Week 1 Intro & ResponsibleAI
字数
1300 字
阅读时间
6 分钟
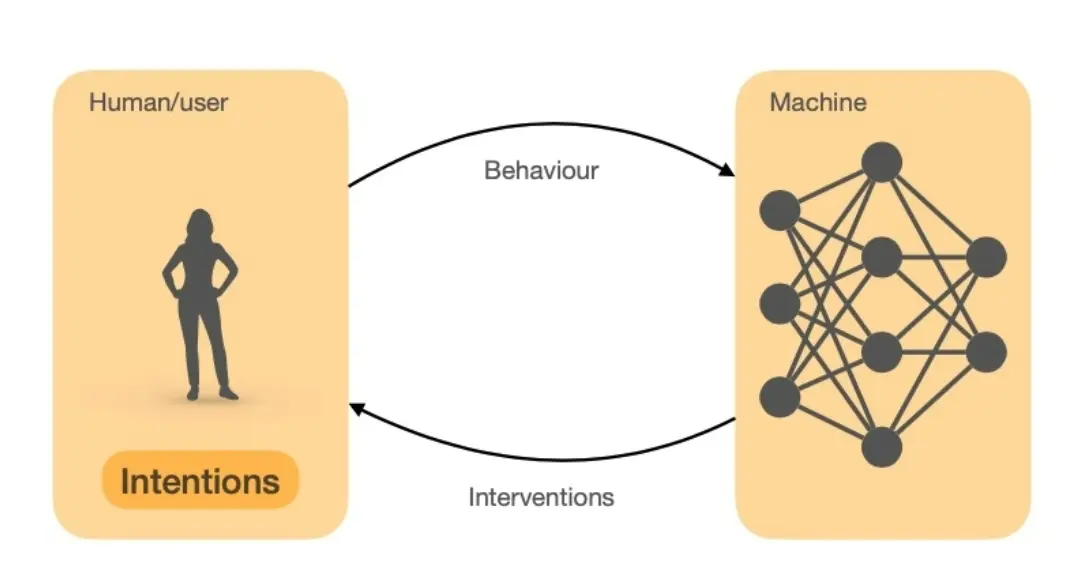

1. 需要与人类合作或协作(That must cooperate or collaborate with humans.)
- 智能交互系统 不能独立存在,而是要能够与人类用户进行交互,帮助他们完成任务或提供有价值的信息。
2. 这种合作需要 交互(interaction)和智能(intelligence)
- 交互(Interaction):系统应该能够与用户进行多层次的交互,比如响应指令、提供反馈、进行对话等。
- 智能(Intelligence):系统应该具备 学习、推理、预测、决策 等能力,使其能更有效地辅助用户。
3. 交互可以发生在多个时间尺度(That interaction can occur on multiple time scales)
- 感知-行动(Perception-Action):系统可以实时响应用户输入(如语音助手、手势控制)。
- 对话交互(Conversational):交互可以是短期的,例如人与聊天机器人之间的对话。
- 决策(Decision):系统可能涉及更长时间尺度的推理,例如 个性化推荐 或 长期策略优化。
4. 智能(Intelligence)是指利用可用数据进行学习和理性决策的能力
- 这里的 智能 体现在:
- 学习(Learning):从用户数据、环境反馈中学习模式和偏好。
- 理性决策(Rational Choice):基于学习结果做出符合目标的决策,而不是随机响应。
5. 智能需要使用预测性、解释性和上下文一致的模型
- 预测性(Predictive):模型需要能够预测 用户行为,如推荐系统预测用户喜好。
- 解释性(Explanatory):系统的决策需要可解释,例如提供推荐的理由,以提高用户信任度。
- 一致性(Consistent Across Contexts):智能系统在不同场景下(如 不同设备、环境、任务)仍然能保持稳定表现。
6. 智能交互系统需要通过行为推断(Inferring)用户的偏好和意图
- 推断(Inferring):系统不能只是被动地等待指令,而是要主动推测 用户的需求和意图。
- 从行为中学习(Learning from Behaviour):通过分析用户的鼠标点击、浏览记录、语音输入、眼动轨迹等,系统可以理解用户的需求并进行优化。
Responsible AI
Bias
LLM从text中学习到含义,依赖于大规模文本数据进行训练,因此它们会反映和学习这些数据的结构、模式和隐藏的偏见。
- 许多文本数据会编码社会文化规范,比如性别歧视,社会阶层歧视,种族偏见等等。
- 话语主体可能被一部分人占领,某些观点和信息被过度代表,而其他观点被低估或忽视。
例子:德州奥斯汀以前用Ai筛选PhD申请,但由于其有bias,最终被放弃。
如何de-bias?
Hallucinations
LLM是有幻觉的。福布斯新闻曾经报道,一名律师 在诉讼中使用 ChatGPT 来准备法律文件。ChatGPT 编造了不存在的法庭案例,律师没有核实,直接提交到了法庭。
如何去幻觉?可以用RAG。 让 LLM 结合 传统的信息检索技术(如数据库、文档库、知识图谱),确保生成的文本基于真实的外部信息。
Intellectual Property
- Jane Friedman 发现 Amazon 上有多本署名她名字的书籍,但她本人从未写过这些书。
- 这些书可能是由 AI 生成,并冒用了她的名字,企图利用她的声誉进行销售。
- 这标志着 AI 生成内容被用于身份盗窃和知识产权侵权的新案例。
Adversarial Attacks
大多数LLM都通过以下的手段来规避坏的行为:
- RLHF
- 内容过滤 然而,有一些人可以用prompt来让llm jailbreak
- 用户利用复杂的文本模式(如特殊符号、混淆句子结构)绕过 LLM 的安全检测,使其提供 如何制造炸弹的详细指南。 黑客和ai开发者在进行军备竞赛,黑客不断绕过LLM的安全机制,利用ai生成有害信息,而ai开发者需要持续改进安全性。
如何做得更好?
审计 透明设计 重新思考溯源、知识和智能的问题 水印 新的内容商业模式 - 谁能拥有你的数据? 让 内容创作者和出版商 参与到 AI 生态系统中,而不是被 AI 替代 用户教育
 Larry Shi
Larry Shi