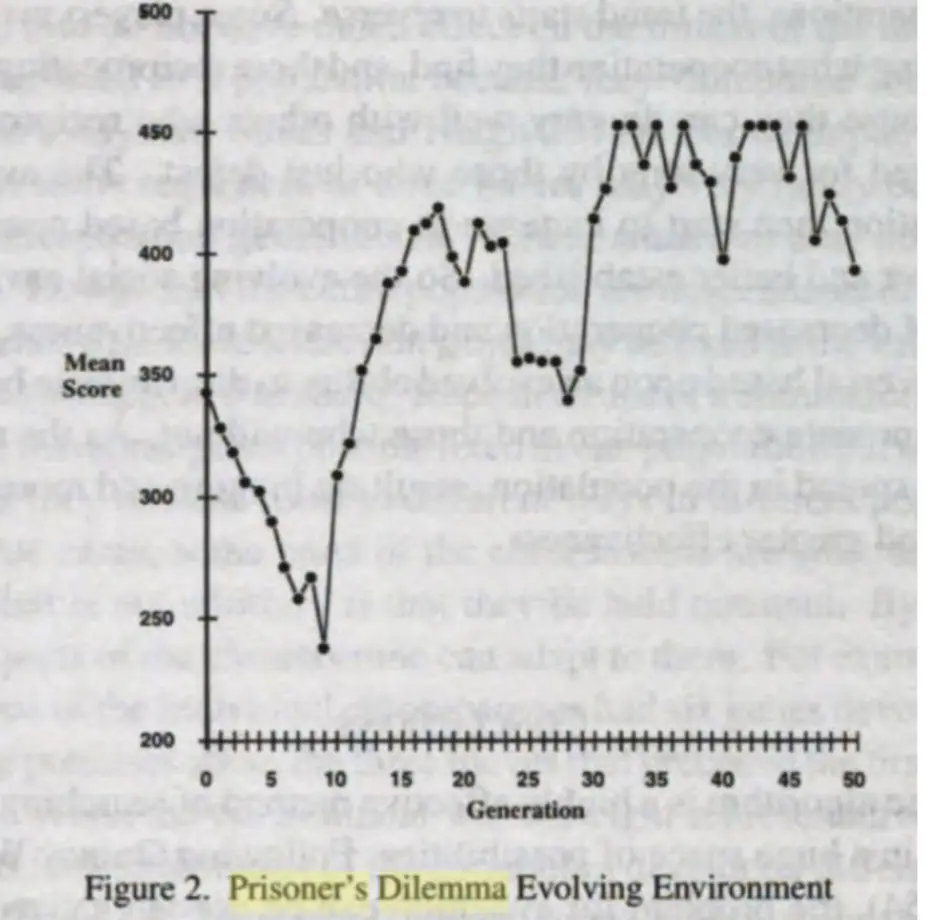
- 初始阶段(前10代):平均得分下降
- 可能由于最初的策略大多是随机的,导致合作较少,整体收益低。
- 也可能是许多欺骗性策略占优,使得个体间的信任崩溃,收益减少。
- 10代后:平均得分开始上升
- 说明合作策略开始出现,并在进化过程中逐渐占据主导。
- 由于合作可以提高长期收益,这些策略获得更高得分,并在选择过程中存活下来。
- 25代左右:得分短暂下降
- 可能是由于新的、较具欺骗性的策略进入种群,导致合作再次受到挑战。
- 但是这些策略可能无法长久存活,因为如果所有个体都开始背叛,整体收益会下降。
- 25代后:平均得分明显上升并趋于稳定
- 合作策略占据主导地位,群体整体得分上升,表明合作是长期博弈中的优胜策略。
- 这一趋势符合**“以牙还牙”(Tit-for-Tat)等合作策略的演化优势**。
Multi-agent Reinforcement Learning(多智能体强化学习)
内容解析
- 作为进化算法的替代方法,可以使用**强化学习(RL)**来学习合作策略。
- Sandholm 和 Crites(1996)研究
- 证明强化学习智能体可以学会合作。
- 当强化学习智能体与固定的“以牙还牙”(Tit-for-Tat, T4T)策略对战时,T4T会成为学习到的最优策略。
- 当强化学习智能体彼此对战时,结果更加复杂,说明博弈环境会影响学习到的策略。
结论
- 强化学习可以自动发现合作策略,但其表现取决于对手的行为模式。
Further Discoveries(进一步发现)
Win-Stay Lose-Shift(WSLS)策略
- Nowak & Sigmund (1993) 提出了 WSLS(赢留输换) 策略:
- 比以牙还牙更具鲁棒性,能更好地应对对手的意外背叛。
- 能够利用纯合作策略(如 ALLC:始终合作),在某些情况下表现更优。
如果在 Tit-for-Tat(TFT)对局中发生一次意外背叛(误操作),该策略会导致:
- D(背叛)→ C(合作) 交替模式,使双方都损失较多分数。
- 这可能导致长期的恶性循环,使得合作关系难以恢复。
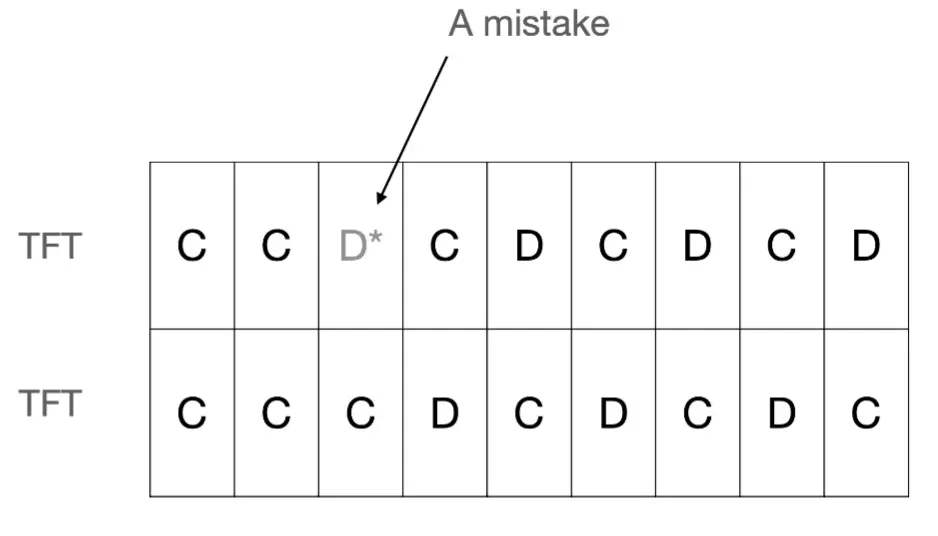
- WSLS 赢留输换策略:赢是指你单方面背叛或者双合作。
- 如果上轮获胜(双赢或成功欺骗),继续执行相同策略。
- 如果上轮失败(被欺骗或双方背叛),改变策略。
- 优势
- 能够恢复合作,不会陷入持续背叛的循环。
- 在对战 ALLC(始终合作)时表现更优,可以在适当时机利用对方。带星号是指错误的换了。

如果多轮囚徒困境可以说话
- 合作需要沟通
- 合作(Cooperation) 受信号传递(Signaling) 影响,例如语言、承诺或威胁。
- 在博弈论中,沟通可以帮助智能体建立信任、制定策略并维持合作。
- S# 算法
- 由 Crandall 等人提出,结合强化学习(Reinforcement Learning, RL) 和 信号机制。
- 能够与人类和其他算法合作,并达到与人类相当的合作水平。
- 适用于多种博弈环境
- S# 能够在两人重复随机博弈(例如囚徒困境)中实现高效合作。
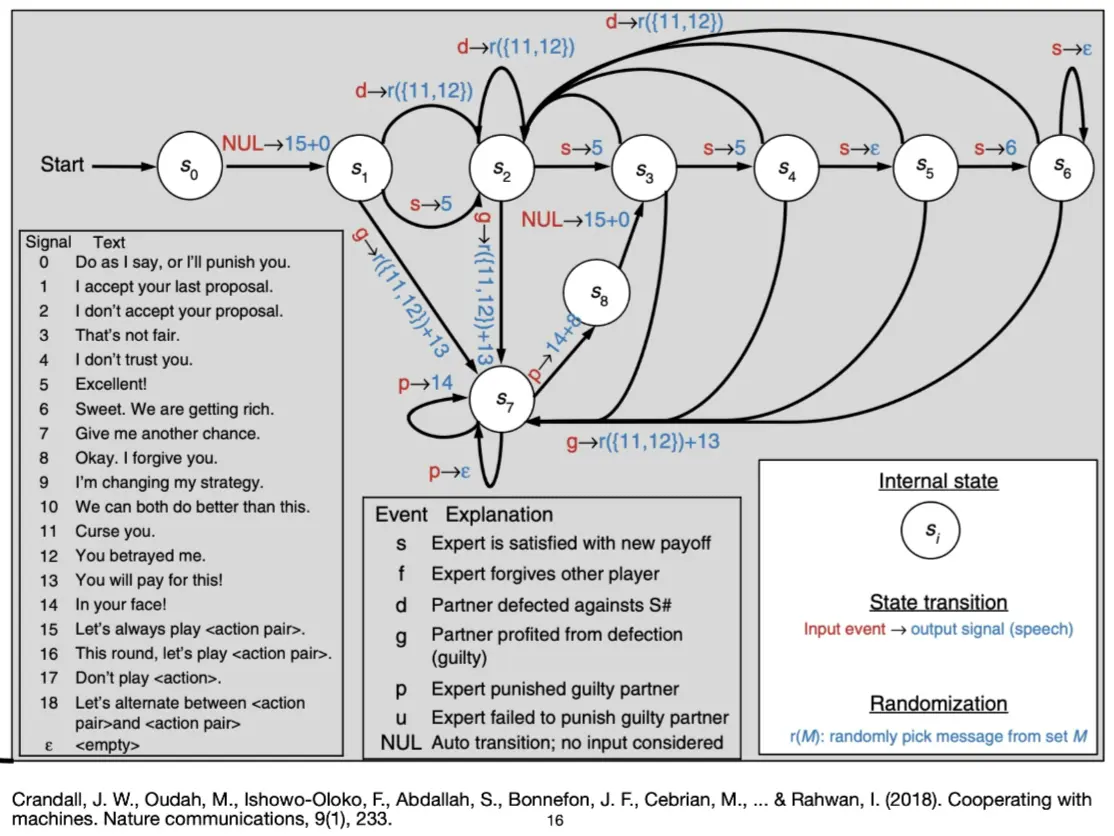
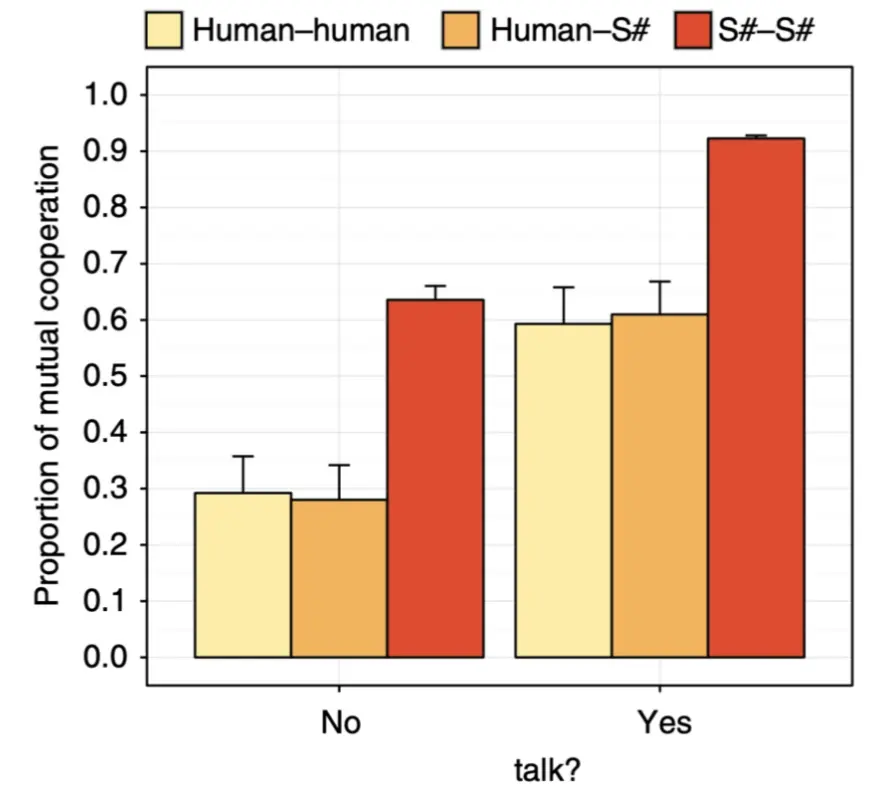
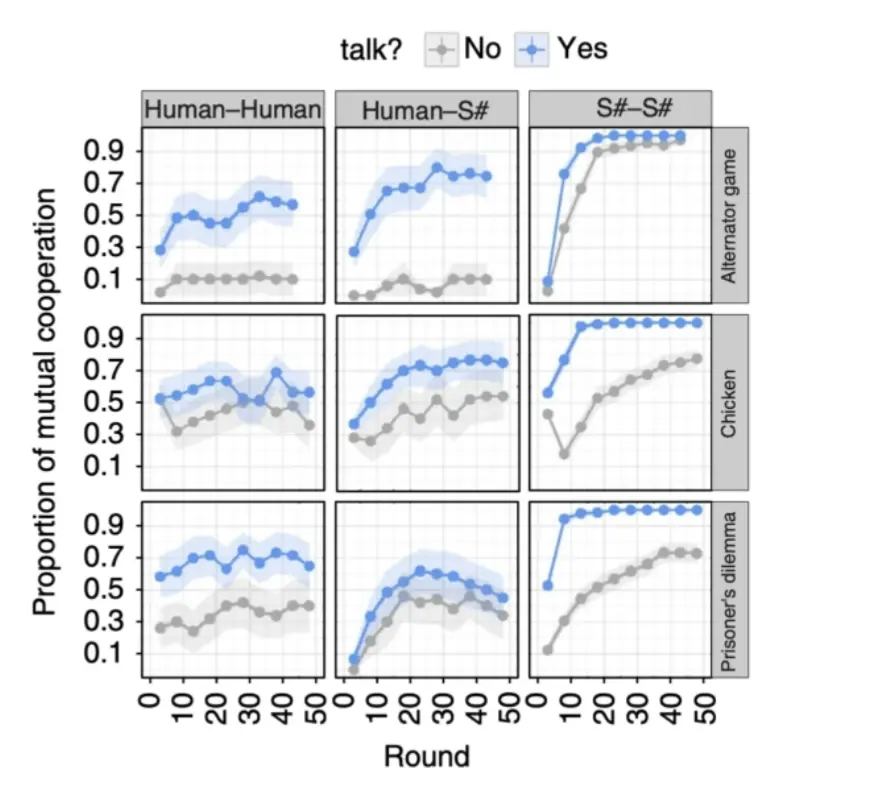
- S# 能够在两人重复随机博弈(例如囚徒困境)中实现高效合作。
设计一个IIS的在线购物平台
1️⃣ 信用评分 & 信誉推荐
- 计算信誉评分 (0-100),高信誉用户在市场上有更大优势。
- 信誉低的用户会被系统限制(如预付款要求、提高押金等)。
2️⃣ AI 信誉检测
- 采用机器学习模型检测欺诈模式,例如:
- 异常评分(短时间内大量负评)。
- 短时间创建大量虚假账户。
- 交易模式异常(某些账户专门给另一个账户打高分)。
3️⃣ 交易智能匹配
- AI 依据信誉评分匹配买家和卖家,优先推荐高信誉交易者进行匹配。
- 如果新用户信誉不够,系统可能会要求 更安全的交易方式(如托管支付)。
直接互惠(Direct Reciprocity)和间接互惠 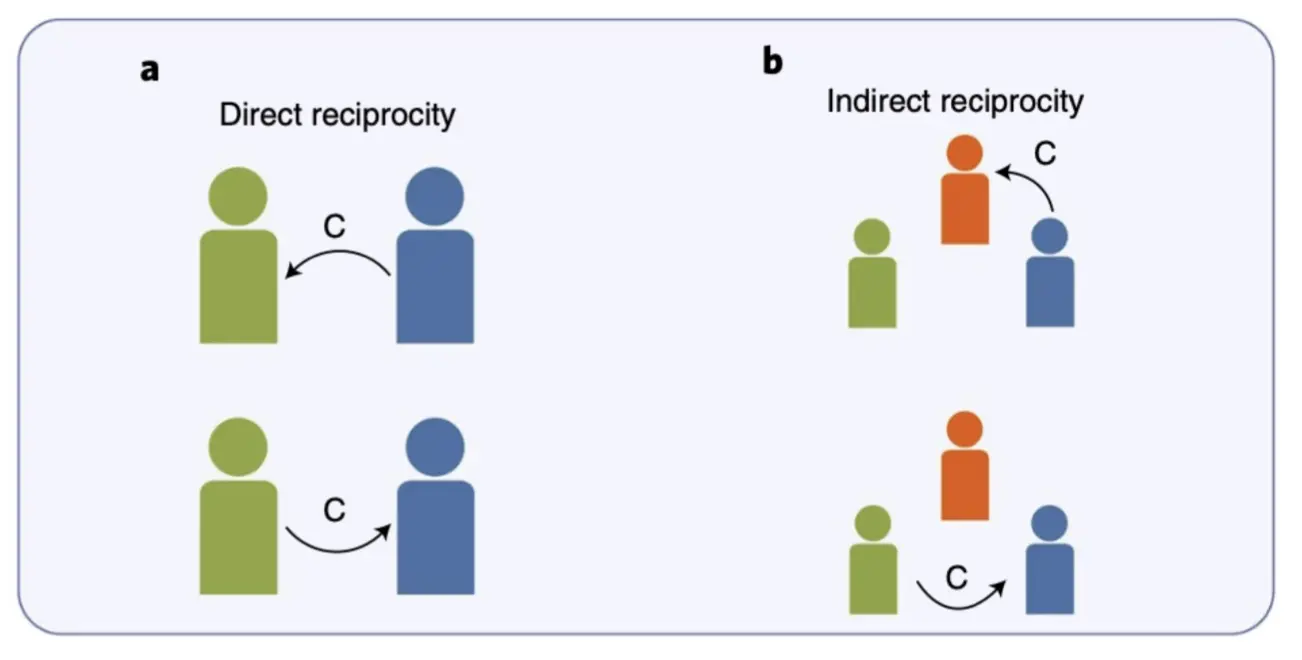 直接互惠:A 帮助 B,B 未来回报 A。 间接互惠:A 帮助 B,B 可能不会直接回报 A,但 C(第三方)会因为 A 的善行而帮助 A。
直接互惠:A 帮助 B,B 未来回报 A。 间接互惠:A 帮助 B,B 可能不会直接回报 A,但 C(第三方)会因为 A 的善行而帮助 A。
- 依赖于声誉(Reputation) 系统,第三方观察 A 的行为后决定是否合作。
声誉如何促进间接互惠? 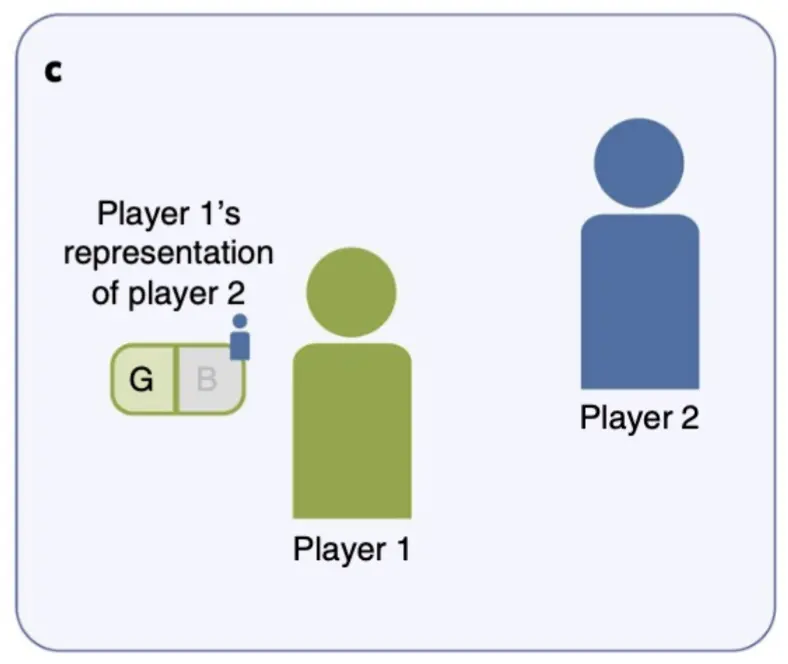
- 绿色玩家(Player 1)不会直接与蓝色玩家(Player 2)互动,但他有 Player 2 的声誉信息。
- 绿色玩家基于历史记录将 Player 2 归类为“好(G)”或“坏(B)”。
- 如果 Player 2 的声誉是 G(Good),Player 1 更有可能合作。
在线市场中的声誉
- 在线市场依赖声誉。
- 通过反馈建立声誉。
- 在线市场比传统市场更容易出现欺诈问题。
- 在线和传统市场的参与者以不同的方式进行沟通。
- 沟通模式是否对市场中的信任程度至关重要存在争议。
- 市场中信息传播方式的差异可能会不同程度地影响信任和合作意愿。
买家-卖家决策树
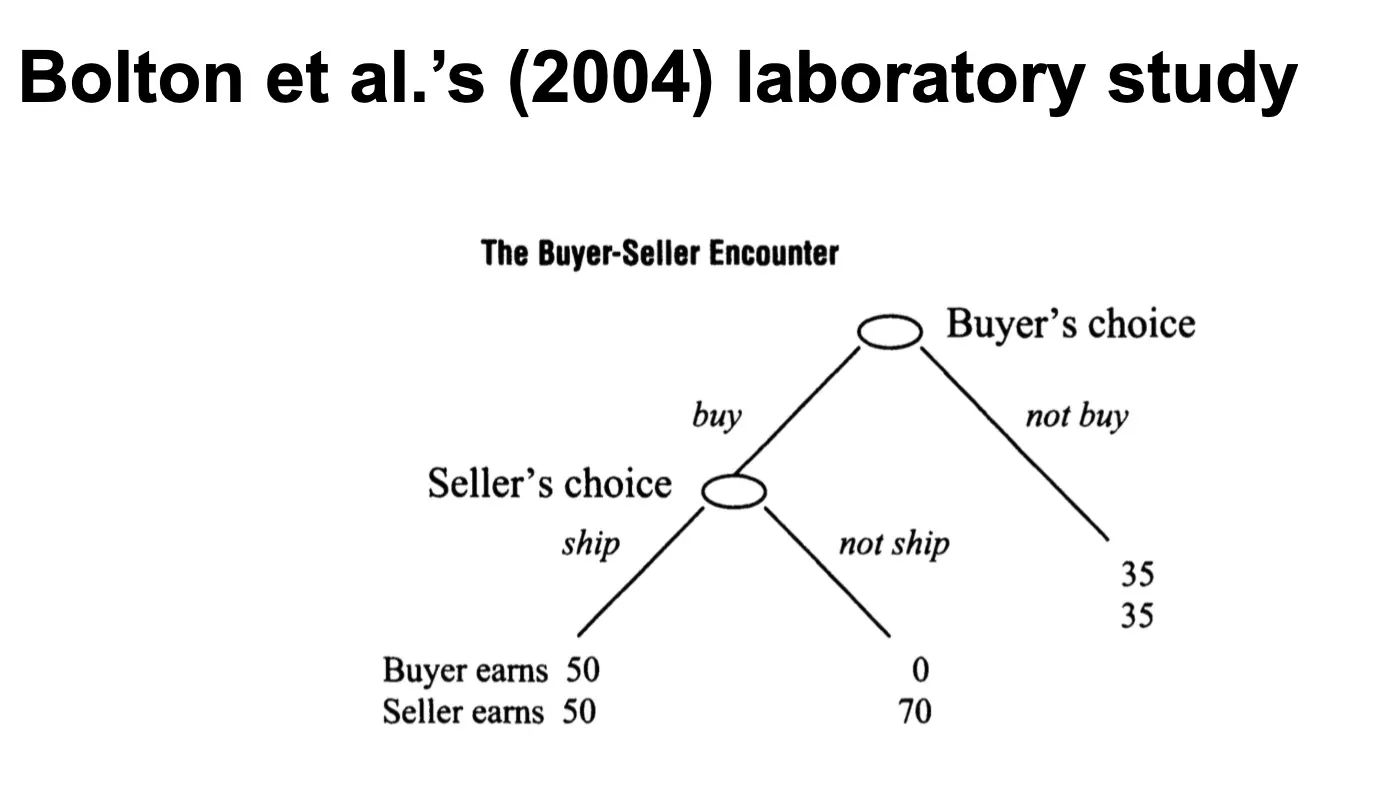 买家不买,那么买家本身有35块钱,卖家35块钱。 如果买家买了,商家发货了,买家拿到货物之后主观认为其价值为50,所以付了50,卖家也得到50 如果买家买了,卖家没发货,那么卖家把买家的钱拿了,变成70
买家不买,那么买家本身有35块钱,卖家35块钱。 如果买家买了,商家发货了,买家拿到货物之后主观认为其价值为50,所以付了50,卖家也得到50 如果买家买了,卖家没发货,那么卖家把买家的钱拿了,变成70
三种市场
陌生人市场(Stranger Market)
个体买家和卖家最多只交易一次,买家无法获得关于卖家交易历史的信息。 在这种市场中,道德风险(moral hazard)极大,因为卖家的行为不会影响未来潜在客户的决策,导致卖家可能存在欺诈的动机。
反馈市场(Feedback Market)
一个在线反馈系统会跟踪卖家在过往交易中的履约情况(如是否发货),并向潜在买家提供这些信息。 这类市场提供了间接互惠(Indirect Reciprocity)机制,使其更符合在线市场的特点,因为买家可以基于卖家的历史表现来决定是否交易。
伙伴市场(Partners Market)
买家和卖家会反复交易,在每一轮都会进行互动。 这种市场提供了直接互惠(Direct Reciprocity)机制,更类似于传统市场,因为长期合作关系可以促使卖家提供更好的服务,以维持客户忠诚度。
信任预测
如果“交易历史”是唯一重要的因素
- 假设买家只关心卖家的历史记录,而不在意自己是否与该卖家有过直接交易。
- 那么:
- 直接互惠(长期合作的买卖关系) 和 间接互惠(基于市场反馈的交易) 应该对市场表现有相同的影响。
- 也就是说,只要卖家有良好历史记录,买家就愿意交易,无论他们是否之前有过合作。
如果“个人交易经验”更重要
- 假设买家更信任自己与卖家的直接交易经验,而不是市场上的反馈信息。
- 那么:
- 直接互惠(长期合作的买卖关系) 会比 间接互惠(市场评价系统) 更有效。
- 也就是说,买家会更信任自己长期合作的卖家,而不是仅仅依赖市场上的评价系统。
真实实验结果
买卖交易决策树:
- 买家首先决定 “买”或“不买”。
- 如果买家选择“买”,卖家可以 选择“发货”或“不发货”:
- 发货:买家和卖家各获得 50 点。
- 不发货:买家获得 0 点,卖家获得 70 点。
- 如果买家选择 不买,买卖双方各获得 35 点。
- 最后一个点数一分钱,可以换成真钱 最后结果:
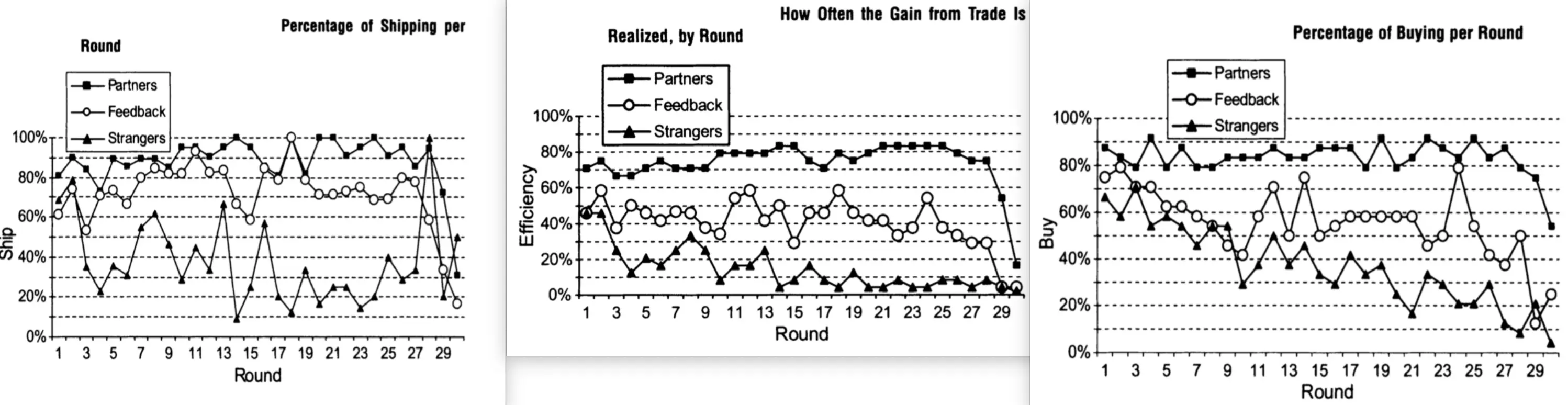 对于第一张图,发货比例图,可以看到,信任建立的难度影响了市场交易的诚信度。在固定买卖关系(Partner)中,卖家更倾向于发货,而在陌生市场(Strangers)中,卖家更容易欺骗买家。
对于第一张图,发货比例图,可以看到,信任建立的难度影响了市场交易的诚信度。在固定买卖关系(Partner)中,卖家更倾向于发货,而在陌生市场(Strangers)中,卖家更容易欺骗买家。
对于第二张图,交易效率,Partner 组效率最高,长期维持在 80% 以上,说明长期合作能促进市场效率。Feedback 组效率中等,但随时间波动下降,意味着反馈系统不能完全消除欺骗。Strangers 组效率最低,长期维持在 20%-40% 之间,甚至在最后几轮接近 0%。
第三张图,每轮买家选择购买的比例。在 Partner 组,买家对卖家更有信任,因此购买率保持高水平。Feedback 组 表明反馈机制在短期内有效,但随着卖家可能欺骗的情况增多,买家购买率下降。Strangers 组 由于交易不稳定,买家对卖家缺乏信任,因此购买率最低,甚至最终趋近于 0%。
通过买家卖家的例子,我们知道了合作的条件
- 理解其他人的激励和策略:了解对方的动机、利益和行为模式,才能做出更明智的决策,避免被骗或做出错误预判。
- 有互动的历史:长期的互动有助于建立信任和稳定的合作关系。
- 互惠(Reciprocity):愿意友善、原谅、并惩罚背叛者:以牙还牙
- 沟通(Communication):如可沟通的多轮囚徒困境。有效的沟通对于建立信任和合作至关重要。
- 通过个人经验获得的信任: 个人经历会影响合作意愿:过去的合作经历(无论正面还是负面)会影响个体对未来合作的预期
- 制度(Institutions):如陌生人市场,反馈市场和伙伴市场。社会结构(social structure) 能促进合作。社会规范(social norms)和法律体系(legal systems) 提供规则,帮助维护合作关系:社会规范:例如诚信、互助文化,使得合作成为一种社会认可的行为。法律体系:提供惩罚机制,防止欺诈行为,提高合作的可靠性。
总结(Summary)
- 智能交互系统需要与人类合作,同时促进人与机器混合群体之间的沟通。
- 合作可以促进更高效的互动,例如在半自动驾驶车辆中。
- 然而,合作是困难的,因为叛变(欺骗、不合作)可能带来短期利益。
- 博弈论(Game Theory) 提供了一个框架,可以用来预测人类和机器在何时会合作,何时会选择背叛,基于任务的激励结构。
- 机器是否合作取决于任务的激励结构,它们会基于成本收益分析做出决策。
- 模拟现实环境需要考虑的不仅仅是激励机制,还要包含沟通方式和社会规范。
- 正如本课程的其他讲座一样,我们只是展示了少数几个可能的合作案例……
Week 3 Human & AI Decision Making
介绍以下概念
- 期望值(Expected Value)
- 期望效用(Expected Utility)
- 递减收益(Diminishing Returns)
- 主观期望效用(Subjective Expected Utility)
- 偏见(Bias)
- 前景理论(Prospect Theory)
Expected Value 客观存在
期望值是客观存在的,然而,人们并不完全是根据期望来做选择的。
例子1:彩票
彩票规则1: 每个彩票5磅,但有1%的机会赢得1000磅 彩票规则2: 每个彩票10磅,每张彩票有50%的机会赢得6磅,40%的机会赢得8磅和10%的机会赢得50磅。 规则1的期望为 1000 x 0.01 = 10, 规则2的期望为 6 x 0.5 + 8 x 0.4 + 50 x 0.1 = 3 + 3.2 + 5 = 11.2。 按照价格差,规则1为10-5 = 5,而规则2为11.2-10 = 1.2,所以如果纯按照期望来看,你会选规则1.但是并不是所有人都会按照期望选。
例子2: 圣彼得堡悖论
玩家支付一定的入场费参与游戏,然后进行一系列的 掷硬币游戏。如果第一次扔,正面赢1磅,结束游戏,背面扔第二次。如果第二次扔,正面赢2磅,结束游戏,背面扔第三次。第三次,正面赢4磅,结束游戏,背面扔第四次... 每后一次的奖励是前一次的double。 所以入场费多少你就应该参加游戏? 如果按照期望计算,是这样的:
所以按照期望来看,你的期望收益无穷,所以你真的就应该付多少都参加游戏?其实人们不是这样的。
那么如何用数学建模人的选择依据?
Expected Utility 部分主观
丹尼尔·伯努利(Daniel Bernoulli) 在 18 世纪提出了解决方案:财富的效用(幸福感)不是线性增长的,而是递减的。人们并不关注金钱的绝对值,而是关注金钱带来的幸福感。赢得**£1 和 £2 之间的幸福感差异大**,但赢得 £1,000,000 和 £1,000,001 的幸福感差异小。所以人的效用应当用 U(x) = log(x)或者指数来衡量。
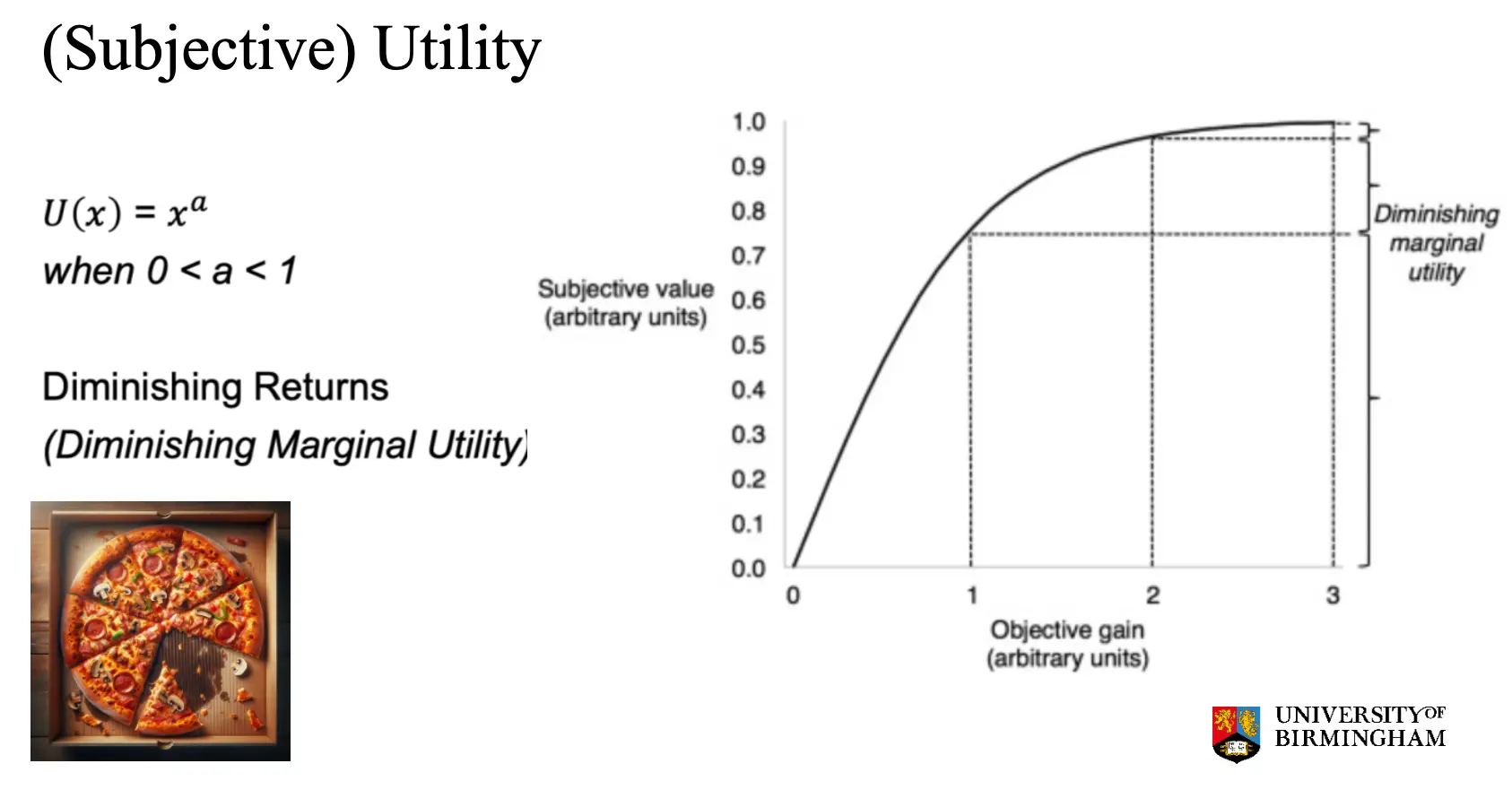 这里也可以看到Diminishing marginal utility, 即为边际效用递减。所以对应人真正的效用,应当是这样的:
这里也可以看到Diminishing marginal utility, 即为边际效用递减。所以对应人真正的效用,应当是这样的:
但其实EU还是有点高看人,因为,人其实是无法客观判断一个事情的概率的,所以出现了Subjective Expected Utility, SEU
Subjective Expected Utility 完全主观
si是决策者对事件 iii 发生概率的主观判断(subjective probability),不同的人对同一事件的概率估计可能不同。所以这里概率和效用均为主观判断。 如何把这些内容理论化?
萨维奇Axioms 期望效用理论(Expected Utility Theory, EUT)
这些公理用于描述理性决策者在面对不确定性时应遵循的基本原则。
- 完备性(Completeness),个体一定能比较A和B中,更喜欢A还是B还是A和B一样。
- 传递性(Transitivity),如果个体偏好 A 胜过 B,并且偏好 B 胜过 C,那么他们必须偏好 A 胜过 C。
- 独立性(Independence)个体的偏好不应受到无关选项的影响。具体来说,如果个体偏好 A > B,而 C 是一个与 A 和 B 无关的结果,那么个体应该同样偏好 “A 与 C 的组合” 胜过 “B 与 C 的组合”,只要 A 和 B 的概率保持不变。
- 连续性(Continuity),如果 A > B > C,那么应该存在一个概率 p,使得个体对 B 的偏好等同于 A 和 C 之间的某种加权平均。
- 单调性(Monotonicity),如果A 是由 B 通过增加更好的结果而获得的,那么 A 应该被偏好于 B。
- 确定性原则(Sure-Thing Principle),如果个体在一个上下文中更喜欢 A 而不是 B,那么在另一个上下文中,他们也应该做出相同的选择,即使概率不同。
Allais悖论:违反期望效用理论
这显示人们在不同概率结构下的偏好是不一致的。
问题 1(确定性效应)
- 赌注 A:
- 33% 的概率赢得 £2500
- 66% 的概率赢得 £2400
- 1% 的概率什么都没有(£0)
- 赌注 B:
- 100% 的概率赢得 £2400(确定的收益) 实验结果:大多数人选择 B(确定性 £2400),而不是 A(尽管 A 的期望收益更高)。
解释:人们更倾向于规避风险,即使期望收益更高,他们仍然更喜欢确定的收益(确定性效应)。
- 100% 的概率赢得 £2400(确定的收益) 实验结果:大多数人选择 B(确定性 £2400),而不是 A(尽管 A 的期望收益更高)。
问题 2(相同期望值但不同概率结构)
- 赌注 C EV=825:
- 33% 的概率赢得 £2500
- 67% 的概率什么都没有(£0)
- 赌注 D EV=816 :
- 34% 的概率赢得 £2400
- 66% 的概率什么都没有(£0) 实验结果:在这个选择中,大多数人更愿意选择 C(赌更高金额的 £2500) 而不是 D。
解释:在没有确定性选项的情况下,人们倾向于接受更高的潜在回报,而在前一个问题中他们更倾向于规避风险。
Allais悖论核心:期望效用理论(EUT)假设人们的偏好是一致的,但 Allais 悖论 说明人们的偏好在不同的概率结构下是不一致的。这表明人们在面对确定性和风险时,会改变自己的决策方式。
面对确定性和风险的人类偏好(Human Preferences)
人们更倾向于接受确定的收益,即使期望值较低。
你会选择:
- 80% 的概率赢得 £100,20% 的概率赢得 £10(期望值 = £82)
- 保证获得 £80(确定性收益) 这个其实都不存在效用了,因为82大于80是铁打的。但实验结果:大多数人会选择 £80 确定性收益,即使第一项的期望收益更高。这反映了人类的风险规避(Risk Aversion),即人们更愿意接受低但确定的收益,而不是更高但有风险的收益。
参考点效应(Point of Reference Effect)
人们的幸福感取决于财富的变化,而不仅仅是最终财富。
Jack 和 Jill 目前都拥有 £5M:
- Jack 昨天只有 £1M → 他的财富增加了 £4M。
- Jill 昨天有 £9M → 她的财富减少了 £4M。 显然Jack更幸福,尽管他们的财富是相同的。这反映了参考点效应(Reference Point Effect),即人们的决策受到相对变化的影响,而不仅仅是绝对财富。
损失规避(Loss Aversion)
人们对损失的痛苦大于等额收益的快乐,这导致人们规避风险。
确定获得 £2M vs. 50% 的概率赢得 £4M,50% 可能什么都没有:
- 大多数人会选择 确定的 £2M,尽管期望值是相同的(£2M)。
- 说明人们更害怕损失,而不是追求更高收益。
应用
禀赋效应(Endowment Effect)
人们对自己已经拥有的物品赋予更高的价值,而不愿意放弃它,即使交易对自己有利。 研究人员给一半的参与者一个马克杯,另一半参与者没有。他们要求有马克杯的人给杯子定价,并询问没有马克杯的人愿意支付多少购买。结果:
- 拥有杯子的人 平均希望 $7 才愿意卖出。
- 没有杯子的人 只愿意支付 $3-$4 购买同样的杯子。 这说明人们对自己拥有的东西赋予了更高的价值,即使他们之前并不特别想要它。 一旦拥有某样东西,失去它的痛苦远大于获得它的快乐,这与损失规避(Loss Aversion) 有关。
框架效应(Framing Effect)
人们对相同信息的感知和决策会因其表述方式不同而产生偏差。
- 方案 A:「这个酸奶含 20% 脂肪」消极框架(Negative Framing) 让产品看起来不够健康。
- 方案 B:「这个酸奶 80% 无脂肪」积极框架(Positive Framing)让产品看起来更健康。 实验结果是,大多数人选80%无脂肪。即使它和「20% 含脂肪」完全一样。
前景理论(Prospect Theory)
解释了人们在不确定性下如何做决策,以及为什么他们的选择会偏离传统经济学中的理性模型,即为期望效用理论(Expected Utility Theory, EUT)。 核心观点:
- 人们不会以绝对价值衡量收益和损失,而是相对于一个参考点(Reference Point)来评估。
- 损失规避(Loss Aversion):人们对损失的痛苦程度远大于对等额收益的快乐程度。
- 非线性决策:人们对小概率事件和大概率事件的权重认知存在偏差。
四个关键创新:
- Pre-decision editing(决策前编辑)
- 人们在做决策前,会筛选和简化选项,删除一些明显不合适的选择,以减少认知负担。
- 例如:面对复杂的投资决策,人们可能只关注几个关键因素,而不是所有信息。
- Reference Dependence(参考点依赖)
- 人们的决策不是基于绝对收益,而是基于一个参考点(比如当前财富水平、过去经验等)。
- Gains versus Losses(收益 vs. 损失)
- 人们对损失的敏感度远高于对等量收益的敏感度。
- Loss Aversion(损失规避)
- 损失比相同的收益更令人痛苦,通常损失的痛苦是等额收益带来快乐的 2 倍。

- 损失比相同的收益更令人痛苦,通常损失的痛苦是等额收益带来快乐的 2 倍。
前景价值函数(Value Function)
X 轴(横轴):收益与损失。Y 轴(纵轴):心理价值(Perceived Value) 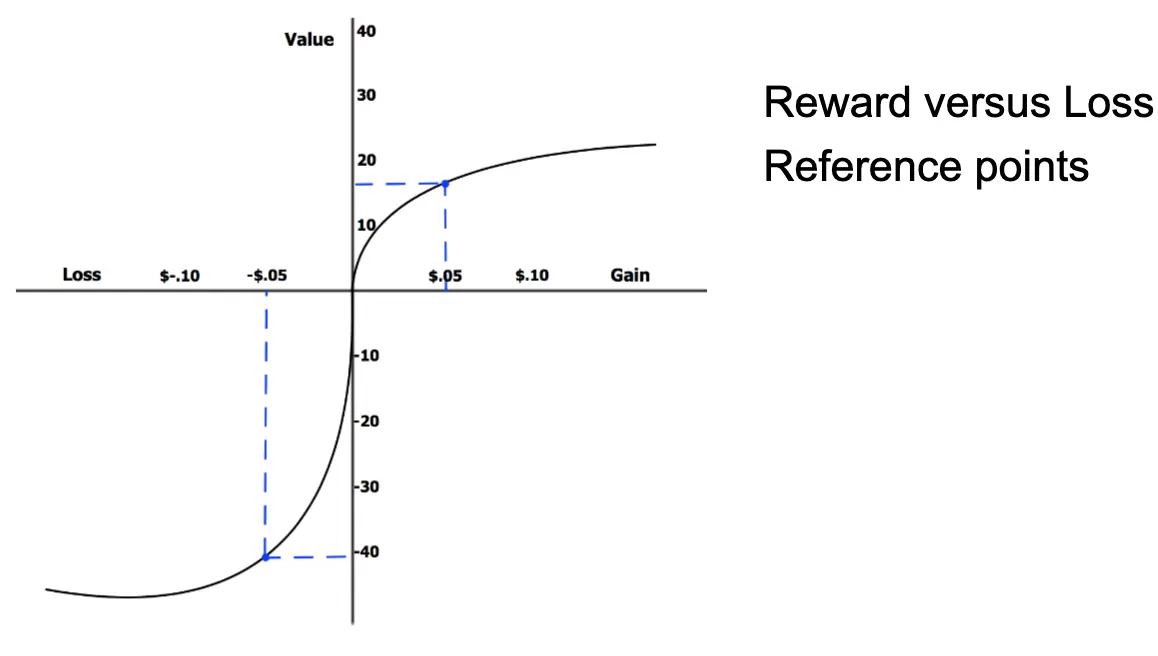 现实应用:
现实应用:
(1) 投资 & 行为金融学
- 投资者更不愿卖掉亏损的股票,因为卖掉股票会将损失变为现实,带来更大的痛苦。
- 股市恐慌性抛售:当市场下跌时,投资者的恐慌情绪比市场上涨时的乐观情绪更强烈。
(2) 营销与定价策略
- 免费试用(如 Netflix、Amazon Prime)利用禀赋效应和损失规避,让用户在试用后更难放弃订阅。
- 折扣 vs. 赠品:相比 10% 折扣,消费者更倾向于接受「买一送一」,因为「失去」 10% 价格折扣比「获得」免费商品的影响更大。
(3) 保险行业
- 保险公司利用损失规避心理,让客户愿意支付额外费用来避免潜在的大额损失。
- 例如,人们更愿意购买手机保险,即使手机损坏的概率很低。
(4) 赌场 & 赌博心理
- 赌场利用前景理论,设计「小赢大输」的策略,让赌徒继续下注:
- 小额的赢利(即使是 £1)会带来正向刺激,使赌徒继续玩。
- 但他们对损失的恐惧更大,因此容易加倍投入,希望弥补损失。
四重模式(Fourfold Pattern)
四重模式(Fourfold Pattern)是前景理论(Prospect Theory) 的核心扩展,它表明:
- 人们在不同的概率(高 vs. 低)和结果(收益 vs. 损失)下,展现出不同的风险偏好。
- “风险规避(Risk Aversion)” 和 “风险偏好(Risk Seeking)” 并不总是一致,而是受概率的影响。
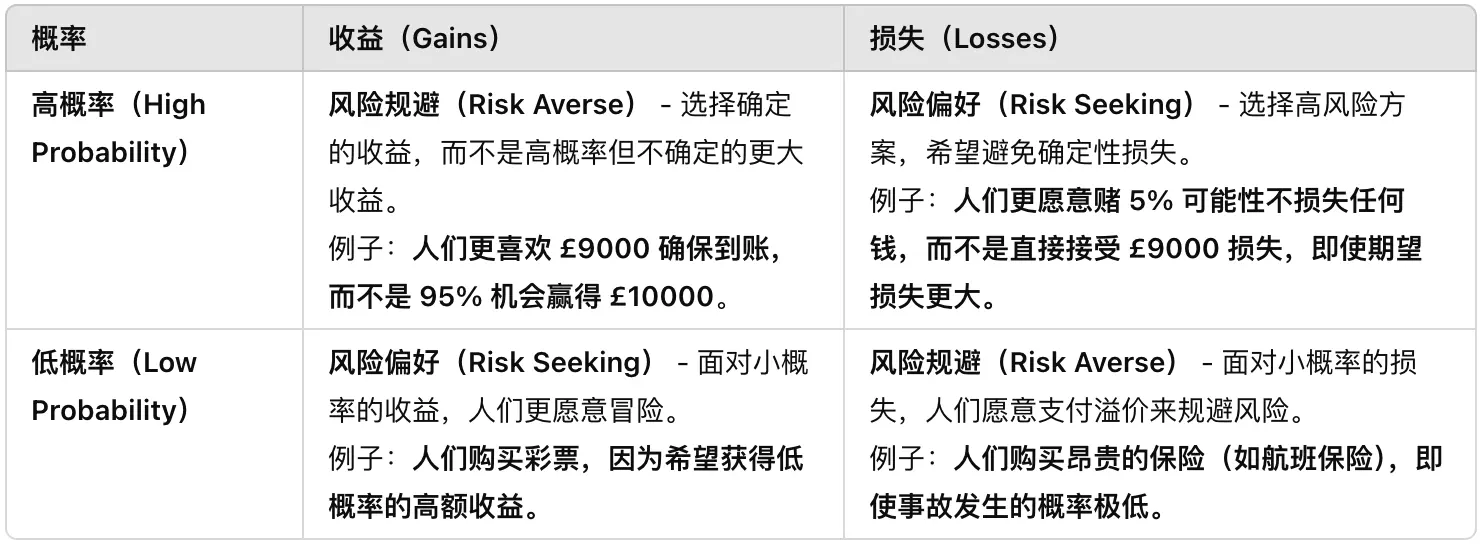 人们的风险态度并不恒定,而是取决于收益 vs. 损失和高概率 vs. 低概率。
人们的风险态度并不恒定,而是取决于收益 vs. 损失和高概率 vs. 低概率。
- 确定性效应(Certainty Effect):高概率时,人们更倾向于规避风险。(第一第二象限)
- 可能性效应(Possibility Effect):低概率时,人们更倾向于追逐机会。(第三象限)
- 损失厌恶(Loss Aversion) 解释了为什么人们愿意购买昂贵保险,即使风险极低。(第四象限)
Bias
人不是数学概念上的理性人。如果想要AI帮我们做决策,需要考虑到人的Bias。
 Larry Shi
Larry Shi